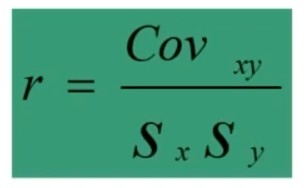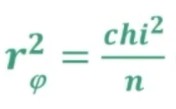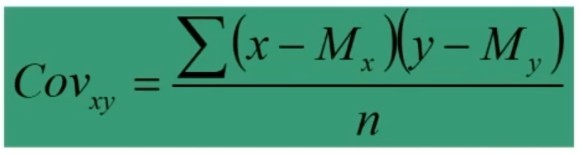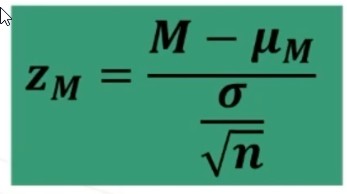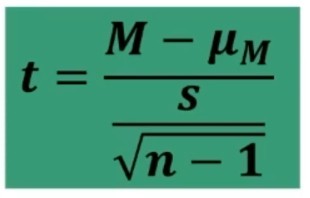Table of Contents
- Introduzione
- Metodo del Test-Retest
- Metodo delle forme parallele
- Metodo della coerenza interna
- Errore standard di misura
- Uso dell’errore standard di misura
Introduzione
L’attendibilità (o fedeltà) riguarda la precisione dello strumento. La misura che otteniamo oggi su una determinata caratteristica dobbiamo poterla ottenere anche a distanza di tempo. Effettuando due misure con lo stesso strumento vi deve essere un accordo, una coerenza.
Tutte le misure sono affette da errori dovuti al caso. Il dato osservato X è costituito da una parte che corrisponde alla misura “vera” V e da una parte di errore casuale E.
Una misura è attendibile, quando si dimostra che tali errori di misura incidono in piccola parte, cioè che E sia molto piccolo e quindi il dato osservato X sia molto vicino al valore vero V.
Quindi l’attendibilità non è altro che l’affidabilità del nostro strumento, cioè il grado di accordo tra diversi tentativi di misurare uno stesso concetto teorico.
Quindi abbiamo che il nostro punteggio X è dato da una componente vera e un errore.
X = V + E
Dove: X = punteggio osservato, V = punteggio vero, E = errore casuale.
L’attendibilità può essere espressa come la percentuale di X che è dovuta al punteggio vero, overo tra rapporto tra V e somma di V ed E.
V / (V + E)
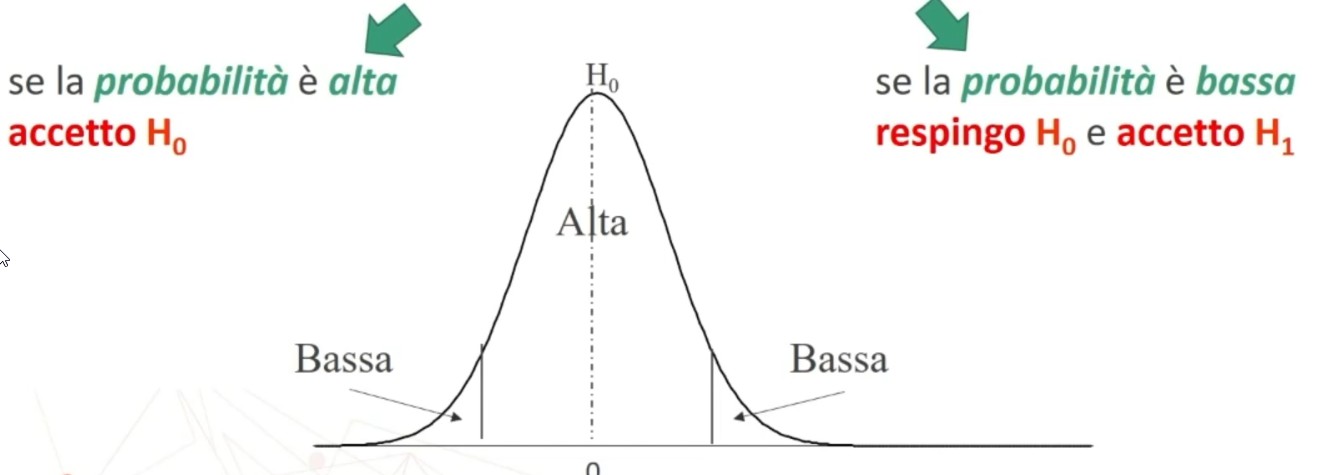
Le ASSUNZIONI STATISTICHE DELLA TEORIA sono che
1. la media degli errori casuali deve essere nulla per n che tende all’infinito
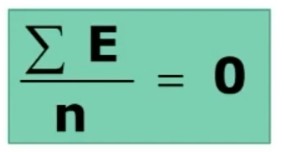
2. Punteggio vero e errore sono indipendenti.

3. Due errori casuali sono indipendenti.

Da tali assunzioni deriva che il punteggio osservato medio è
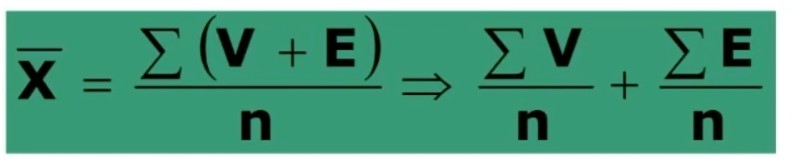
Per n → ∞ ho che il punteggio osservato medio è uguale al punteggio vero medio.
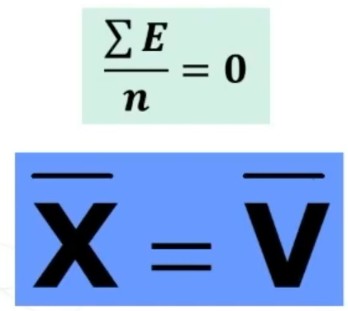
In altre parole perché la misura possa dirsi attendibile si assume dunque che tali errori di misura incidano in piccola parte, cioè che E sia molto piccolo e quindi il dato osservato X sia molto vicino al valore V.
Da qui si dimostra che la varianza del punteggio osservato è uguale alla somma della varianza della parte “vera” e della varianza d’errore.
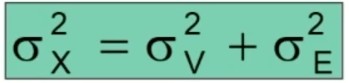
Inoltre si dimostra che dividendo entrambi i membri dell’equazione per la varianza del punteggio osservato, si ottiene il coefficiente di attendibilità.
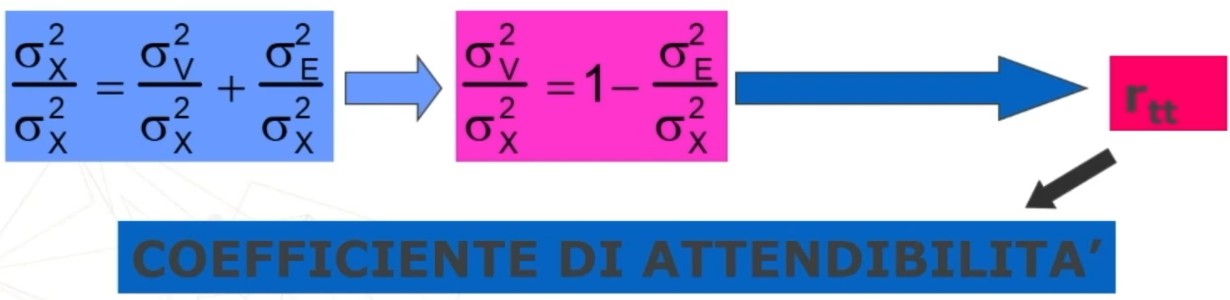
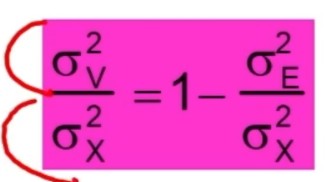
In base a questa formula, possiamo definire l’attendibilità come il rapporto tra la varianza della parte vera e la varianza osservata.
Tale rapporto è massimo (cioè = 1) quando la varianza d’errore è minima (tendente a 0).
Il valore dell’attendibilità ha quindi la proprietà
- di variare tra 0 e 1
- aumenta al diminuire della varianza di errore
Quindi maggiore è rtt e maggiore sarà la precisione dello strumento
Metodo del Test-Retest
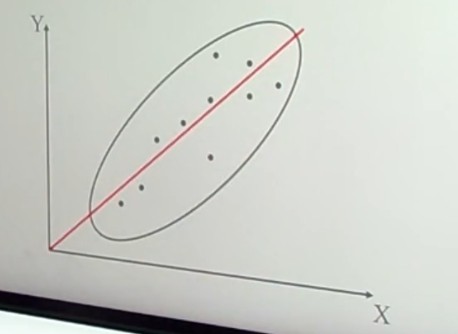
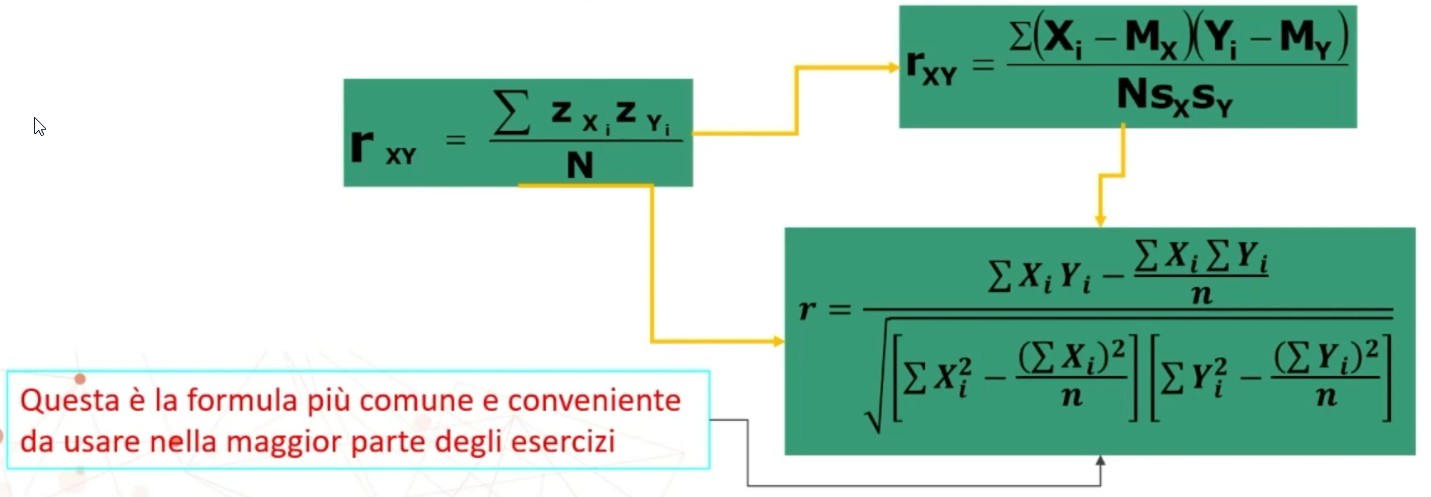
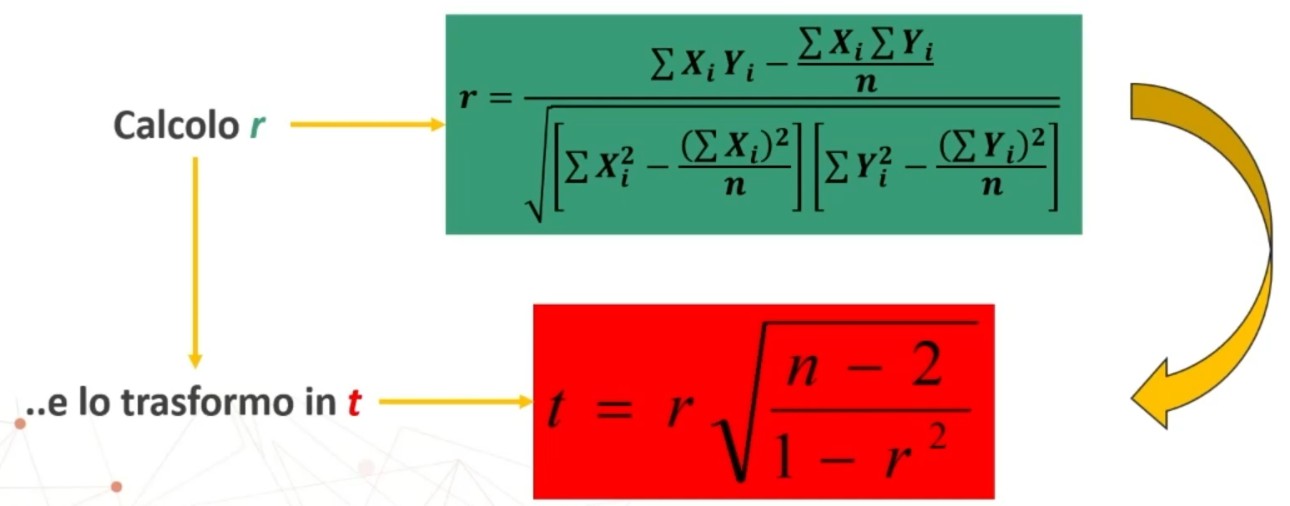
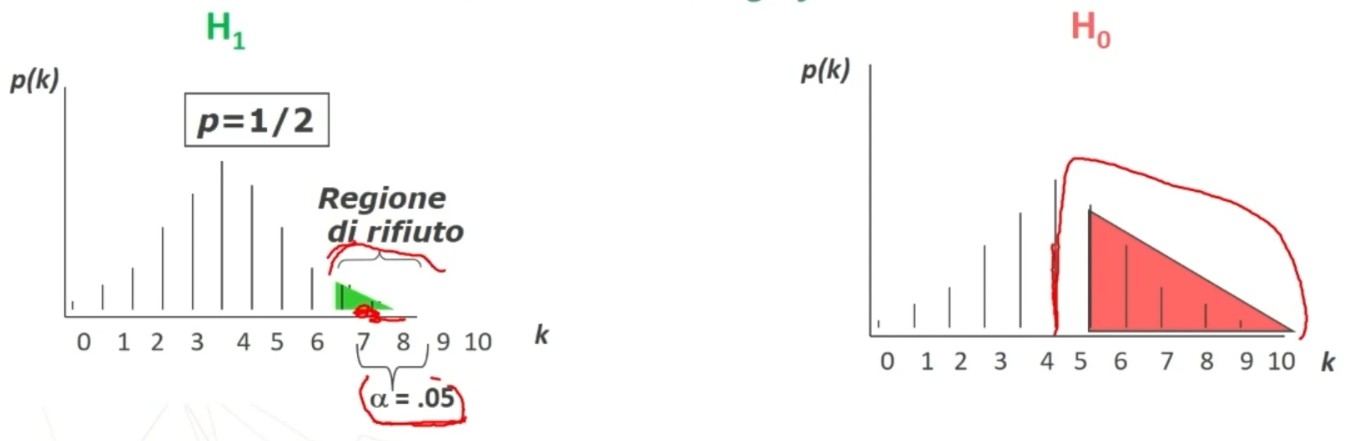
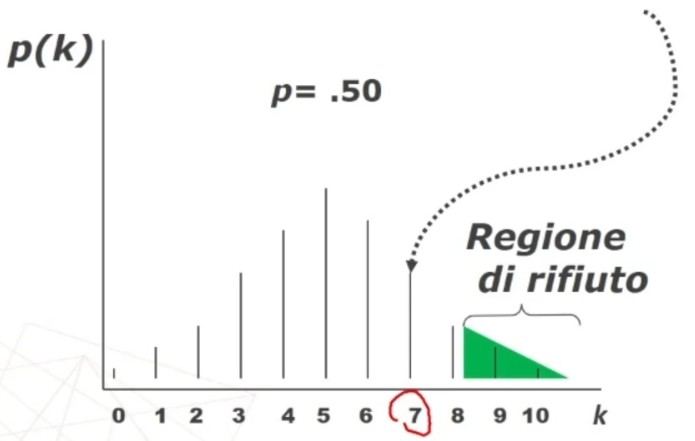
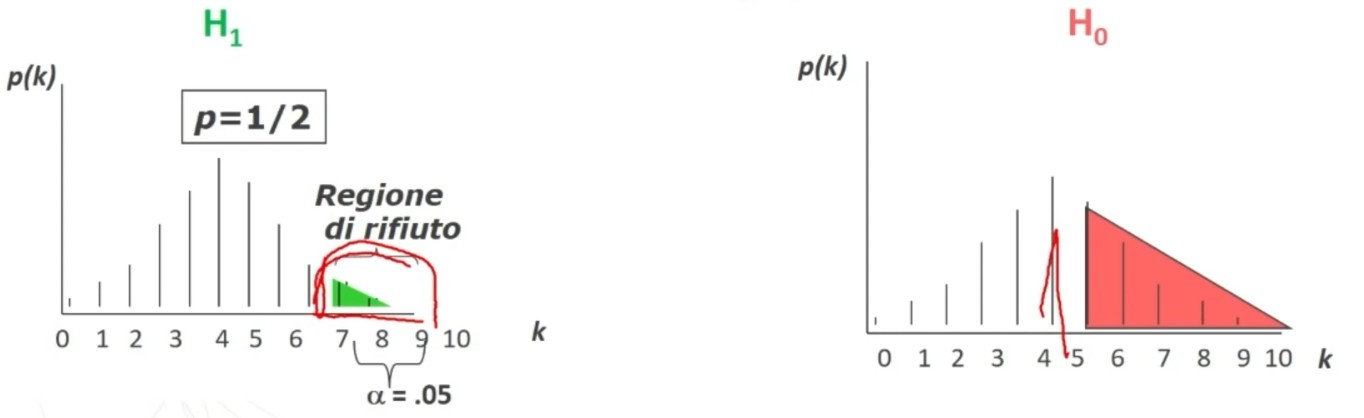
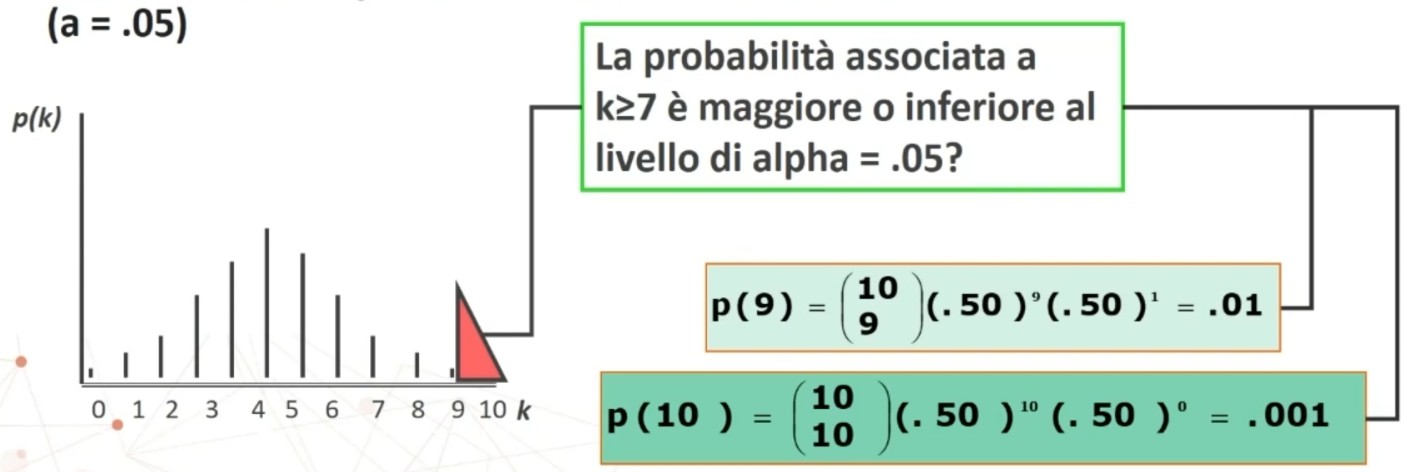
L’attendibilità di può calcolare in modi diversi. Una prima modalità riguarda l’utilizzo test-retest (r di Pearson)
Per fare ciò:
- Si somministra il test al tempo T1 e al tempo T2 e si calcola la correlazione tra i punteggi.
Questo metodo non necessita di ulteriori specificazioni. Basta saper calcolare la r di Pearson tra due serie di punteggi.
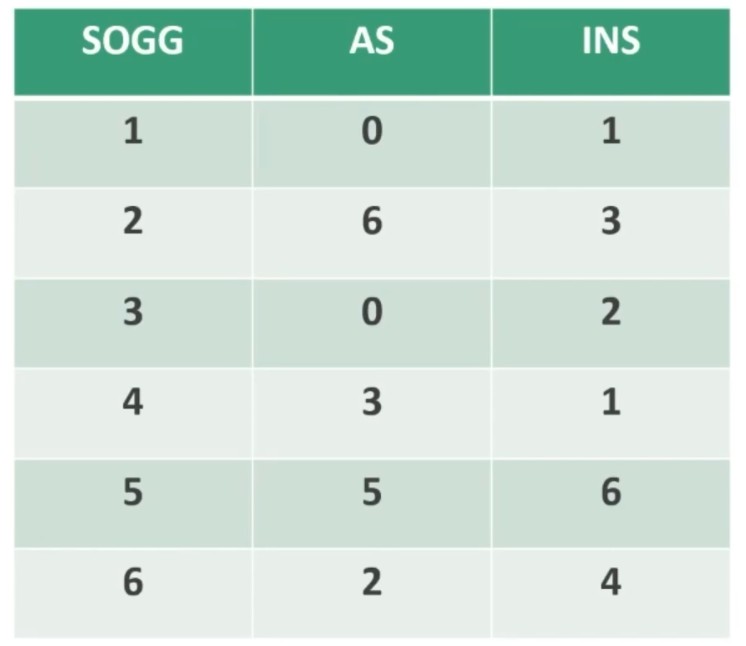
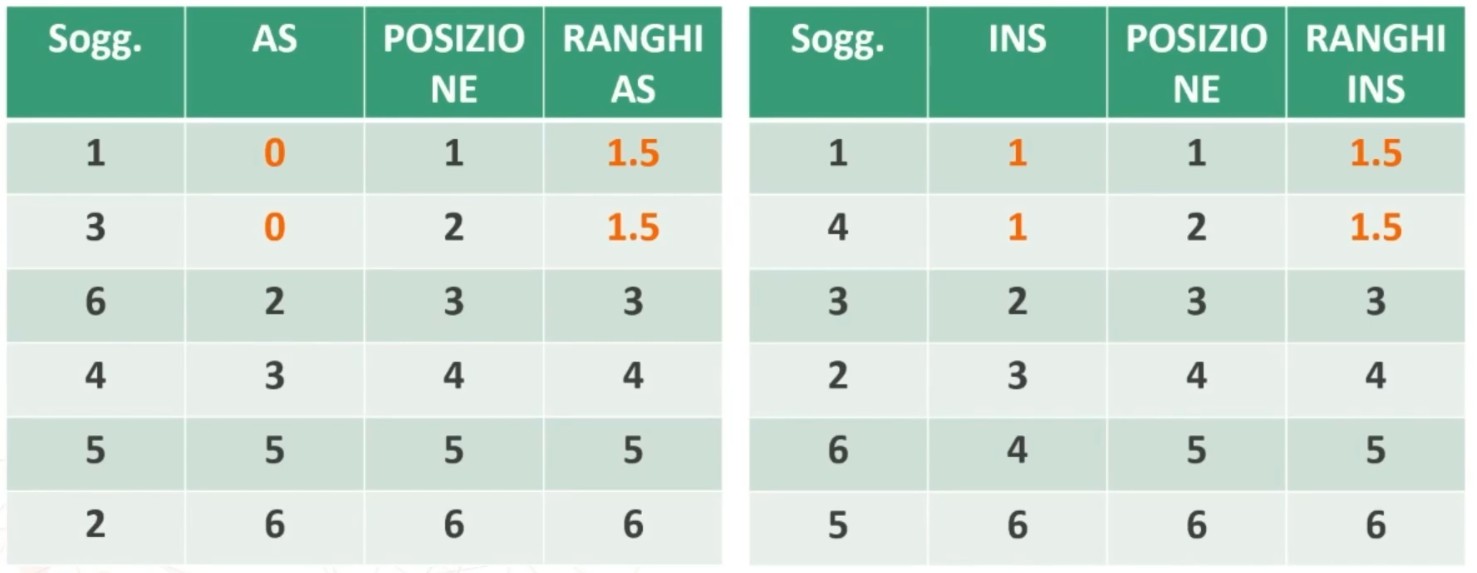
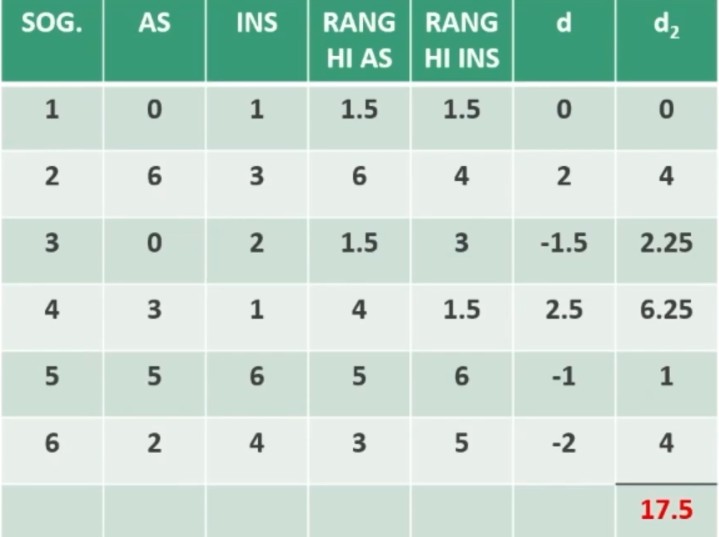
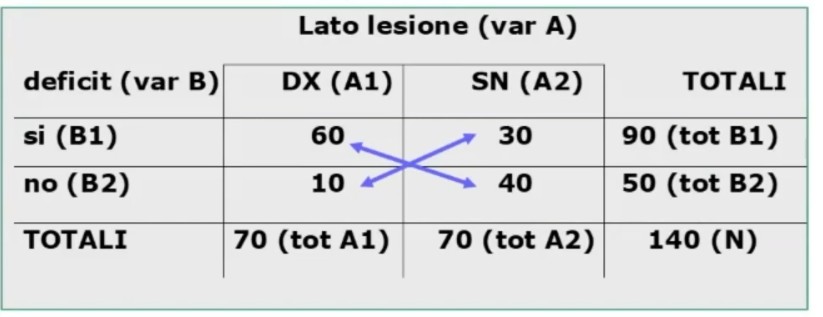
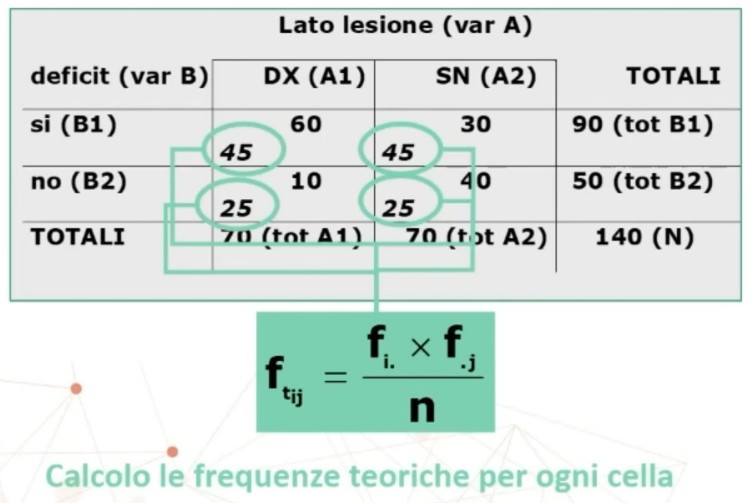
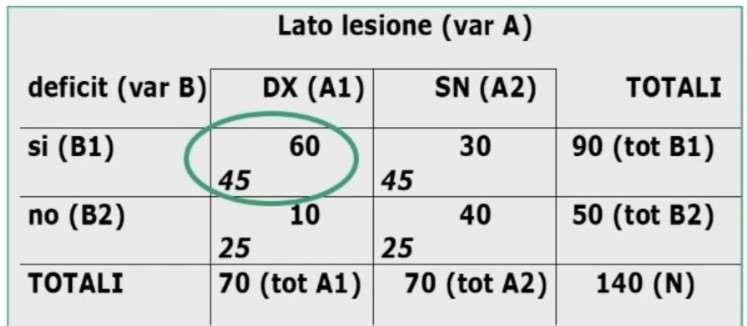
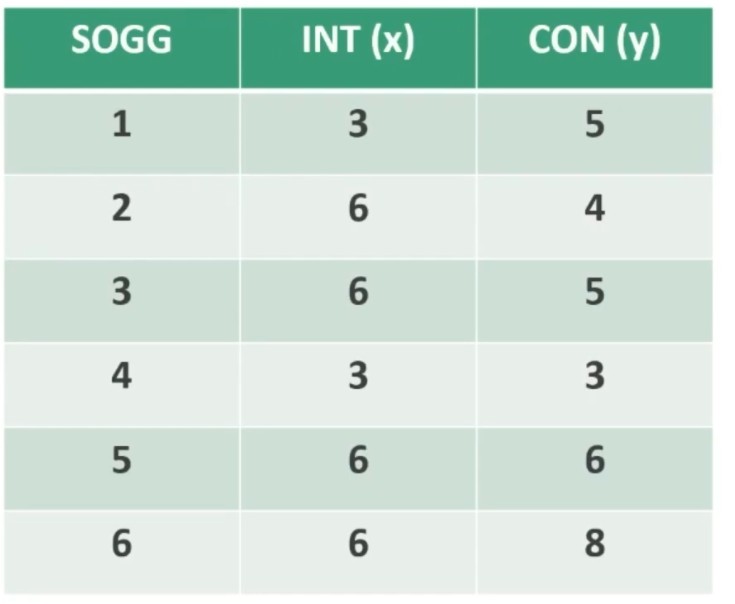
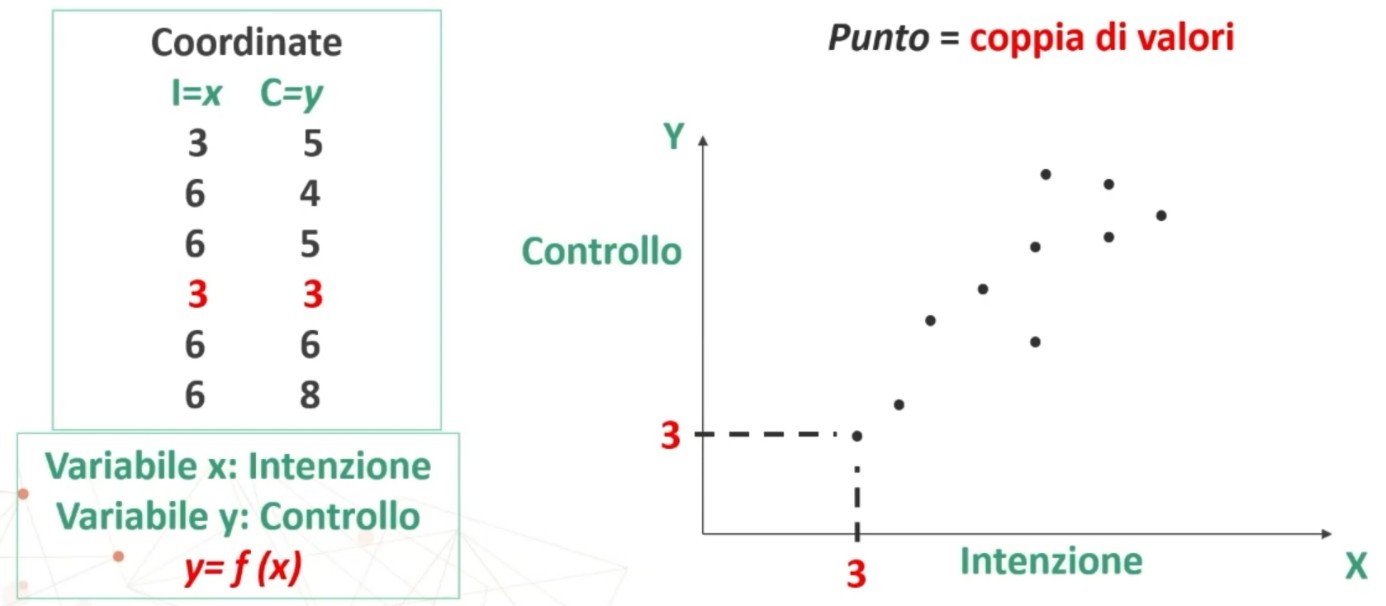
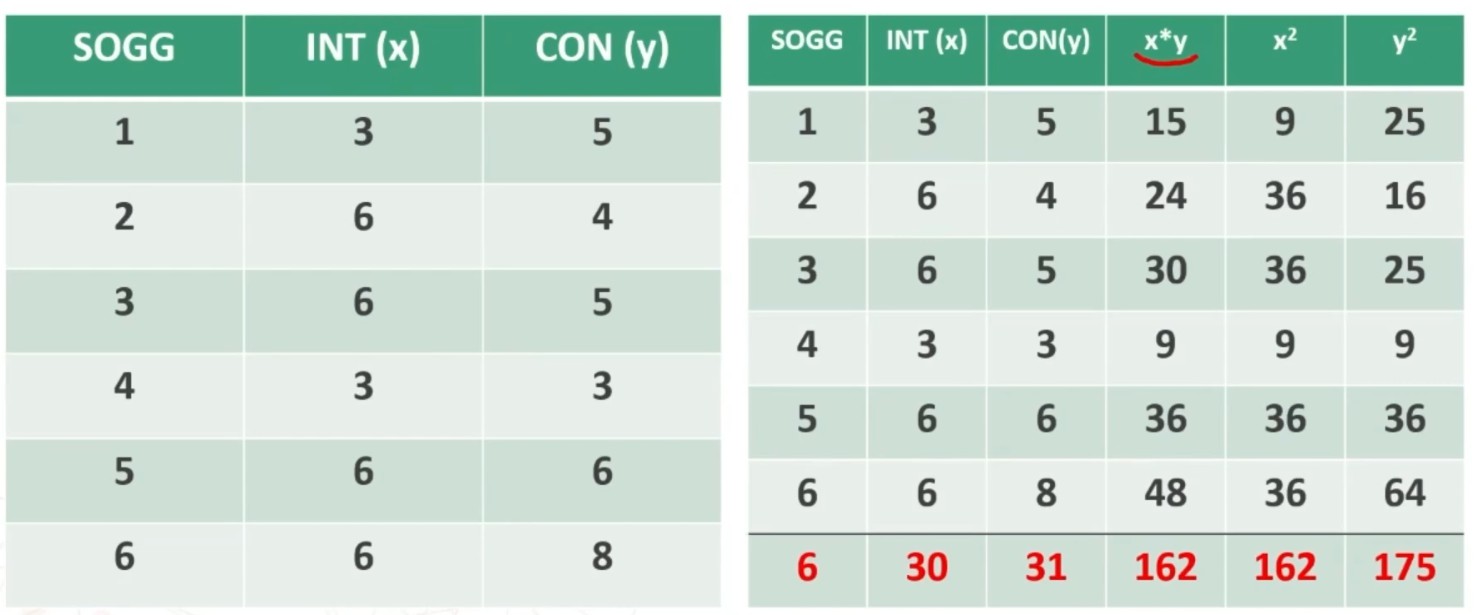
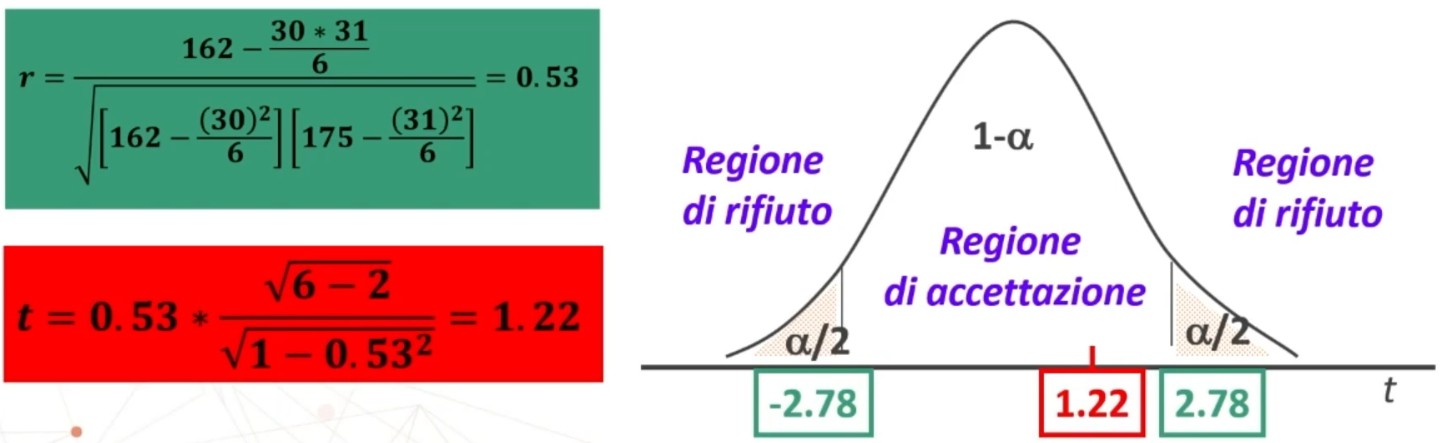
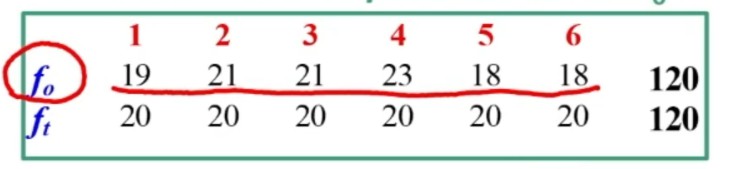
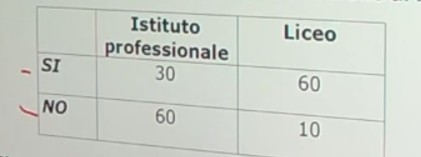
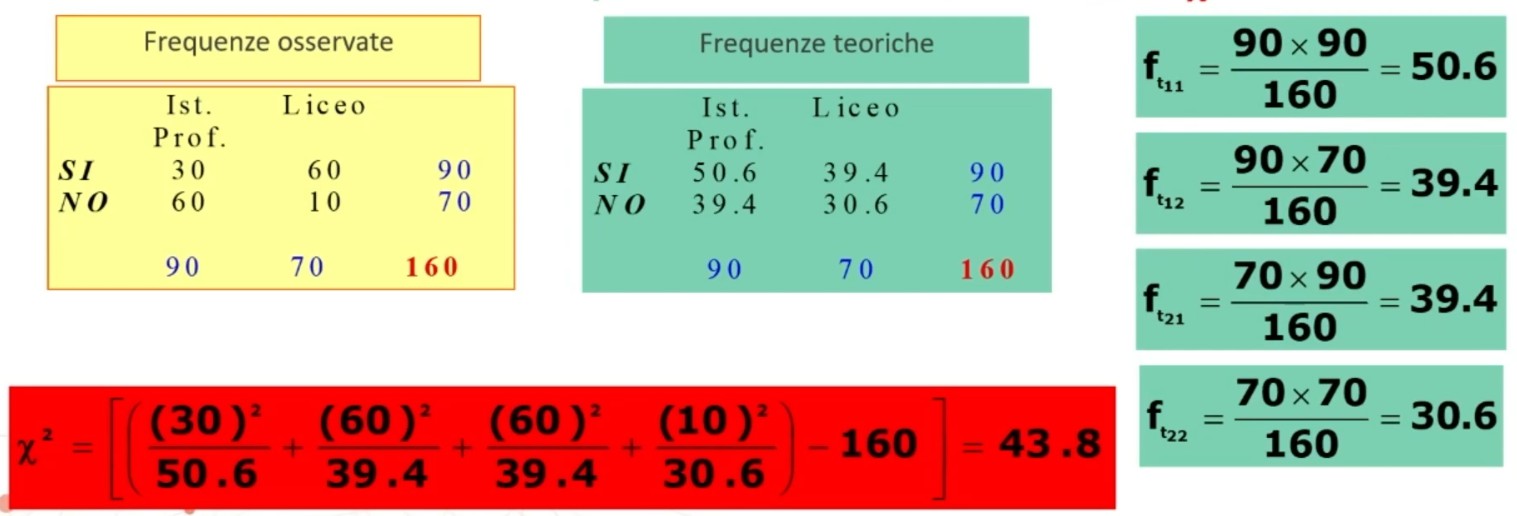
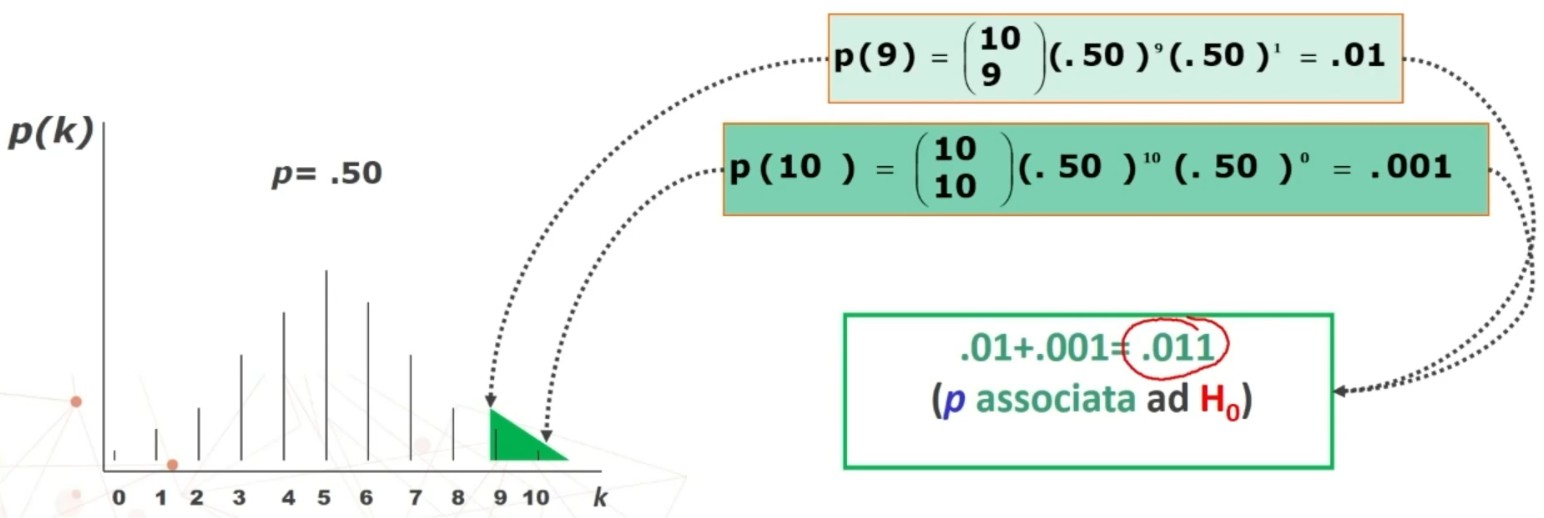
Facciamo un esempio di calcolo. Abbiamo 6 soggetti che hanno compilato un questionario, una volta al tempo T1, e una volta al tempo T2.
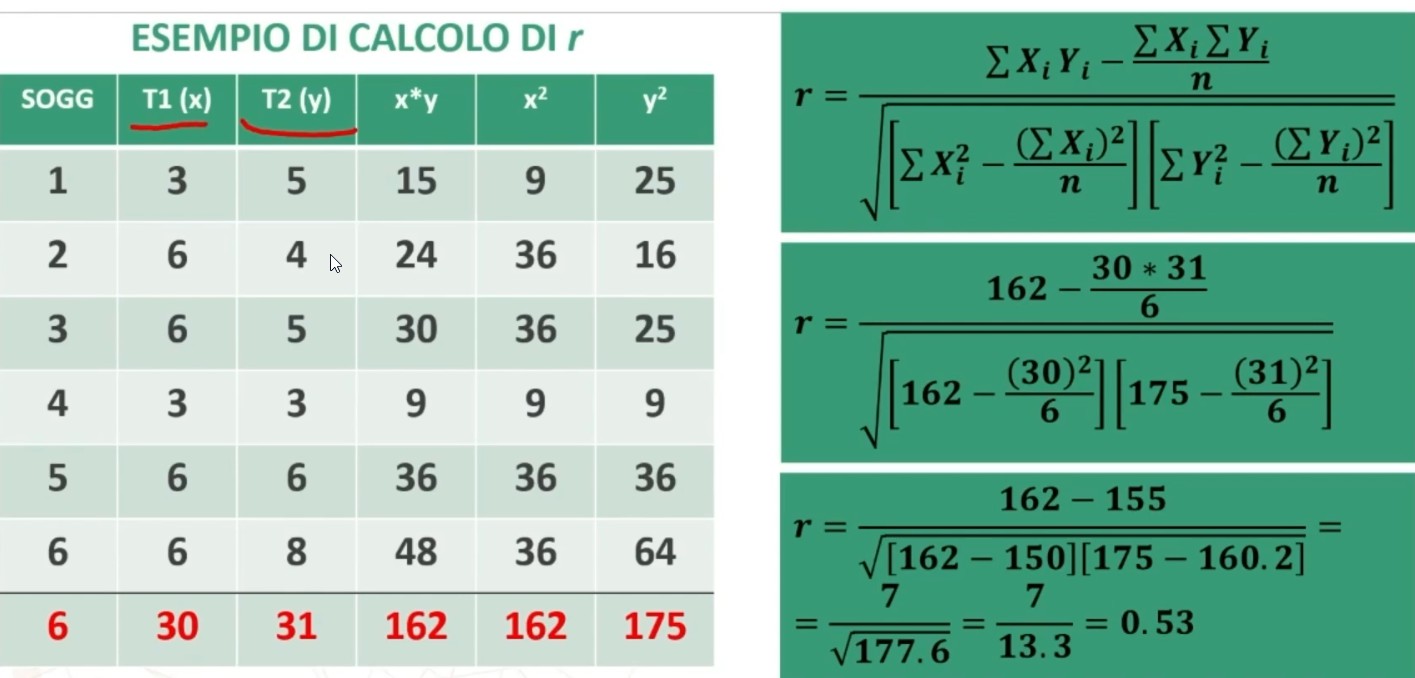
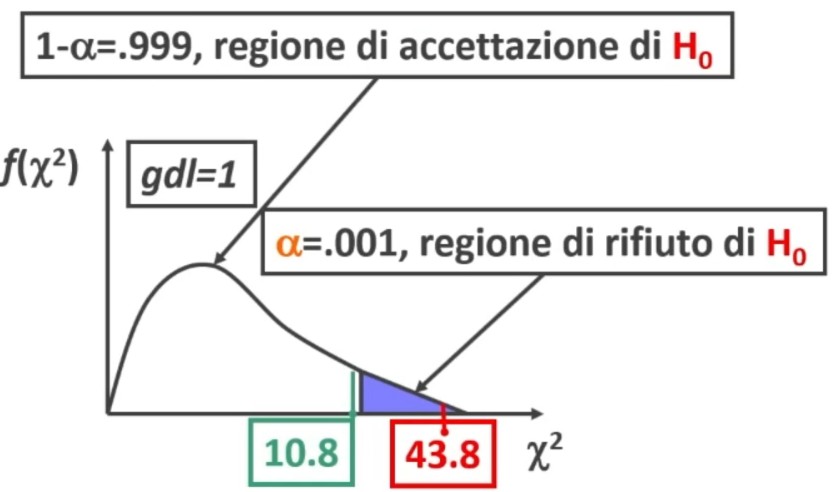
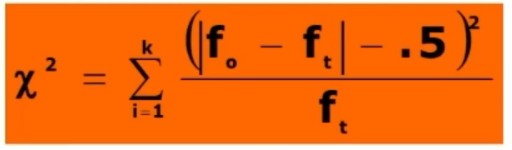
Il coefficiente è 0.53, e ci dice che le misure sono mediamente correlate. In generale ci aspettiamo che la relazione sia molto elevata, almeno 0.70.
Quindi il nostro strumento attraverso il metodo del test-retest non è risultato molto attendibile.
Questo metodo presenta alcuni limiti:
- Un possibile limite alla stima dell’attendibilità attraverso la correlazione test-retest è quello dell’apprendimento da parte di soggetti. Ovvero se somministriamo due volte lo stesso test agli stessi soggetti può generare due fonti di errore.
I soggetti da un lato potrebbero aver imparato a rispondere al test ed è quindi come se fosse somministrato a soggetti diversi durante la seconda somministrazione. Oppure la caratteristica che si sta misurando può essere modificata nel tempo.
Metodo delle forme parallele
Per minimizzare le fonti di errori derivanti dal metodo del test-retest si può usare un nuovo metodo di stima dell’attendibilità che è quello delle forme parallele. Questo metodo si basa sul confrontare, mettere in relazione, due forme parallele dello stesso test. La stima dell’attendibilità avviene con un coefficiente che chiamiamo coefficiente di equivalenza, che non è altro che la r di Pearson.
L’attendibilità, in questo caso, è stimata sull’equivalenza delle due forme.
Facciamo un esempio: si somministrano due versioni equivalenti del test (vuol dire che i test hanno stessa media e stessa dev. st.) al tempo T1 e al tempo T2. La correlazione tra le due forme è una stima dell’attendibilità.
Un ulteriore modo di procedere all’interno delle forme parallele è quello dello split-half.
In questo caso si sommiistra il test in un unico tempo T1. Poi si divide il test a metà e si considerano le due metà come forme parallele (stessa media e stessa deviazione standard)
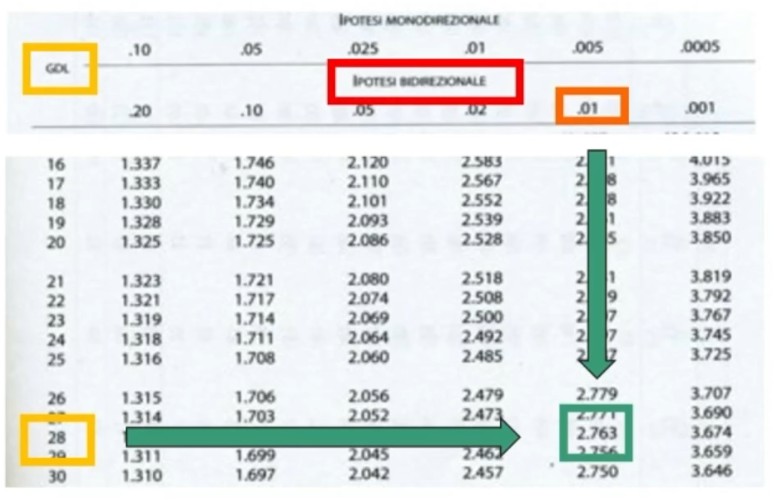
L’attendibilità sarà la r di Pearson, ovvero la correlazione tra le due metà del test. Va corretta con la formula profetica di Spearman-Brown, dato che la vera lunghezza della scala è doppia rispetto a quella delle due metà.
Questa formula (Spearman-Brown) mira a prevedere l’attendibilità di un test al variare della sua lunghezza.
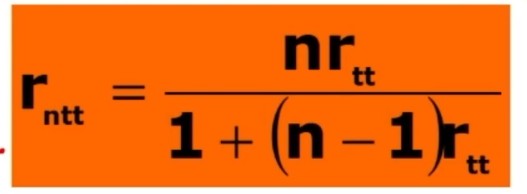
dove:
- rntt = attendibilità della forma ipotetica
- n = rapporto tra numero di item della forma ipotetica e numero di item nella versione già esistente del test
Con la stessa formula possiamo anche risolvere il caso inverso, cioè stimare quanto dovremo allungare o accorciare il test per ottenere un’attendibilità prefissata.

Facciamo un esempio: abbiamo un test composto da 20 item con attendibilità rtt (r di Pearson) = .83
Possiamo stimare l’attendibilità del nostro test se aggiungessimo 8 item con caratteristiche simili ai 20 esistenti.

Quindi se aggiungiamo 8 item la nostra attendibilità salirebbe a .87
Se invece ci poniamo una domanda diversa, ovvero partendo sempre dai 20 item, quanti item dovrei aggiungere per avere un’attendibilità di .90?

dove n = rapporto tra numero di item della forma ipotetica e numero di item nella versione già esistente del test.
Otteniamo 1.84 che è il rapporto tra gli item finali e iniziali.
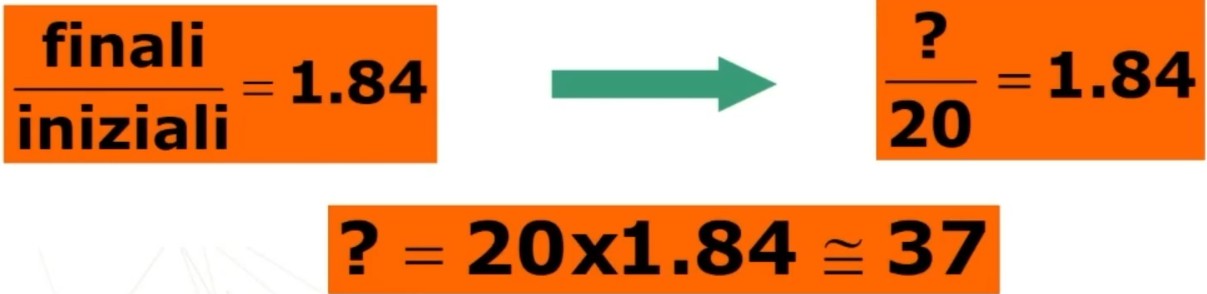
Quindi ricaviamo 37, ovvero occorrerà aggiungere 17 item (20+17=37) per avere un’attendibilità di .90
I limiti nell’utilizzo delle forme parallele sono
- la costruzione di due test paralleli non è facile.
Infatti, due test si dicono paralleli se hanno stessa media, stessa varianza e stessa intercorrelazione tra gli item che li compongono. Situazione che in psicologia non è sempre detto che si verifichi.
Metodo della coerenza interna
Stima attendibilità con il coefficiente α di Cronbach
Quindi il metodo più utilizzato nella ricerca in psicologia per la stima dell’attendibilità è quello della coerenza interna.
Per fare ciò possimao usare il coefficiente alpha di Cronbach.
La procedura è la seguente
- Si somministra il test in un unico tempo T1.
- Ogni item viene considerato un test a sé stante.
- Si stima (con apposite formule) la correlazione media tra tutti gli item, e si riassume la coerenza degli indicatori tramite l’indice α di Cronbach.
Questo è spesso il metodo più utilizzato in psicologia.
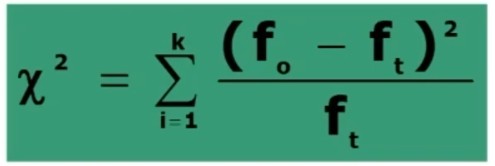
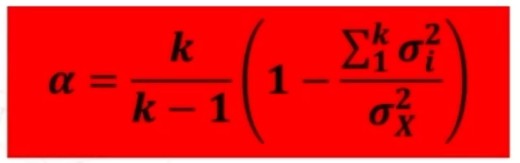
Il coefficiente α di CRONBACH concettualmente è il rapporto fra la varianza della scala totale rispetto alla somma delle varianze dei singoli item.
Quando si utilizza questo coefficiente? Quando abbiamo degli item politomici (non dicotomici, che hanno più livelli).
Questo coefficiente
- Varia fra 0 e 1. Valori superiori a .70 sono considerati buoni.
- All’aumentare del numero degli item, tende ad aumentare avvicinandosi asintoticamente a 1.
La sua formula è:
Stima attendibilità con il coefficiente K-R20 di Kuder-Richardson
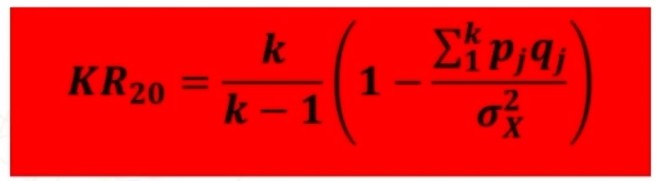
Quando invece abbiamo a che fare con degli item che sono dicotomici utilizziamo il coefficiente K-R20 di Kuder-Richardson.
Concettualmente identico ad alpha di Cronbach. Varia fra 0 e 1. Valori superiori a .70 sono considerati buoni. Infine all’aumentare del numero degli item, tende ad aumentare avvicinandosi asintoticamente a 1.
Errore standard di misura
Abbiamo visto che l’attendibilità (o fedeltà) riguarda la precisione dello strumento.
Tutte le misure sono affette da errori dovuti al caso: il dato osservato X è costituito da una parte che corrisponde alla misura “vera” V e da una parte di errore casuale E.
Una misura è attendibile quando si dimostra che tali errori di misura incidono in piccola parte, cioè che E sia molto piccolo e quindi il dato osservato X sia molto vicino al valore V.
Tuttavia, sappiamo che non è possibile conoscere effettivamente la varianza della parte “vera”, per cui l’attendibilità dei test psicologici è da considerarsi sempre una stima.
In altre parole, l’intrinseca imprecisione di qualunque strumento implica che ogni punteggio ottenuto è accompagnato da un errore casuale.
Per tenere conto di tale errore dobbiamo considerare un margine entro il quale possiamo considerare accettabile la stima.
Tale margine è quantificato attraverso l’errore standard di misura.
Quindi l‘errore standard di misura è la stima delle deviazioni standard dei punteggi osservati intorno al punteggio vero.
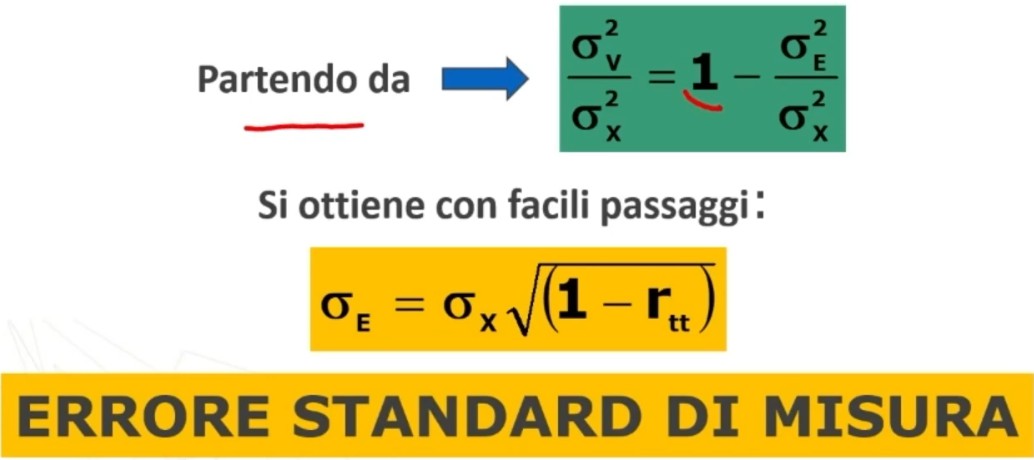
dove σx è la deviazione standard del punteggio osservato x, rtt è l’attendibilità.
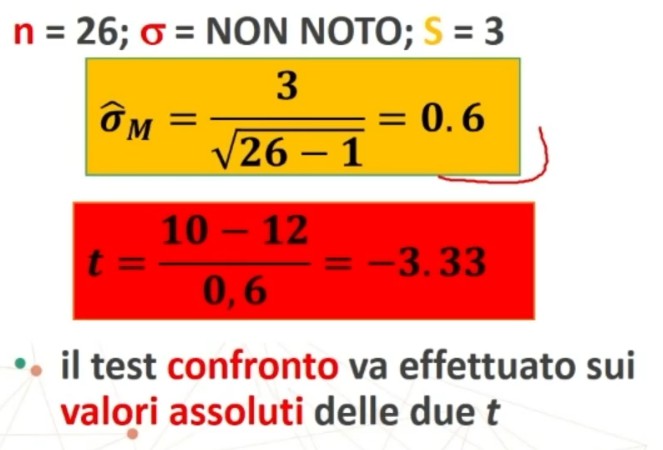
Facciamo un esempio: supponiamo di avere un test del quale conosciamo l’attendibilità rtt = .82 e la varianza σ²x = 9. Vogliamo conoscere l’errore standard di misura del test. Applichiamo la formula.
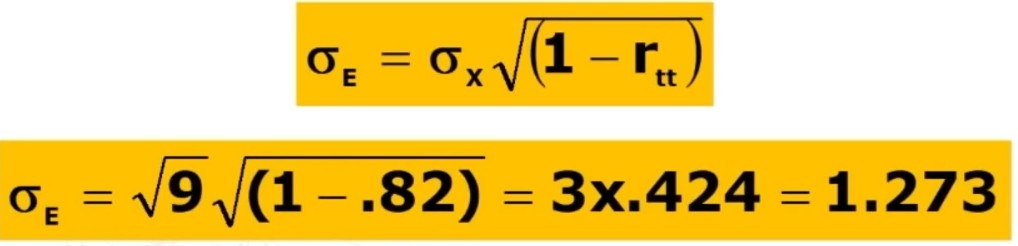
Uso dell’errore standard di misura
Intervallo di fiducia per il punteggio vero
Questo intervallo è il margine entro il quale possiamo considerare accettabile la stima.
Partendo dal punteggio ottenuto da un soggetto ad un test, conoscendo l’errore standard del test, possiamo ricavare l’intervallo di fiducia all’interno del quale cadrà il punteggio vero V del soggetto se si ripetesse il test un numero infinito di volte.
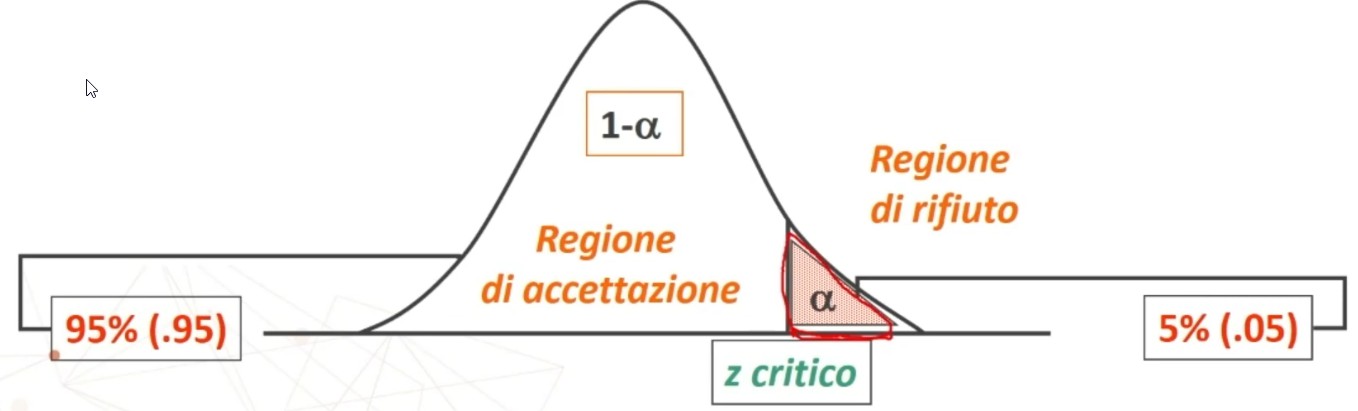
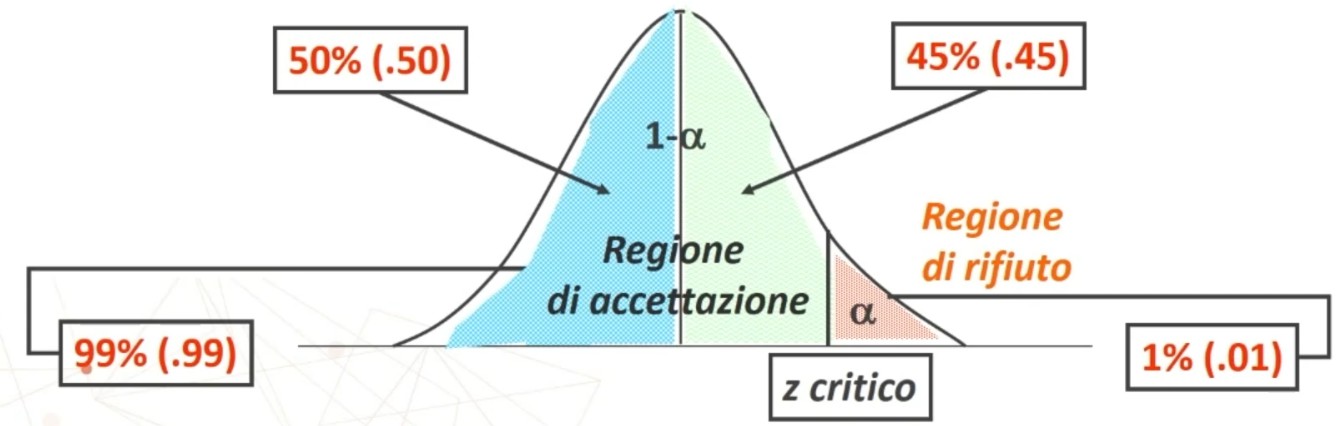
Assumiamo che la distribuzione dei punteggi osservati intorno al punteggio vero sia normale e usiamo le proprietà della curva per stimare l’intervallo di confidenza al 95% della posizione di V.
Vediamo come determinare gli intervalli di confidenza

Di seguito la formula per il calcolo dei limiti dell’intervallo di fiducia (o di confidenza)
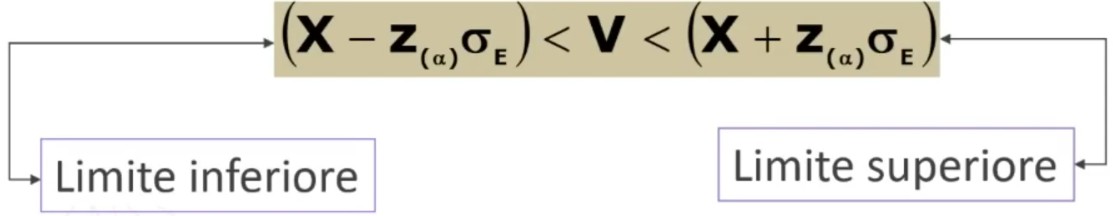
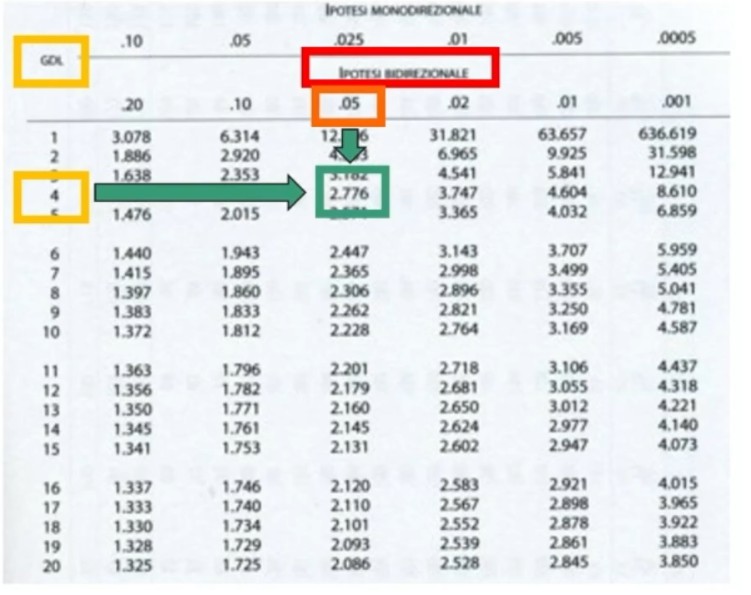
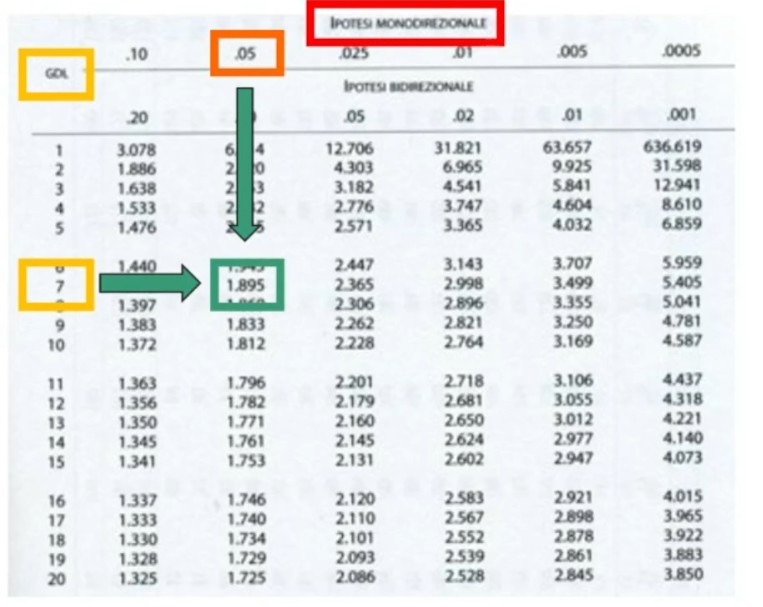
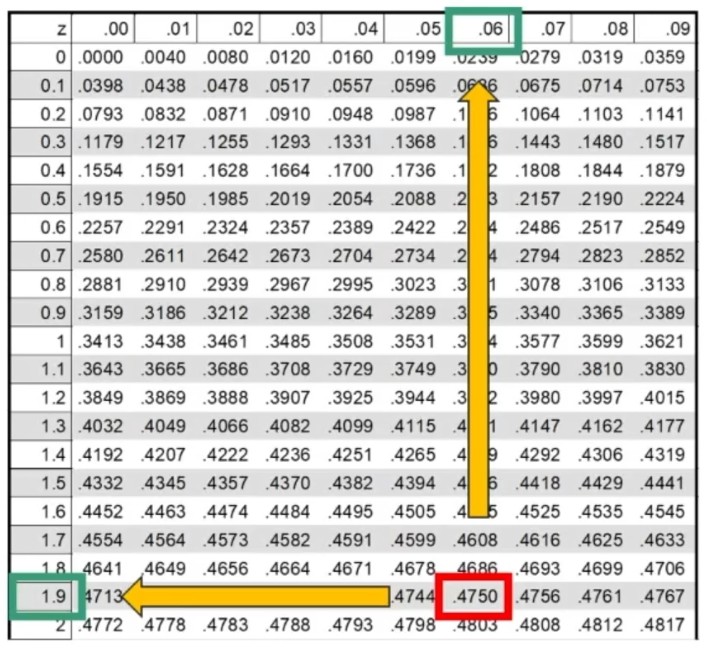
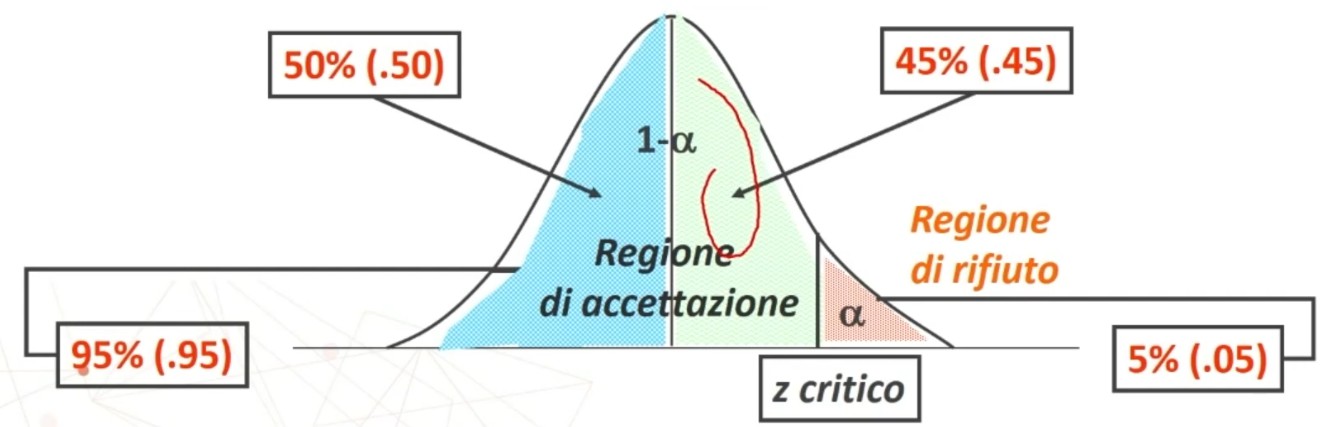
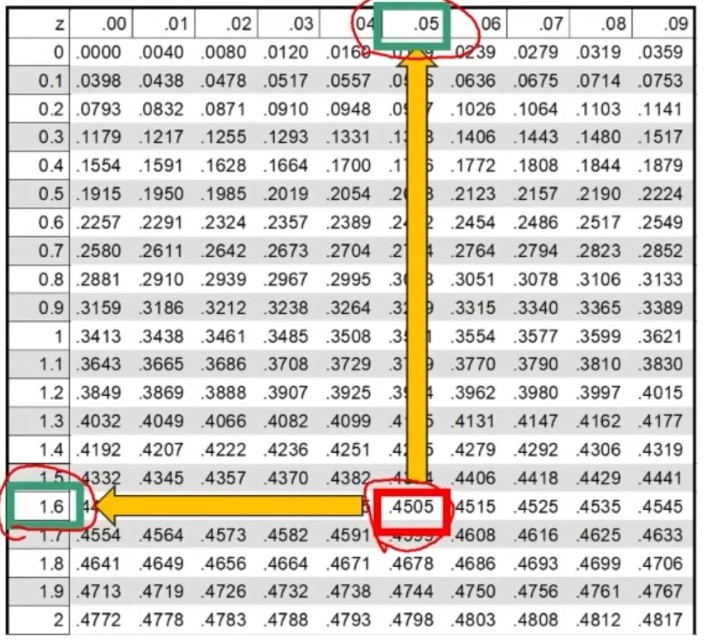
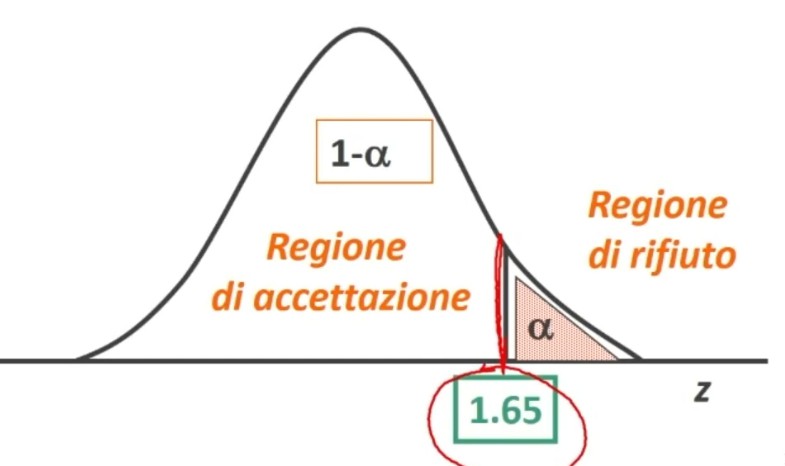
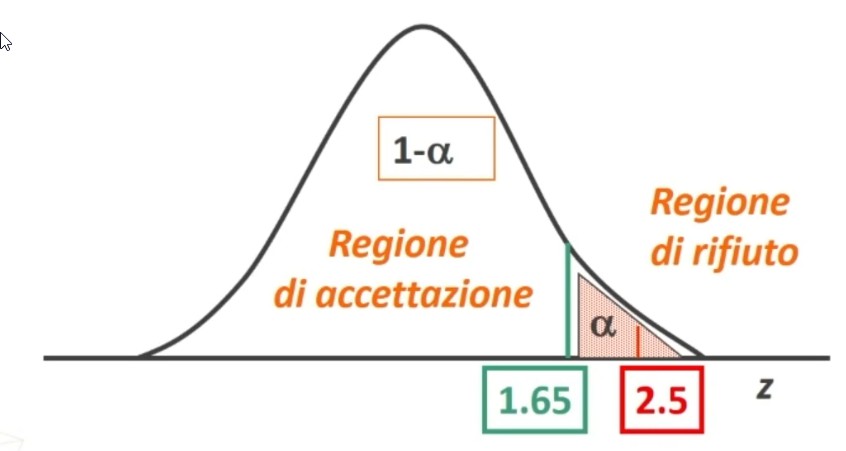
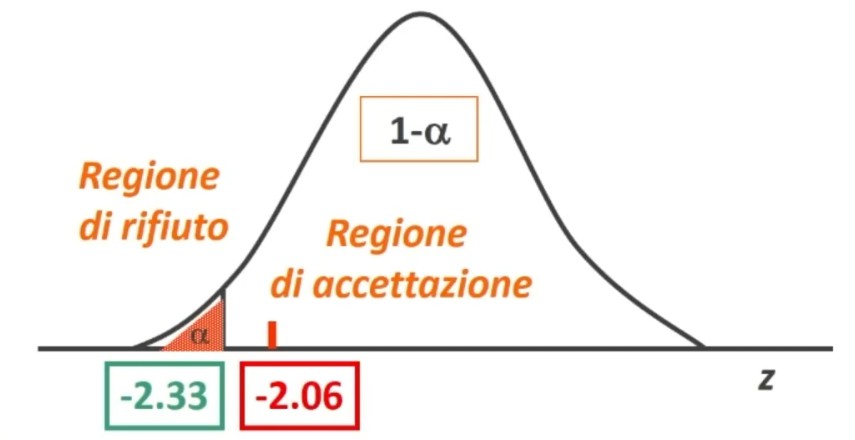
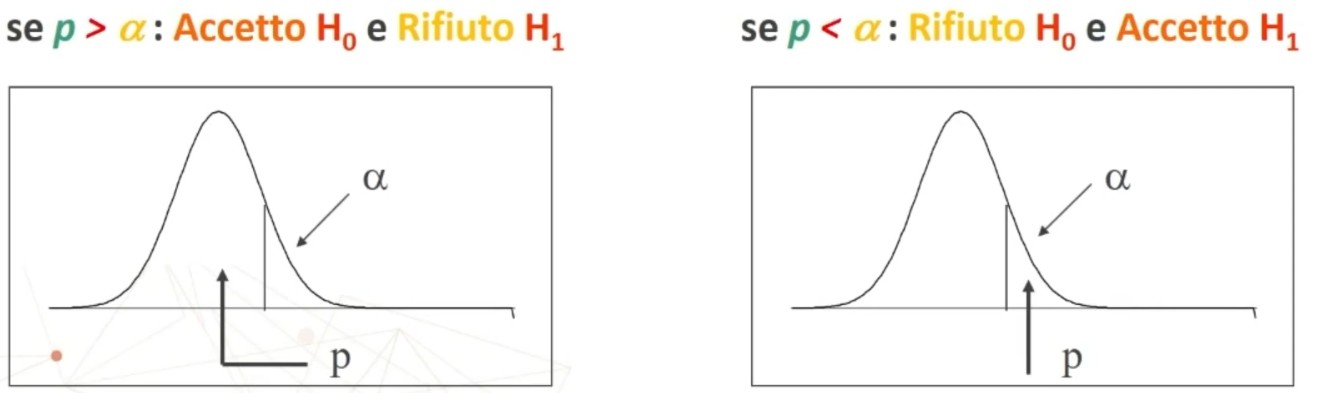
Dove zα è il valore critico di z per α prefissato (es., α = .05 → zα = 1.96).
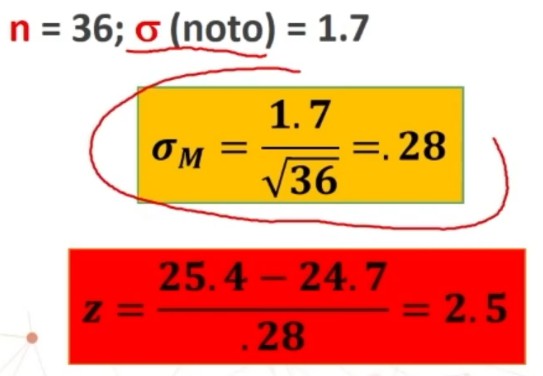
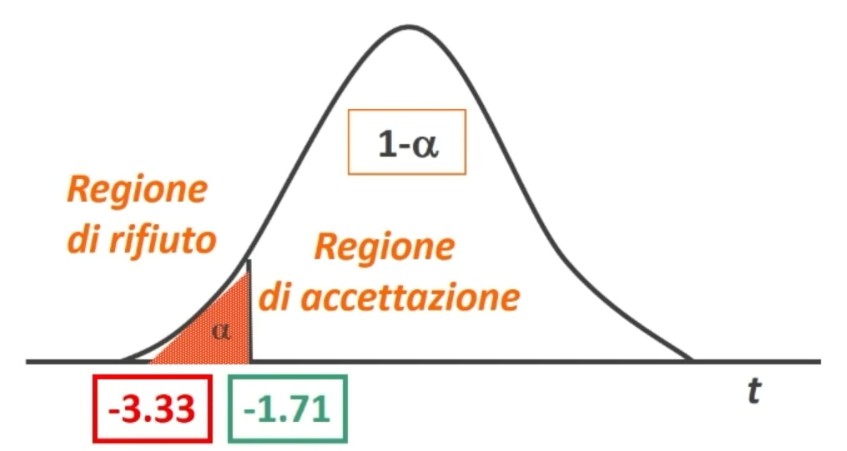
Facciamo un esempio: Otteniamo un punteggio pari a 108. L’errore standard è 1.12. In quale ambito cade il suo punteggio vero con un margine di fiducia del 95%?
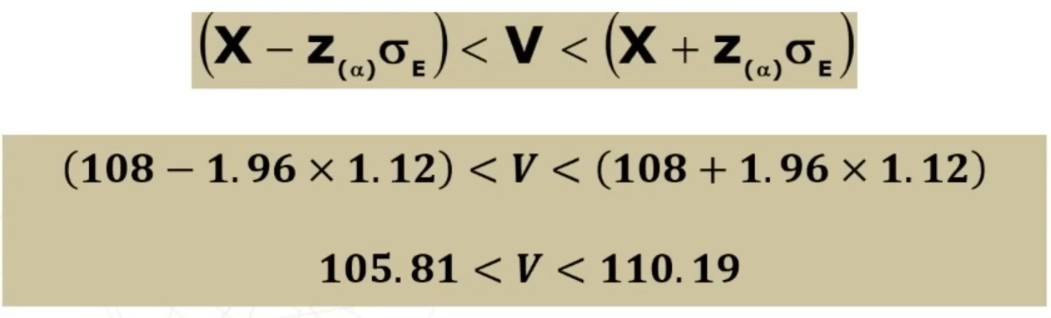
L’intervallo di fiducia per il punteggio vero V è compreso tra 105.81 e 110.19.