Table of Contents
La regressione lineare
Il concetto di regressione è legato a quello di previsione, ovvero alla possibilità di prevedere, in base alla variazione di una variabile, la variazione di un’altra variabile ad essa correlata.
Viene introdotta, quindi, la relazione di causa-effetto, o meglio, di antecedente-susseguente.
Data una variabile “x” (detta variabile indipendente), antecedente all’altra variabile, “y” (detta variabile dipendente), lo studio della loro relazione permette di verificare se e quanto la V.I. (variabile indipendente) «spiega» o «influenza» la V.D.
Quando la correlazione tra le due variabili è molto alta, dato un valore di “X” (V.I.), è possibile prevedere il corrispondente valore di “Y” (V.D.) attraverso l’equazione di regressione.
Se per esempio consideriamo X (capacità di ragionamento astratto) la variabile indipendente, che precede logicamente la variabile dipendente, Y (voto in matematica) si può supporre influenzata o spiegata dalla variabile indipendente X. Per logica non è vero il contrario, il voto in matematica non può influire su una capacità già esistente nel soggetto.
Il legame tra correlazione e regressione è espresso dal coefficiente di determinazione che è il coefficiente di correlazione elevato al quadrato.
Ricordiamo la formula che esprime il coefficiente di correlazione lineare r attraverso la covarianza:
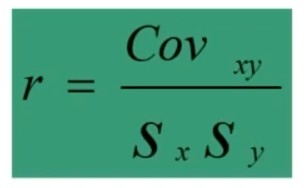
(covarianza di x e y, poi sotto ho le deviazioni standard di x e y). Il coefficiente di determinazione sarà quindi
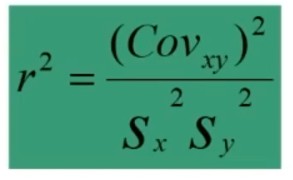
Esso esprime la proporzione di varianza di Y (variabile dipendente) spiegata dall’influenza di X (variabile indipendente).
Se la relazione tra X e Y è perfetta, positiva o negativa (cioè r = +1 o -1), r² sarà uguale a 1.00, e cioè che la «varianza spiegata» corrisponde al 100%.
In tutti i casi intermedi abbiamo una parte di varianza, detta residua, che è la porzione di varianza della V.D. non spiegata dalla V.I. (1 – r²).
Se, riferendoci all’esempio, la correlazione tra X (ragionamento astratto) e Y (voto in matematica) risultasse r = 0.72, il coefficiente di determinazione r² = 0.52 indicherebbe che il 52% della variabilità di Y è spiegato dalla variabile antecedente X.
In questo caso la varianza residua sarebbe 1 – 0.52 = 0.48.
Con l’analisi della regressione studiamo se e quanto i valori assunti da Y (V.D.) dipendono dai valori corrispondenti assunti da X (V.I.).
Al concetto di regressione è collegato quello di «previsione». Quando il legame tra due variabili è molto stretto (correlazione elevata = elevata porzione di varianza comune), dato un valore di X, è possibile «prevedere», con un margine d’errore più o meno grande, il corrispondente valore di Y.
Indicheremo tale valore con il simbolo Y’ (Y predetto).
Per effettuare la previsione di Y dato X, si utilizza l’equazione di regressione.
Tale equazione, quando si tratta di relazioni lineari, non è altro che l’equazione di una retta.
Tuttavia, non si tratta di una retta qualsiasi bensì quella costruita in modo che sia la migliore tra tutte le infinite rette che si possono far passare attraverso i punti-intersezione del diagramma di dispersione.
Il criterio utilizzato per individuare tale retta è quello dei minimi quadrati, che consiste nello scegliere la retta che rende minima la somma delle distanze al quadrato tra le Y (osservate) e le Y’ (predette):
Σ (Y – Y’)² = minimo
Questa è la retta che, tra le infinite possibili, si avvicina più di tutte a tutti i punti del diagramma di dispersione.
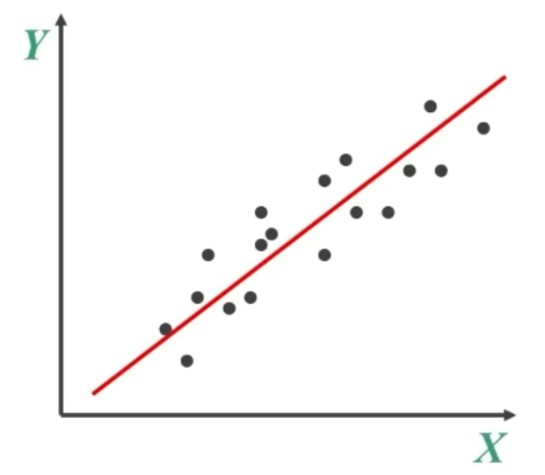
L’equazione di una retta generica è:
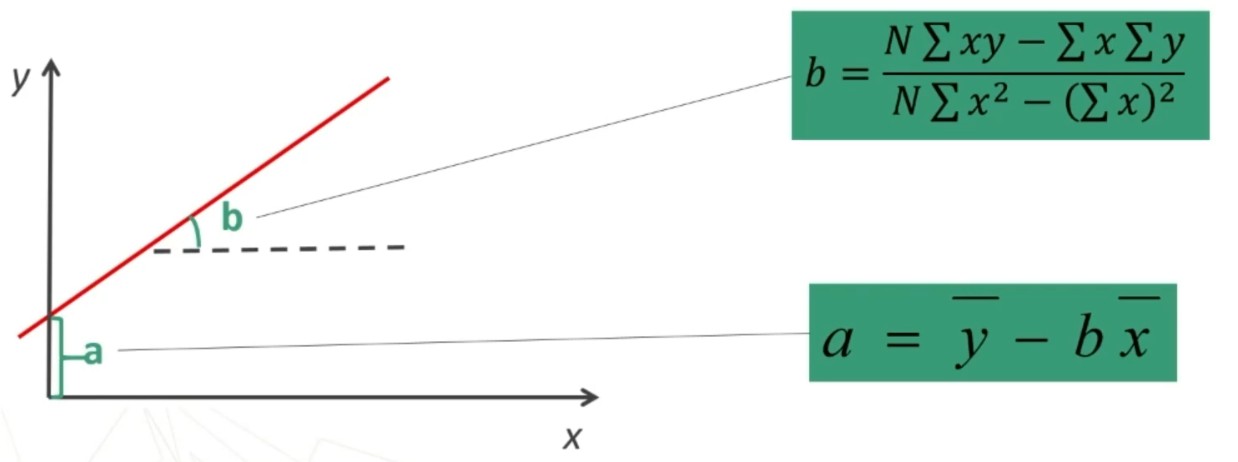
y = a + bx
L’equazione della retta di regressione è:
y’ = a + bx
dove il parametro b:
- è il COEFFICIENTE DI REGRESSIONE (o angolare)
- indica l’inclinazione della retta, ovvero l’angolo che essa forma con l’asse delle ascisse
- Esprime la quantità di incremento (se positivo) o decremento (se negativo) che si verifica in Y per ogni unità di incremento o decremento in X.
- È il peso della V.I. sulla V.D.
Il parametro b lo andiamo a calcolare con
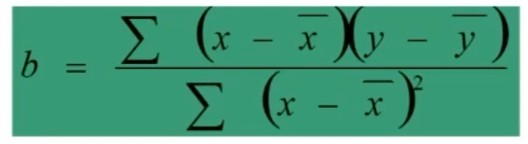
cioè il rapporto tra la somma del prodotto degli scarti di X e di Y dalle rispettive medie, e la somma degli scarti al quadrato di X.
A partire dalla precedente formula si ricava una formula semplificata di b per il calcolo dai dati grezzi.
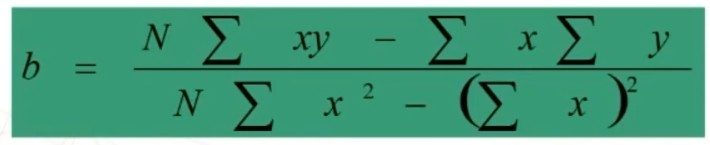
Mentre il parametro a:
- è l’INTERCETTA sull’asse delle ordinate.
- Indica il punto in cui la retta incontra l’asse delle ordinate, ovvero la distanza tra l’origine degli assi e il punto in cui la retta taglia (incontra) l’asse delle ordinate.
Si ricava attraverso la seguente formula:
a = ȳ – b x̄
con
- ȳ: y medio
- x̄: x medio
Esempio
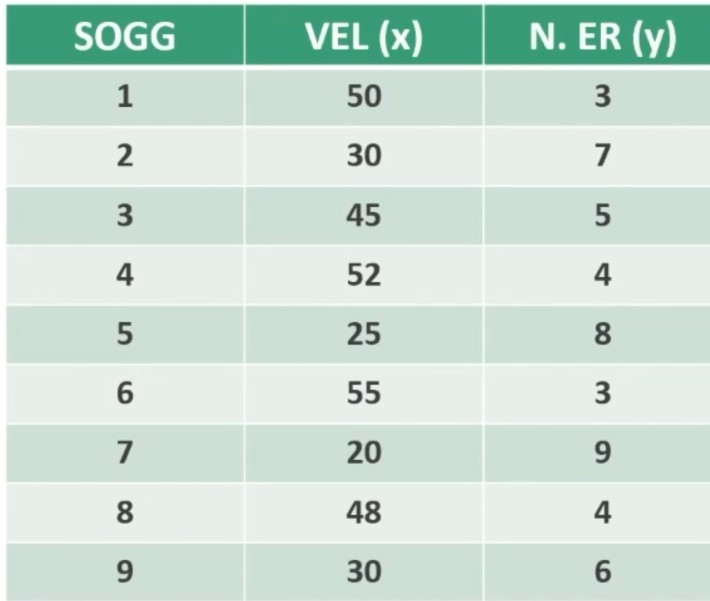
Abbiamo un campione di 9 adolescenti a cui abbiano chiesto di completare un compito e abbiano misurato il tempo impiegato.
Vogliamo verificare se la «velocità di esecuzione» (X) predice (spiega) il «numero di errori commessi» (Y).
Osserviamo la seguente distribuzione di punteggi:
facciamo i nostri calcoli e aggiungiamo due colonne
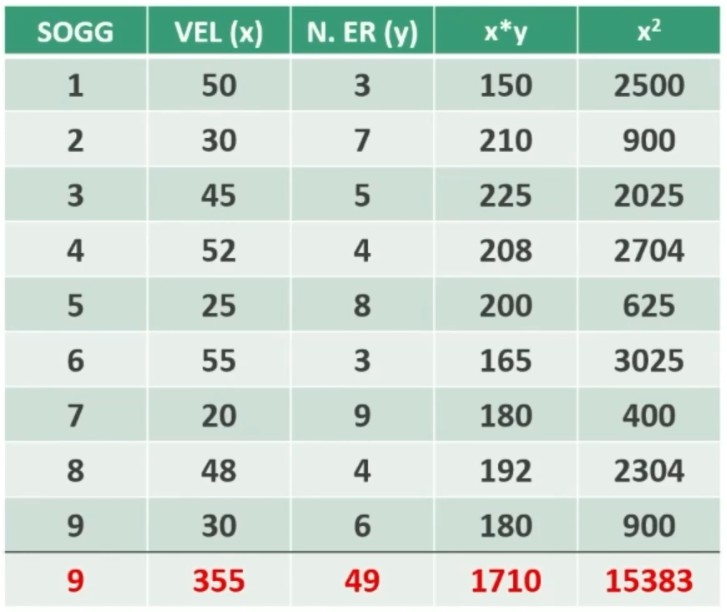
Calcoliamo ora b e a

Per tracciare la retta sarà sufficiente calcolare due valori di Y’:
Y’ per un soggetto che impiega x = 20 secondi e per un soggetto che impiega x = 55 secondi nel risolvere il compito.
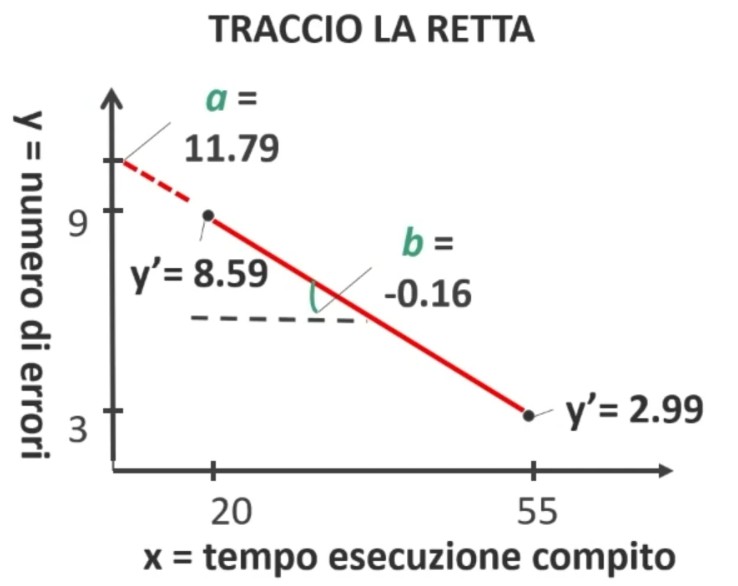
Nella retta di regressione trovata si sostituisce ad x il valore di interesse e si calcola Y’:
- Y’ = 11.79 + (-0.16 * 20) = 8.59
- Y’ = 11.79 + (-0.16 * 55) = 2.99
Verifica delle ipotesi sul coefficiente di regressione
Come posso valutare se la relazione sintetizzata tramite il coefficiente regressione è significativa, cioè probabilisticamente diversa da zero?
Devo fare la verifica delle ipotesi, e questa verifica viene effettuata su β (beta):
- β = (parametro nella popolazione corrispondente al coefficiente b)
L’ipotesi viene verificata trasformando la b in una t (come per la correlazione).
La situazione in cui ci troviamo è la seguente
- abbiamo una popolazione dalla quale abbiamo estratto 1 campione
- abbiamo 2 VARIABILI METRICHE (covarianza) e siamo interessati capire se una variabile influisce sull’altra
Siamo nell’ambito della DISTRIBUZIONE NORMALE BIVARIATA (Spazio cartesiano a tre assi, tridimensionale) e useremo come distribuzione teorica di riferimento la DISTRIBUZIONE TEORICA DI PROBABILITÀ t
La procedura da seguire è la seguente
1. scelta del test statistico (di significatività): Abbiamo Due variabili metriche di cui voglio indagare relazione causale. Si calcola b e si trasforma in t
2. Definizione dell’ipotesi: Confrontare con la popolazione di riferimento
- H₀: β = 0 (non c’è effetto)
- H₁: β ≠ 0 (bidirezionale)
- β > 0 oppure β < 0 (monodirezionale)
3. Fissare il livello di significatività α e calcolare i gradi di libertà
Si definisce la regione di rifiuto in base a:
- α (= .05; .01; .001; ecc.)
- gdl = n – 2
- H₁ capire se è mono/bi-direzionale
Si trova poi un tcritico sulla Tavola
4. Associare una probabilità ad H₀
Si associa una probabilità ad H₀ trasformando b in t. La t è dato dal rapporto tra b e il suo errore standard
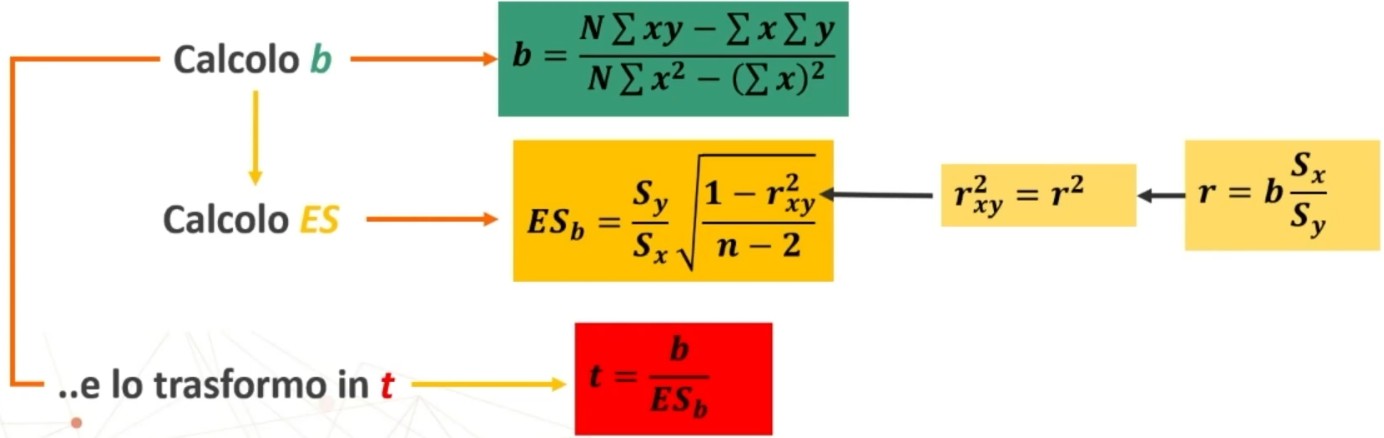
5. Decisione su H₀ (accettazione o rifiuto di H₁): Il confronto avviene tra t e tcritico
Se |t| < |tcritico| = p > α
- Si accetta H₀: l’ipotesi di un’assenza di relazione (β = 0) è probabilmente vera
- La relazione causale tra le due variabili non è significativa.
Se |t| > |tcritico| = p < α
- Si rifiuta H₀: si accetta H₁: l’ipotesi di un’assenza di relazione (β = 0) è probabilmente falsa
- La relazione causale tra le due variabili è significativa.
Esempio
Abbiamo un campione di 9 adolescenti a cui abbiano chiesto di completare un compito e abbiano misurato il tempo impiegato. Vogliamo verificare se la «velocità di esecuzione» (x) predice o spiega (relazione causale) il «numero di errori commessi» (y).
Sappiamo che la media x̄ = 34.4 con deviazione standard sx = 13.1 e che la media della y è ȳ = 5.4 con deviazione standard sy = 2.2
1. scelta del test statistico (di significatività):
Abbiamo
- 1 Campione: n = 9
- 2 variabili metriche: «velocità di esecuzione» e «numero di errori commessi» di cui vogliamo indagare la relazione causale
Scelgo di calcolare b
2. Definizione dell’ipotesi:
Le ipotesi saranno
- H₀: β = 0 (La velocità di esecuzione non predice significativamente il numero di errori commessi; non vi è una relazione causale tra le due variabili)
- H₁: β ≠ 0 (Bidirezionale: la velocità di esecuzione predice significativamente il numero di errori commessi; vi è una relazione causale significativa tra le due variabili)
3. Fissare il livello di significatività α e calcolare i gradi di libertà
Fissiamo α = .05; H₁ è bidirezionale; gdl = 9 – 2 = 7
Si definisce la regione di rifiuto secondo α, gdl e H₁, bidirezionale trovando un tcritico sulla Tavola
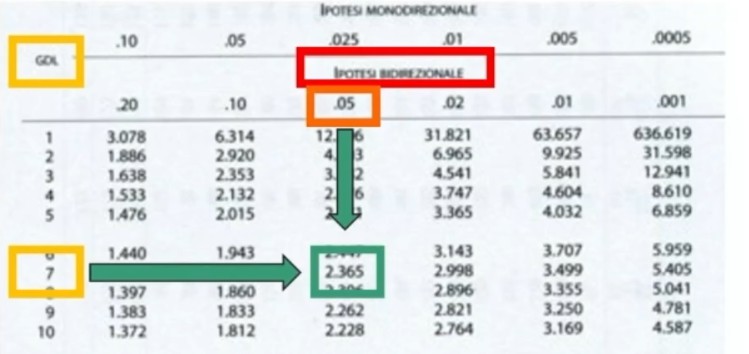
tcritico = 2.365
4. Associare una probabilità ad H₀
Calcolo b e lo trasformo in t
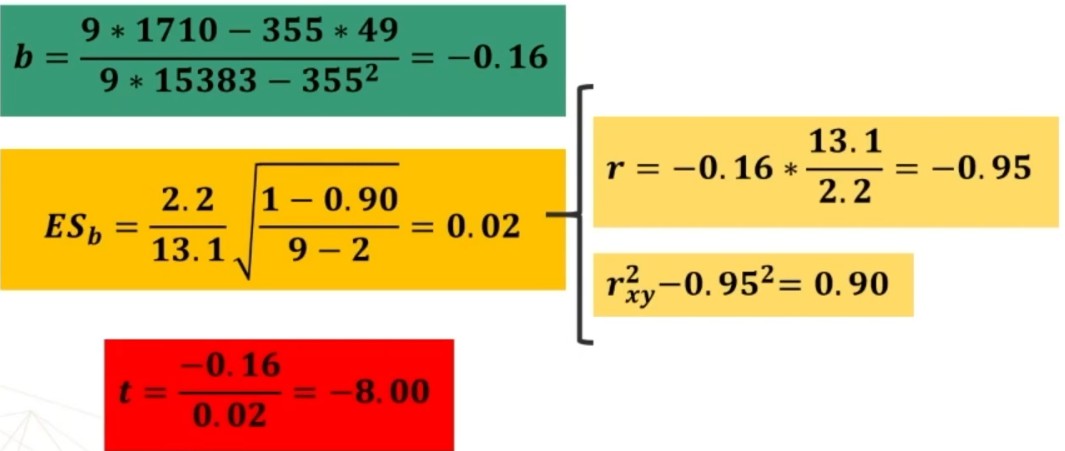
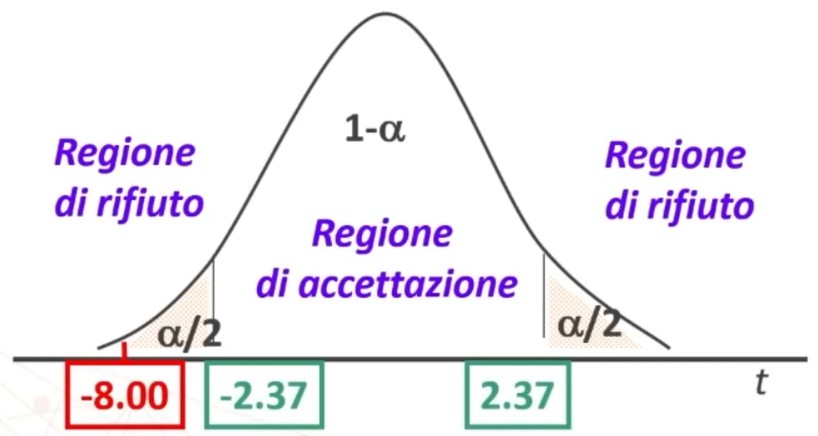
5. Decisione su H₀ (accettazione o rifiuto di H₁)
Abbiamo
| 8.00 | < | 2.37 | → p < .05
Quindi si rifiuta H₀, si accetta H₁, quindi si considera “verosimile” l’ipotesi alternativa
La probabilità che β sia uguale a 0 è minore del 5% fissato con α; ne concludo che:
- L’ipotesi di un’assenza di relazione (β = 0) è probabilmente falsa
- Vi è una relazione causale significativa tra la velocità di esecuzione e il numero di errori commessi.
- La velocità di esecuzione predice negativamente e significativamente il numero di errori commessi.