Table of Contents
- Lista esercizi svolti
- Verifica delle ipotesi – binomiale
- Verifica delle ipotesi con 1 campione – ipotesi sulla media e test z e t
- Verifica delle ipotesi con 2 campioni indipendenti- ipotesi su media e test z / t
- Verifica ipotesi su 2 campioni dipendenti (media e varianza)
- Verifica delle ipotesi con χ²
- Verifica delle ipotesi su R di Pearson
- Verifica delle ipotesi con rs di Spearman
- Il coefficiente di correlazione tra variabili dicotomiche rphi
- Verifica delle ipotesi sul coefficiente di regressione lineare
Lista esercizi svolti
a partire da una serie di punteggi si calcoli le frequenze, frequenze percentuali, suddivisioni in classi, rappresentazione grafica (esempio istogramma)
a partire da una serie di punteggi si calcoli la moda, mediana, media, varianza, deviazione standard
calcolo dei punti z, t , stanine, sten, percentili
Verifica delle ipotesi nel caso di un campione
Verifica delle ipotesi nel caso di 2 campioni dipendenti e indipendenti
verifica delle ipotesi mediante test binomiale (aggiungere la parte dove parla dei dati tabulati)
verifica delle ipotesi mediante il test chi quadrato
verifica delle ipotesi sulla varianza (test f)
verifica delle ipotesi su r di Pearson
verifica delle ipotesi su rs di Spearman
verifica delle ipotesi su regressione lineare
Verifica delle ipotesi – binomiale
Andiamo a verificare le ipotesi di un campione in cui abbiamo misurato una variabile dipendente di tipo dicotomico. Nel mio test si sono verifica k eventi favorevoli, e poi ho restanti n-k eventi contrari.
Il test statistico che tulizzeremo è il test della binomiale, che ci permette di associare una probabilità all’evento k.
- pk : probabilità di k
- qn−k : probabilità che k non si verifichi
Procedura
1) Scelta del test statistico: In questo caso ci troviamo di fronte a una distribuzione di tipo binomiale, e quindi la nostra verifica sarà confrontare la nostra distribuzione campionaria con la distribuzione teroica di probabilità della binomiale.
2) Definizione dell’ipotesi:
- H₀: p=x (solitamente vale 0.5 ovvero 50%)
- H₁: (bidirezionale) oppure p>x oppure p<x (monodirezionale)
3) Fissare il livello di significatività α: si va a delineare la regione di rifiuto all’interno della nostra distribuzione secondo α (valore comune 0.05), e secondo H₁ (a seconda se è monodirezionale o bidirezionale)
4) Associare una probabilità ad H₀: p(H₀) Questo viene fatto con il test della binomiale. Si calcola la probabilità associata all’ipotesi nulla sommando tutte le p, per k che tende a n (k compreso). SI usa la formula precedente per calcolare p(k).
5) Decisioni su H₀ (⇒ H₁): si confronta p(H₀) con α.
- p(H₀) > α ⇒ Si accetta H₀ ⇒ è vera l’ipotesi nulla
- p(H₀) < α ⇒ Si rifiuta H₀ ⇒ Si accetta H₁ ⇒ è vera l’ipotesi alternativa
Verifica delle ipotesi con 1 campione – ipotesi sulla media e test z e t
Campione con n > 30, μ e σ noti
Nel caso di un campione
- con una numerosità campionaria n > 30
- conosciamo la media e la deviazione standard (μ e σ NOTI) della popolazione,
- abbiamo una variabile metrica di cui l’indicatore di tendenza centrale è la media
possiamo fare riferimento alla distribuzione campionaria delle medie.
Procedura
1) Scelta del test statistico:
Si calcola z facendo riferimento alla dCM
2) Definizione dell’ipotesi:
- H₀: μₘ = μ (media campione = media popolazione)
- H₁: μₘ ≠ μ (bidirezionale), oppure μₘ > μ oppure μₘ < μ (monodirezionale)
3) Fissare il livello di significatività α:
Si delinea la regione di rifiuto secondo α e H₁ (monodirezionale o bidirezionale) trovando uno zcritico sulla Tavola. Per esempio se α = .05 ⇒ l’area tra 0 e zcritico è .4500. Vado a vedere sulle tavole la distribuzione normale standard e vedo quale z da l’area in oggetto, nell’esempio .4500
4) Associare una probabilità ad H₀:
Si calcola la probabilità di H₀, ovvero z, standardizzando la media
M = media campione, μₘ media popolazione
5) Decisione su H₀ (⇒ H₁)
Si confronta lo z (stimato nel punto 4) e zcritico (fornito dalle tavole)
- se | z | < | zcritico| ⇒ p > α (probabilità associata ad H0 è minore di alpha) allora Si accetta H₀ ⇒ è vera l’ipotesi nulla
- |z| > |zcritico| ⇒ p < α ⇒ Si rifiuta H₀ ⇒ Si accetta H₁ ⇒ è vera l’ipotesi alternativa
Se invece non disponessi della σ deviazione standard della popolazione questa me la devo calcolare a partire dalla σ del campione.
con S deviazione standard del campione
Campione con n < 30, σ non noto
Non conosciamo la deviazione standard σ della popolazione, e abbiamo una vaiabile metrica (possiamo usare la media).
In questo caso possiamo sempre usare la distribuzione campionaria delle medie però dobbiamo confrontarla con distribuzione di probabilità della t
Procedura
1 Scelta del test statistico (di significatività): Si calcola t facendo riferimento alla dCM (distribuzione campionaria della media)
2 Definizione dell’ipotesi: uguale a n < 30
3 Fissare il livello di significatività α e calcolare i gradi di libertà:
Per individuare la regione di riuto devo avere
- a (alpha)
- gdl = n -1 (gradi di libertà)
- H1 (mono / bi direzionale)
trovando così tcritico sulla tavola
4 Associare una probabilità ad H₀: Si associa una probabilità ad H₀ calcolando t:
5 Decisione su H₀ (⇒ H₁)
- |t| < |tcritico| ⇒ p > α ⇒ Si accetta H₀ ⇒ è verosimile l’ipotesi nulla
- |t| > |tcritico| ⇒ p < α ⇒ Si rifiuta H₀ ⇒ Si accetta H₁ ⇒ è plausibile l’ipotesi alternativa
Verifica delle ipotesi con 2 campioni indipendenti- ipotesi su media e test z / t
Ho 2 campioni indipendenti, uno sottoposto a trattamento (gruppo sperimentale) e uno no (gruppo di controllo). Oppure potremmo avere due gruppi indipendenti sottoposti a trattamento, ma questo trattamento è diverso.
Campioni con n > 30
Quando ho noti i seguenti dati
- POPOLAZIONI CON σ NOTA
- 2 CAMPIONI INDIPENDENTI n > 30
- Abbiamo una variabile metrica (possiamo usare le medie)
si ricorre all’utilizzo della distribuzione campionaria della differenza tra medie, e il confronto verrà fatto (verifica dell’ipotesi) con la distribuzione di probabilità normale.
Procedura
1) Scelta del test statistico: Si calcola z facendo riferimento alla dCDM
2) Definzione dell’ipotesi: Il confronto è tra le due popolazioni di riferimento
- H₀: μ₁ = μ₂ (μ₁ – μ₂ = 0) la media tra le due popolazioni ci aspettiamo siano uguali
- H₁: μ₁ ≠ μ₂ (bidirezionale) le due medie sono diverse, oppure se monodirezionale possiamo affermare che μ₁ > μ₂, oppure μ₁ < μ₂
3) Fissare il livello di significatività α: Si delinea la regione di rifiuto secondo α e H₁ (mono/bidirezionale) trovando uno zcritico sulla Tavola della distribuzione normale. (come nel caso di un campione). Se
- monodirezionale α rimane α. Quindi vado a vedere quale valore z da come area 1-α
- bidirezionale α diventa α/2 e z è dato dall’area sotto (1-α)/2
calcolato il valore vado a vedere sulla tavola della normale quale valore da l’area calcolata.
4) Associare una probabilità ad H₀: Si associa una probabilità ad H₀ calcolando z
con
5) Decisione su H₀ (⇒ H₁): facciamo Il confronto avviene tra z e zcritico
- Se | z | > | zcritico | = p < α ⇒ Si rifiuta H₀ ⇒ Si accetta H₁ ⇒ è vera l’ipotesi alternativa
- Se | z | < | zcritico | = p > α ⇒ Si accetta H₀ ⇒ è vera l’ipotesi nulla
Quindi se ci troviamo nella seguente condizione
- POPOLAZIONE CON σ IGNOTA
La formula per il calcolo di z diventa la seguente
dove si utilizzano solo i dati dei campioni, e con
Campioni con n < 30
Quando sono in questa situazione
- POPOLAZIONI CON σ NON NOTE
- VARIABILE INDIPENDENTE DICOTOMICA
- VARIABILE DIPENDENTE METRICA (possiamo usare le MEDIE)
possiamo usare la dCDM e fare il confronto con la distribuzione di probabilità t (test t di differenza fra medie).
Procedura
1 Scelta del test statistico (di significatività) Si calcola t facendo riferimento alla dCDM
2. Definizione delle ipotesi: Come prima il confronto è tra le due popolazioni di riferimento
- H₀: μ₁ = μ₂ (μ₁ – μ₂ = 0)
- H₁: μ₁ ≠ μ₂ (bidirezionale)
- μ₁ > μ₂ oppure μ₁ < μ₂ (monodirezionale)
3. Fissare il livello di significatività α:
Per delineare la regione di rifiuto dobbiamo considerare
- α
- gdl = n₁ + n₂ – 2 (gradi di libertà)
- H₁ (mono/bi-direzionale)
con questi 3 elementi possiamo trovare tcritico sulla tavola
4. Associare una probabilità ad H₀:
Per calcolare t (probabilità associata ad H0) si tulizza la formula
dove
5. Decisione su H₀ (⇒ H₁): Il confronto avviene tra t e tcritico come nel caso di un solo campione
Verifica ipotesi su 2 campioni dipendenti (media e varianza)
Verifiche sulla media
Unico campione con misure ripetute (misurazione della variabile dipendente). La nostra variabile indipendete è data dal “trattamento prima-dopo”.
In questo disegno di ricerca la verifica delle ipotesi si basa su una media.
Faremo riferimento alla DISTRIBUZIONE CAMPIONARIA DELLE MEDIE che confronteremo con la Distribuzione t di Student con (n-1) gradi di libertà.
Non conscenza dei parametri della popolazione (σ non note)
Dato un campione di ampiezza n, dal quale sono state tratte le misure xᵢ e yᵢ, possiamo calcolare la media delle differenze tra le due misure.
dove
dove
x_i fa riferimento alla prima misurazione, y_i alla seconda.
Procedura
La procedura segue questi punti
1) Scelta del test statistico: Si calcola t facendo riferimento alla dCM (distribuzione campionaria delle medie)
2) Definizione dell’ipotesi: Il confronto è tra la stessa popolazione prima/dopo esposizione a un certo trattamento
- H₀: μD = 0 (la media della differenza tra prima e dopo è uguale a zero, cioè non c’è differenza prima/dopo, e la terapia non ha funzionato)
- H₁: μD ≠ 0 (bidirezionale) μD > 0 oppure μD < 0 (monodirezionale)
3) Fissare il livello di significatività α e calcolare i gradi di libertà: Si delinea la regione di rifiuto trovando un tcritico sulla Tavola. La regione di rifiuto la si trova in base a:
- α
- gdl = n-1 (gradi di libertà)
- H₁ (mono/bi-direzionale)
4) Associare una probabilità ad H₀: Si associa una probabilità ad H₀ calcolando il punto t:
dove abbiamo
5) Decisioni su H₀ (⇒ H₁)
- | t | < | t_critico | ⇒ p < α ⇒ allora vera H0
- Altriemti vera H1
Conclusioni: Posto μD = 0 la probabilità di ottenere le medie osservate è minore/maggiore del 5% (alpha) fissato con α.
Verifiche sulla varianza
Ci troviamo in questo disegno di ricerca se
- ho 2 popolazioni con varianza σ² uguali
- ho 2 campioni indipendenti
- ho una variabile dipendente metrica sulla quale estraiamo le varianze dei 2 campioni (s₁² e s₂²) con numerosità n₁ e n₂
La distribuzione campionaria è la “distribuzione campionaria del rapporto tra varianze (dCRV)” confrontata con la distribuzione di probabilità F.
Procedura
- 1. Scelta del test statistico: Si calcola F facendo riferimento alla dCRV
- 2. Definizione dell’ipotesi: Il confronto è tra le due popolazioni di riferimento delle quali si vuol verificare l’omogeneità delle varianze:
- H₀: σ₁² = σ₂²
- H₁: σ₁² ≠ σ₂²
- 3. Fissare il livello di significatività α e calcolare i gradi di libertà: Si delinea la regione di rifiuto in base a:
- α
- Varianza stimata maggiore e minore
- gdl₁ = n₁ – 1 e gdl₂ = n₂ – 1 (2 gdl perchè fanno riferimento alle due varianze, quella maggiore e quella minore)
- trovando un Fcritico sulla Tavola. La tavola riporta i valori di F in base a gdl₁ e gdl₂ (riga e colonna riportano valori per gdl maggiore e minore)
- 4. Associare una probabilità ad H₀: Si associa una probabilità ad H₀ calcolando F tenendo conto quale è la varianza campionaria maggiore (che viene messa al numeratore):
- 5 Decisione su H₀ (⇒ H₁): Il confronto avviene tra F e Fcritico:
- Se F < Fcritico ⇒ p > α ⇒ Si accetta H₀ ⇒ vera l’ipotesi nulla, ovvero le varianze sono omogenee
- Se F > Fcritico ⇒ p < α ⇒ Si rifiuta H₀ ⇒ si accetta H₁ ⇒ vera l’ipotesi alternativa, ovvero le varianze non sono omogenee
Verifica delle ipotesi con χ²
Il caso di un campione
Verificare se una distribuzione osservata (i dati reali raccolti in un campione) si discosta significativamente da una distribuzione teorica attesa (basata su un’ipotesi o modello che supponiamo vero per la popolazione).
Si applica quando ho
- 1 variabile con k categorie (⇒ e quindi 1 solo campione) (nel dado k=6)
- una distribuzione di frequenza con k categorie
Ipotesi nulla (H₀): La distribuzione osservata nel campione non differisce da quella teorica attesa per la popolazione.
Ipotesi alternativa (H₁):La distribuzione osservata differisce da quella teorica
Procedura
1. Scelta del test statistico (di significatività): Si calcola χ² facendo riferimento alla distribuzione di frequenza
2. Definizione dell’ipotesi:
Confronta tra la dist. delle popolazioni (teorica) e quella del campione (osservata)
- H₀: χ² = 0 → o equidistribuzione nei diversi livelli della nostra variabile categoriale
- H₁: χ² ≠ 0 → o non equidistribuzione all’interno delle diverse categorie
3. Fissare il livello di significatività α e calcolare i gradi di libertà:
Si definisce la regione di rifiuto di H₀ in base a:
- α fissato ad es. 0.05, 0.01, ecc.
- gdl = k-1 → Si calcolano in base a k e n (vincolo dato dal totale dei casi osservati). k è il numero di valori possibili della variabile (esempio nel dado sono 6)
Si trova così un χ² critico sulla tavola del χ² (α colonna e gdl riga)
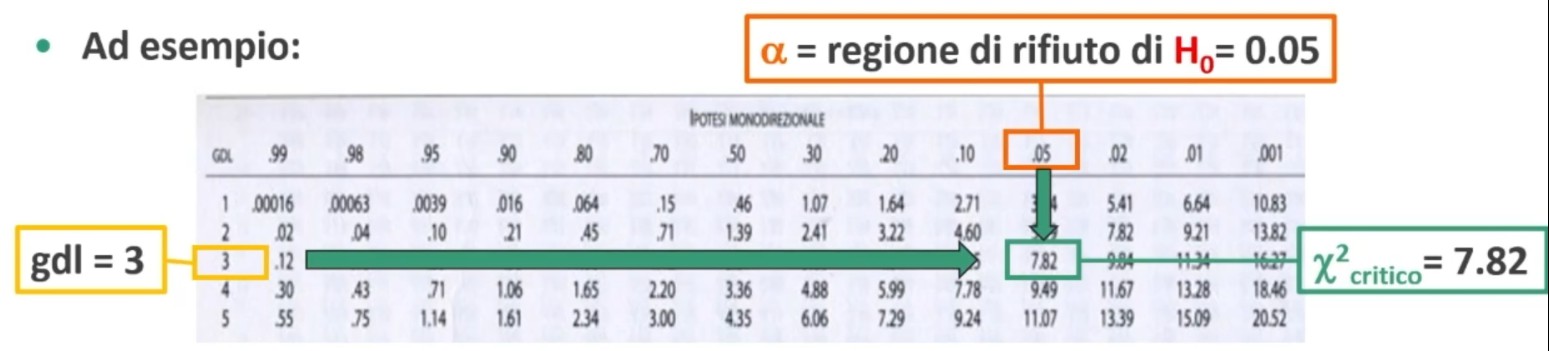
4. Associare una probabilità ad H₀:
Si associa una probabilità ad H₀, calcolando χ² per confrontare la distribuzione osservata (fₒ = dati campionari) con la distribuzione teorica (fₜ sarebbe la frequenza che mi aspetto in teoria, se lancio un dado 120 volte allora ft è 20)
5. Decisioni su H₀: (H₀:⇒H₁)
Il confronto avviene tra χ² e χ² critico. Se χ² < χ² critico ⇒ p > α allora
- Accetto H₀: Posta vera l’equidistribuzione, la probabilità di ottenere una distribuzione come quella osservata è sufficientemente elevata (maggiore di α)
se χ² > χ² critico ⇒ p < α allora
- Rifiuto H₀: Posta vera l’equidistribuzione, la probabilità di ottenere una distribuzione come quella osservata è molto bassa (minore di α)
Il caso di 2 campioni
In questo caso Il confronto avviene tra distribuzione teorica (popolazione) e una distribuzione osservata (nel campione) considerando due o più variabili.
Facciamo un’analisi delle contigenze, ovvero si analizza una cosidetta “tabella doppia entrata” o di contingenza.
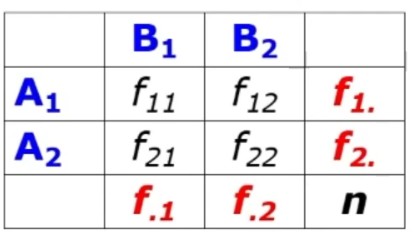
Il problema che ci poiniamo è se le frequenze sono distribuite casualmente. Ciò che abbiamo sono
- 2 variabili (2 o più campioni indipendenti)
- Tabella di contingenza a doppia entrata (r = righe) x (c = colonne)
La distribuzione teorica che useremo per il confronto è la distribuzione teorica del chi quadro.
Il modello sottoposto a verifica H₀ è quello di indipendenza tra le due variabili (tra A e B non c’è relazione)
Procedura
1. Scelta del test statistico: si calcola χ² facendo riferimento alle (due o più) distribuzioni di frequenza.
2. Definizione delle ipotesi: confronto la distribuzione teorica (indipendenza variabili) e quella osservata (dati campionari):
- H₀: χ² = 0 ovvero p(A1|B1) = p(A1)p(B2)
- H₁: χ² ≠ 0 ovvero p(A1|B1) ≠ p(A1)p(B2)
3. Fissare il livello di significatività α e calcolare i gradi di libertà:
Delineamo la regione di rifiuto H0 in base a
- α fissato a .05, .01, ecc.
- gdl = (r-1)(c-1) → righe (r) e colonne (c) della tabella di contingenza.
Si calcola χ² critico sulla Tavola.
4. Associare una probabilità ad H₀:
Si associa una probabilità ad H₀ calcolando χ²
fₒ = dati campionari
ft = distribuzione teorica di frequenze. Per ogni cella nella tabella si calcola un valore di ft in questo modo
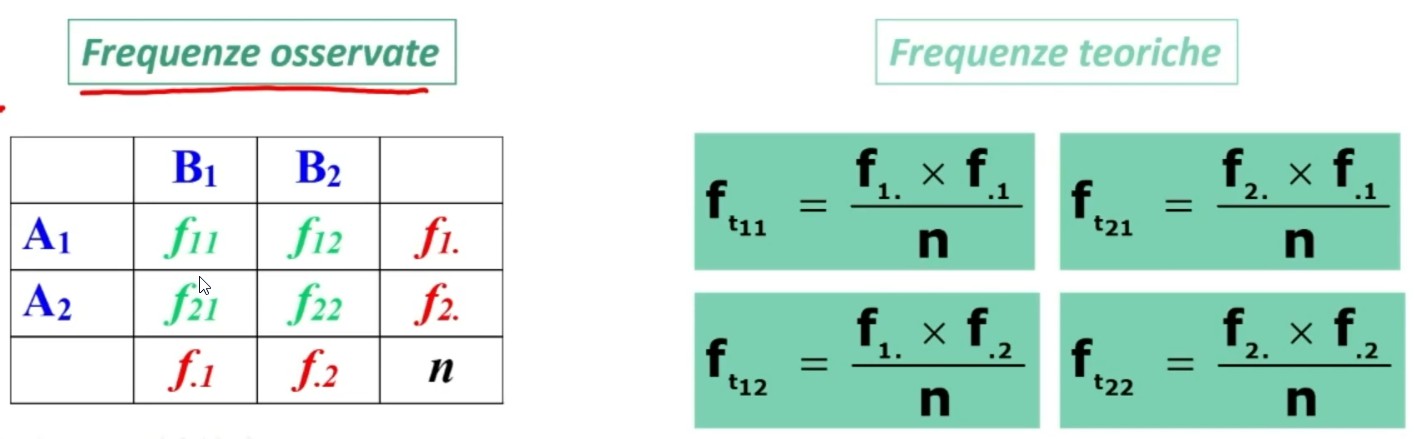
5. Decisione su H₀ (⇒ H₁):
Il confronto avviene tra χ² e χ² critico. Se χ² < χ² critico (p > α):
- Accetto H₀: Posta vera l’indipendenza, la probabilità di ottenere una distribuzione come quella osservata è maggiore di α. L’ipotesi di indipendenza è probabilmente vera, quindi tra le due variabili non c’è relazione
Se χ² > χ² critico (p < α):
- Rifiuto H₀: Posta vera l’indipendenza, la probabilità di ottenere una distribuzione come quella osservata è minore di α. L’ipotesi di indipendenza NON è vera ⇒ Tra le due variabili c’è una qualche relazione, ovvero c’è dipendenza.
Verifica delle ipotesi su R di Pearson
Il coefficiente di correlazione R di Pearson è una misura statistica che valuta la forza, la direzione e la linearità della relazione tra due variabili quantitative.
Varia tra -1 e +1
- +1: Correlazione lineare perfetta positiva (all’aumentare di una variabile, aumenta anche l’altra).
- -1: Correlazione lineare perfetta negativa (all’aumentare di una variabile, diminuisce l’altra).
- 0: Assenza di correlazione lineare.
Più il valore è vicino a ±1, più la relazione è forte. Se r
- Positiva: Le variabili crescono insieme.
- Negativa: Una variabile cresce mentre l’altra diminuisce.
ρ (rho) è il coefficiente di correlazione di Pearson nella popolazione, cioè il valore “vero” (e sconosciuto)
- R: Coefficiente di correlazione campionario (calcolato sui dati osservati). Stima di ρ, basata su un campione di dimensione n.
- ρ: Coefficiente di correlazione popolazionale (parametro teorico). Valor vero che vogliamo stimare o testare.
Quando si applica tale verifica?
- Abbiamo una popolazione dalla quale estraiamo un campione
- Su questo campione andiamo a misurare 2 variabili (x e y) metriche
Procedura
1. Scelta del test statistico (di significatività): Si calcola r e si trasforma in t.
2. Definizione dell’ipotesi: Confrontare con la popolazione di riferimento:
- H₀: ρ = 0 (non vi è una relazione significativa tra le 2 variabili)
- H₁: ρ ≠ 0 (bidirezionale)
- H1: ρ > 0 oppure ρ < 0 (monodirezionale)
3. Fissare il livello di significatività α e calcolare i gradi di libertà
Si definisce la regione di rifiuto in base a:
- α (= .05; .01; .001; ecc.)
- gdl = n – 2
- H₁ (mono/bi-direzionale)
Trovando un tcritico sulla Tavola.
4. Associare una probabilità ad H₀
Si associa una probabilità ad H₀ trasformando r in t: Calcolo prima r
e poi trasformo in t

5. Decisione su H₀ (⇒ H₁): Il confronto avviene tra t e tcritico
Se |t| < |tcritico| ⇒ p > α
- Si accetta H₀ ⇒ L’ipotesi di un’assenza di relazione (ρ=0) è probabilmente vera ⇒ La relazione tra le due variabili non è significativa.
Se |t| > |tcritico| ⇒ p < α
- Si rifiuta H₀ ⇒ Si accetta H₁ ⇒ L’ipotesi di un’assenza di relazione (ρ=0) è probabilmente falsa ⇒ La relazione tra le due variabili è significativa.
Verifica delle ipotesi con rs di Spearman
Misura la forza e la direzione della relazione monotonica (non necessariamente lineare) tra due variabili.
Monotonica: Se una variabile aumenta, l’altra aumenta (correlazione positiva) o diminuisce (correlazione negativa) in modo costante, ma non necessariamente a un tasso costante.
- Valori:
- +1: Correlazione perfetta positiva (monotonica crescente).
- -1: Correlazione perfetta negativa (monotonica decrescente).
- 0: Nessuna correlazione monotonica.
- Differenza con Pearson: Spearman usa i rangi (posizioni ordinate) dei dati invece dei valori grezzi, quindi è non parametrico e adatto a dati ordinali o non normali.
Il coefficiente rs va calcolato quando
- i dati sono costituiti da ranghi (graduatorie),
- oppure quando una delle variabili è ordinale, e l’altra metrica (previa trasformazione in rango).
La formula è
con
- di = differenza tra i ranghi di ciascuna coppia di punteggi. Esempio il rango 1 è la differenza (valore assoluto) dei punteggi delle variabilii nella posizione 1, E così via. Se nella tabella i dati non sono disposti secondo graduatoria devo prima carcolarmi i ranghi (Lezione 23)
- n = numero dei soggetti (o coppie di punteggi)
Procedura
L’ipotesi viene verificata sul ρₛ (rhoₛ), dove ρₛ = parametro nella popolazione corrispondente alla statistica rₛ. Vanno distinti due casi:
- Se n ≤ 30 i valori rₛ critici sono tabulati per due livelli di α (.05 e .01) e ipotesi monodirezionale in funzione del numero dei soggetti (non gdl). Quindi in questo caso usiamo la distribuzione rs di Spearman e i relativi valori critici.
- Se n > 30, così come per il coefficiente r di Pearson, esiste una relazione tra rₛ e t di Student. In questo caso procederemo usando la distribuzione di probabilità t (trasformare rs di Spearman in t di student)
1. Scelta del test statistico (di significatività) Si calcola rₛ
2. Definizione dell’ipotesi: Confronto con la popolazione di riferimento
- H₀: ρₛ = 0
- H₁: ρₛ ≠ 0 (bidirezionale solo se n > 30)
- H1: ρₛ > 0 oppure ρₛ < 0 (monodirezionale se n < 30)
3. Fissare il livello di significatività α:
Si delinea la regione di rifiuto in base a:
- α (= .05; .01; .001; ecc.)
- n (per n < 30) oppure gdl = n-2 (per n > 30)
- H₁ (monodirezionale per n < 30)
- H₁ mono-/bi-direzionale per n > 30
trovando un rₛ critico (per n < 30) oppure tcritico (per n > 30) sulla Tavola
4. Associare una probabilità ad H₀
Quando n < 30, si associa una probabilità ad H₀ calcolando rₛ e confrontandola con rₛ critico.
Quando n > 30, si associa una probabilità ad H₀ calcolando rs trasformandolo in t e confrontandolo con tcritico
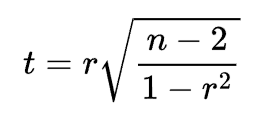
5. Decisione su H₀ (⇒ H₁): Il confronto avviene tra rₛ e rₛ critico per n < 30, Oppure tra t e tcritico per n > 30
Se |rₛ| < |rₛ critico| oppure |t| < |tcritico| = p > α
- Si accetta H₀ ⇒ L’ipotesi di un’assenza di relazione (ρₛ = 0) è probabilmente vera ⇒ La relazione tra le due variabili non è significativa.
Se |rₛ| > |rₛ critico| oppure |t| > |tcritico| = p < α
- Si rifiuta H₀ ⇒ Si accetta H₁ ⇒ L’ipotesi di un’assenza di relazione (ρₛ = 0) è probabilmente falsa ⇒ La relazione tra le due variabili è significativa.
Se nella tabella non ho i ranghi vedre spiegazione (Lezione 23)
Il coefficiente di correlazione tra variabili dicotomiche rphi
Il coefficiente di correlazione rphi va calcolato quando i dati sono costituiti da due variabili categoriali a due livelli.
- Valori:
- +1: Associazione perfetta positiva (se una variabile è “Sì”, anche l’altra è sempre “Sì”).
- -1: Associazione perfetta negativa (se una variabile è “Sì”, l’altra è sempre “No”).
- 0: Nessuna associazione lineare.
- Interpretazione:
- φ = 0: Le due variabili sono indipendenti (nessuna relazione).
- φ ≠ 0: C’è una relazione lineare tra le due variabili.
Si ha quando ho una tabella 2×2, ovvero quando ho due variabili dicotomiche, X e Y, con i seguenti valori:
| Y = Sì | Y = No | Totale | |
|---|---|---|---|
| X = Sì | a | b | a + b |
| X = No | c | d | c + d |
| Totale | a + c | b + d | N |
Dove:
- a, b, c, d = frequenze osservate in ogni cella.
- N = totale dei casi (a + b + c + d).
Allora
Procedura verifica ipotesi
La verifica dell’ipotesi viene indicata con πphi (pi greco phi). Si associa una probabilità ad H₀ (πphi = 0 oppure ρ = 0) delineando la regione di rifiuto attraverso il χ² critico.. Infatti
1. Scelta del test statistico (di significatività):
Ho 2 variabili dicotomiche -> Scelgo rphi (indagine della relazione tra due variabili dicotomiche)
2. Definisco le ipotesi: Ho le seguenti ipotesi
- H₀: πphi = 0 (assenza di relazione)
- H₁: πphi ≠ 0 (presenza di una relazione)
3. Delineo la regione di rifiuto di H₀:
Fissiamo α = .01 e gdl = (2 righe – 1)(2 colonne – 1) = 1 → sulla tavola, trovo χ² critico
4. Associare una probabilità ad H₀:
calcolo r_phi con la formula
e poi mi ricavo il χ² con
5. Decisione su H₀ (⇒ H₁):
Facciamo il confronto
χ² < χ² critico ⇒ p > α ⇒ vera H0
Verifica delle ipotesi sul coefficiente di regressione lineare
Data una variabile “x” (detta variabile indipendente), antecedente all’altra variabile, “y” (detta variabile dipendente), lo studio della loro relazione permette di verificare se e quanto la V.I. (variabile indipendente) «spiega» o «influenza» la V.D.
Ciò avviene con l’equazione di regressione. Tale equazione, quando si tratta di relazioni lineari, non è altro che l’equazione di una retta.
Dove b è il COEFFICIENTE DI REGRESSIONE (o angolare) e indica l’inclinazione della retta, e a è l’INTERCETTA sull’asse delle ordinate.
con ȳ = y medio, e x̄ = x medio
Procedura
La verifica viene effettuata su su β (beta) parametro nella popolazione corrispondente al coefficiente b. L’ipotesi viene verificata trasformando la b in una t.
La situazione in cui ci troviamo è la seguente
- abbiamo una popolazione dalla quale abbiamo estratto 1 campione
- abbiamo 2 VARIABILI METRICHE (covarianza) e siamo interessati capire se una variabile influisce sull’altra. In teoria dovrebbe darmi anche le medie e le deviazioni standard.
La procedura da seguire è la seguente
1. scelta del test statistico (di significatività): Abbiamo Due variabili metriche di cui voglio indagare relazione causale. Si calcola b e si trasforma in t
2. Definizione dell’ipotesi: Confrontare con la popolazione di riferimento
- H₀: β = 0 (non c’è effetto)
- H₁: β ≠ 0 (bidirezionale)
- β > 0 oppure β < 0 (monodirezionale)
3. Fissare il livello di significatività α e calcolare i gradi di libertà
Si definisce la regione di rifiuto in base a:
- α (= .05; .01; .001; ecc.)
- gdl = n – 2
- H₁ capire se è mono/bi-direzionale
Si trova poi un tcritico sulla Tavola
4. Associare una probabilità ad H₀
Si associa una probabilità ad H₀ trasformando b in t. La t è dato dal rapporto tra b e il suo errore standard
Dove b è quello precedente, ES_b (errore standard) è dato da
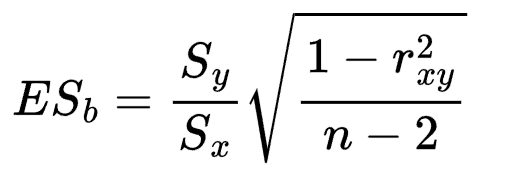
con
che deriva da
5. Decisione su H₀ (accettazione o rifiuto di H₁): Il confronto avviene tra t e tcritico
Se |t| < |tcritico| = p > α
- Si accetta H₀: l’ipotesi di un’assenza di relazione (β = 0) è probabilmente vera
- La relazione causale tra le due variabili non è significativa.
Se |t| > |tcritico| = p < α
- Si rifiuta H₀: si accetta H₁: l’ipotesi di un’assenza di relazione (β = 0) è probabilmente falsa
- La relazione causale tra le due variabili è significativa.