Table of Contents
- Statistica inferenziale
- Formulazione delle ipotesi
- Decisione su H0
- Regole di decisione
- Potenza del test
- Riassunto Mistral
Statistica inferenziale
Sappiamo che la statistica inferenziale ha due obiettivi: la verifica delle ipotesi e dei parametri.
- Teoria della verifica dell’ipotesi: si verifica, in termini probabilistici, se una certa affermazione relativa alla popolazione è da ritenersi vera sulla base dei dati campionari
- Teoria della stima dei parametri: si stabilisce, in termini probabilistici, il valore numerico di uno o più parametri incogniti della popolazione a partire dai dati campionari
Per verificare le ipotesi possiamo procedere con le seguenti fasi
- Formulazione Ipotesi Statistiche
- Estraggo un campione in modo casuale
- Misuro sul campione la statistica che definisce la mia ipotesi
- Con la STATISTICA INFERENZIALE definisco, in termini probabilistici, la validità della mia ipotesi sulla popolazione a partire dalle statistiche del campione
Formulazione delle ipotesi
Il primo passo da compiere per procedere alla verifica di un’ipotesi è quello della sua formulazione.
Essa viene declinata attraverso due ipotesi:
- H₀: ipotesi nulla (“non c’è effetto”) non ci sono differenze tra popolazione e campione, o tra due campioni
- H₁: ipotesi alternativa, o sostantiva, o sperimentale (“qualche effetto c’è”)
Per verificare un’ipotesi (H₁) che afferma la presenza di effetti, si assume che sia invece vera un’ipotesi contraria (H₀), che nega la presenza di effetti. Si utilizza dunque una logica falsificazionista.
Si calcola la probabilità di osservare il valore “sperimentale” assunto come vera l’ipotesi nulla.
Se tale probabilità è bassa si decide che H₀ è forse falsa, e H₁ è relativamente più verosimile.
Bisogna però ricordare che H₀ può essere vera, e che noi abbiamo semplicemente sbagliato campionamento.
Facciamo un esempio. Due diverse terapie garantiscono diversa efficacia?
- H₀ (ipotesi nulla): non esiste una differenza tra due terapie
- H₁ (ipotesi alternativa): esiste una differenza tra due terapie
Si cerca di falsificare probabilisticamente l’ipotesi che non vi siano differenze (H₀) per dimostrare che la differenza c’è (H₁).
L’ipotesi sperimentale H₁ può essere:
- Semplice: si fissa un unico valore del parametro
- Composta: si fissano diversi valori possibili del parametro
- MONODIREZIONALE (una coda): prevede la direzione della differenza
- BIDIREZIONALE (due code): non prevede direzione
Per riassumere
- le medie in H0 sono identiche
- se semplice media può assumere valore 60 (valore a caso)

Una volta definite le nostre ipotesi sappiamo che i prossimi passi sono
- estraggo un campione in modo casuale
- misuro sul campione la statistica che definisce la mia ipotesi
- Con la STATISTICA INFERENZIALE definisco, in termini probabilistici, la validità della mia ipotesi sulla popolazione a partire dalle statistiche del campione
Prendo quindi una decisione (in base alla teoria della probabilità) circa la veridicità di H₀ e H₁. Tale decisione è:
- Sempre soggetta ad errore
- Si assume a priori un rischio accettabile (poco probabile) di errore
Decisione su H0
Come faccio a prendere la mia decisione su H0 (ipotesi nulla)?
Si calcola la probabilità associata agli eventi osservati posto che H₀ sia vera.
- Se la probabilità è alta accetto H₀
- Se la probabilità è bassa respingo H₀ e accetto H₁
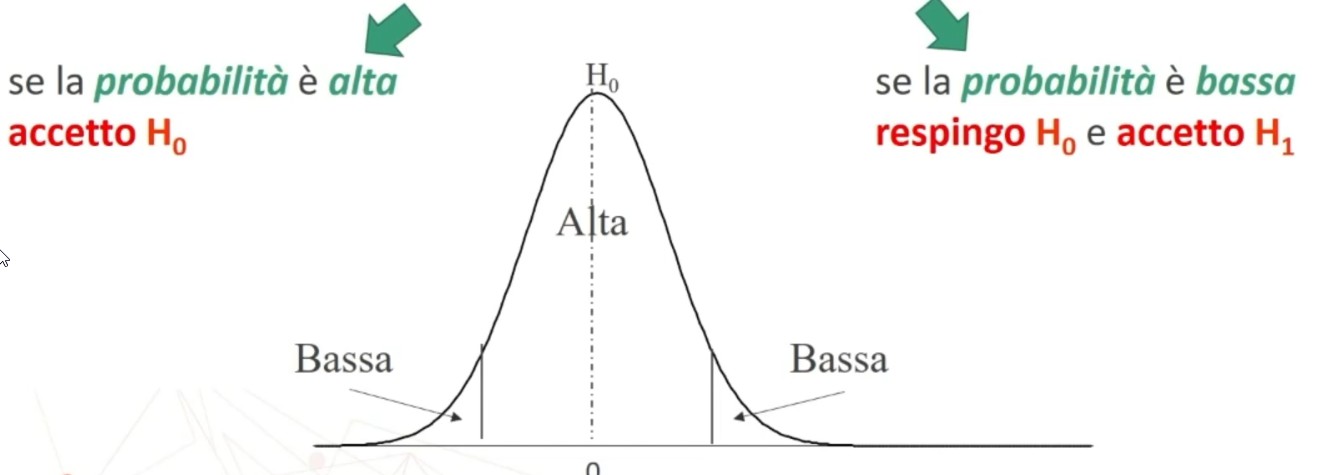
A questo punto dovrebbe sorgere spontanea una domanda: Come si stabilisce che la probabilità associata a H₀ è alta o bassa?
Si definiscono dei limiti probabilistici:
- Entro certi livelli di probabilità accetto H₀
- Oltre certi livelli di probabilità rifiuto H₀
Questi limiti sono dati dal livello di significatività = α. Alfa è l’area sotto la curva e:
- definisce la regione di rifiuto di H₀: α è una probabilità e definisce la Regione della distribuzione campionaria composta dai risultati che hanno una probabilità molto bassa di essere osservati quando H₀ è vera
- definisce la regione di accettazione di H₀: Regione della distribuzione campionaria composta dai risultati che hanno una probabilità molto alta di essere osservati quando H₀ non è vera (1 – α)
Osserviamo le regioni di accettazione e rifiuto per ipotesi monodirezionali
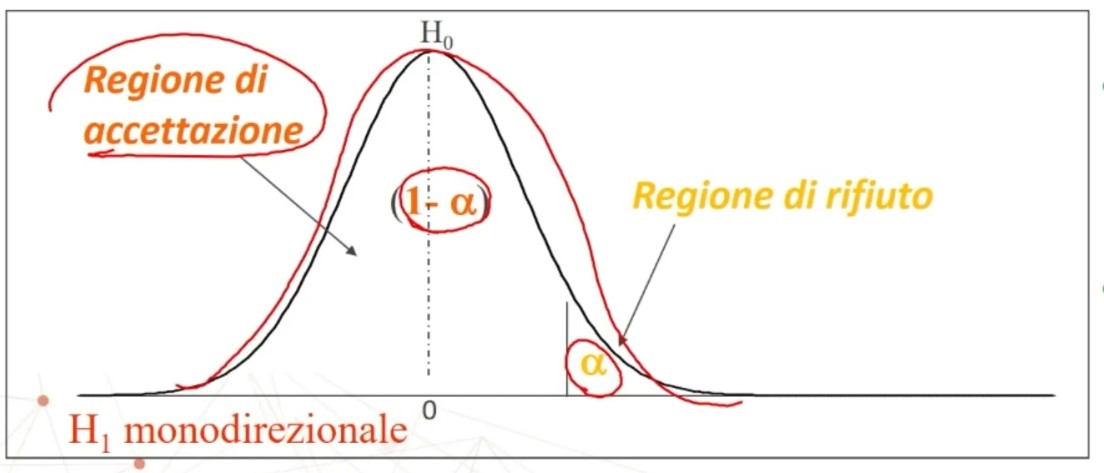
è importante ricordare che
- L’area sotto la curva rappresenta una probabilità
- L’asse delle ascisse rappresenta una statistica (z o t, o chi quadrato…)
Ora osserviamo le regioni di accettazione e rifiuto per ipotesi bidirezionali
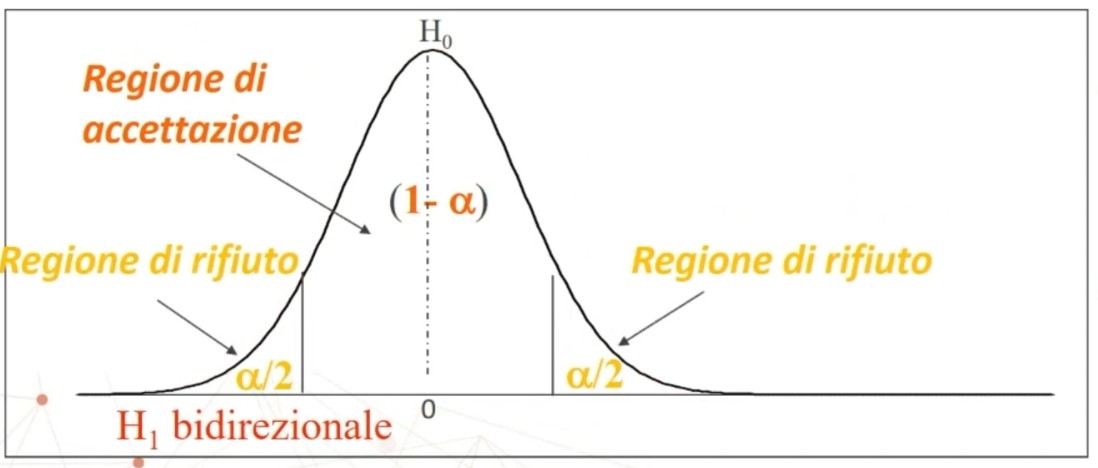
RICORDA!
- L’area sotto la curva rappresenta una probabilità
- L’asse delle ascisse rappresenta una statistica (z o t, o chi quadrato…)
Sia p il valore di probabilità calcolato per l’evento osservato:
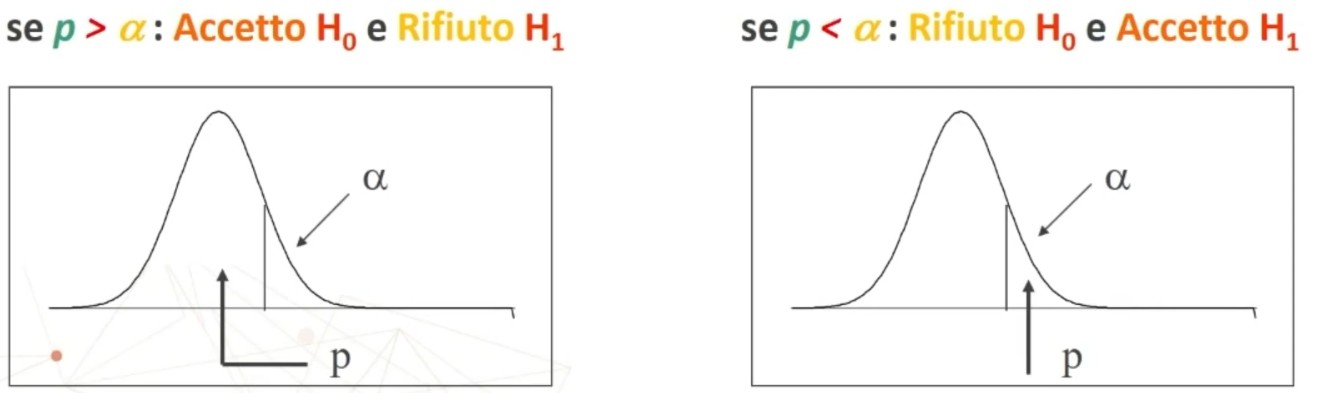
Regole di decisione
Dobbiamo ricordarci che le regole di decisione sono su base probabilistica, la decisione non è mai certa.
La decisione è sempre soggetta ad errore. Il rischio di errore che ci sentiamo di correre è rappresentato da α.
Nello stabilire il livello di α stiamo stabilendo il rischio che siamo disposti a correre di commettere l’errore di respingere H₀ quando è vera (ovvero respingere h0 quando in realtà non dovrebbe essere respinta). Questo genere di errore si dice Errore di I° Tipo.
Per questo motivo si tende a stabilire un valore di α basso:
- È preferibile non affermare l’esistenza di un fenomeno se non si è probabilisticamente “sicuri” della sua presenza
- “Andare presso” a risultati apparentemente significativi (che dipendono da eccessivo errore di campionamento) è scientificamente una perdita di tempo

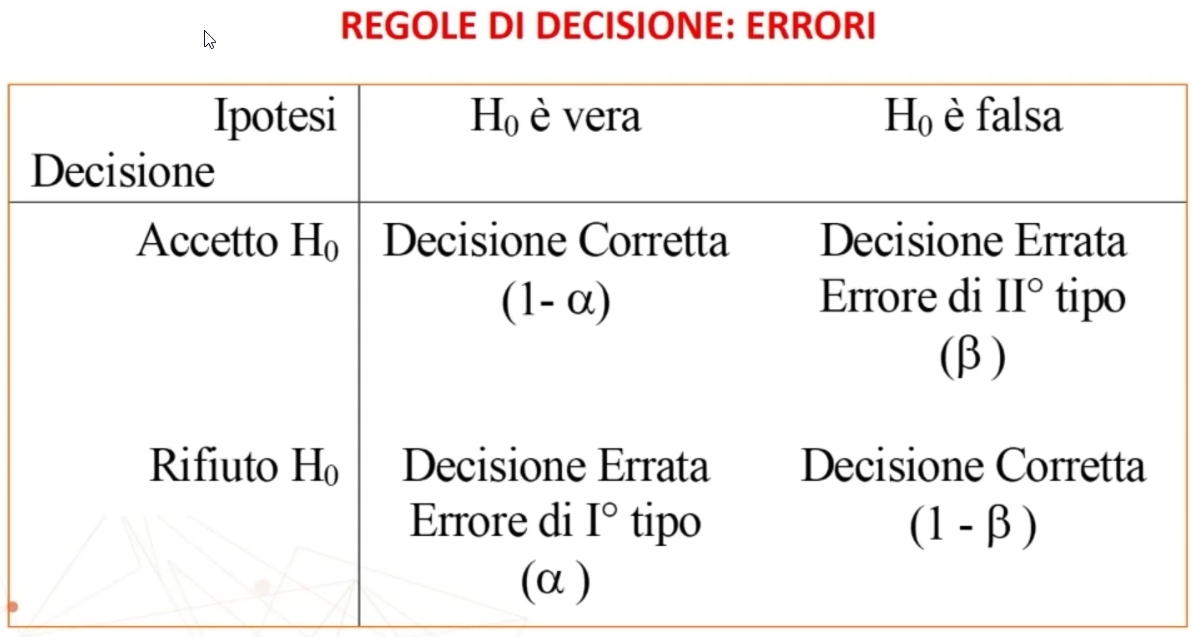
Se H₀ è vera:
- Si può decidere di accettare H₀ = Decisione corretta
- Si può decidere di rifiutare H₀ = Decisione scorretta (Errore di I° tipo)
In soldoni l’errore di I° Tipo si verifica quando
- Rifiuto H₀ quando è vera
- Accetto H₁ quando è falsa
Commetendo l’errore di I tipo si considera presente (vero) un effetto assente (falso) nella popolazione. La probabilità di questo errore è α:
- α = probabilità di evidenziare un fenomeno che in realtà non esiste
- α = probabilità di rintracciare un effetto presente solo in un campione (per errore di campionamento), ma assente nella popolazione di riferimento
Se H₀ è falsa:
- Si può decidere di rifiutare H₀ = Decisione corretta
- Si può decidere di accettare H₀ = Decisione scorretta (Errore di II° tipo)
Quindi l’ERRORE DI II° TIPO si verifica quando:
- Accetto H₀ quando è falsa
- Rifiuto H₁ quando è vera
Quindi nell’errore di 2 tipo si considera assente (falso) un effetto presente (vero) nella popolazione di riferimento.
La probabilità di questo errore è β:
- β = probabilità di non evidenziare un fenomeno che in realtà esiste
- β = probabilità di non rintracciare un effetto assente solo nel campione, ma in realtà presente nella popolazione di riferimento
Purtroppo il valore di β, a differenza di quello di α, non può essere determinato.
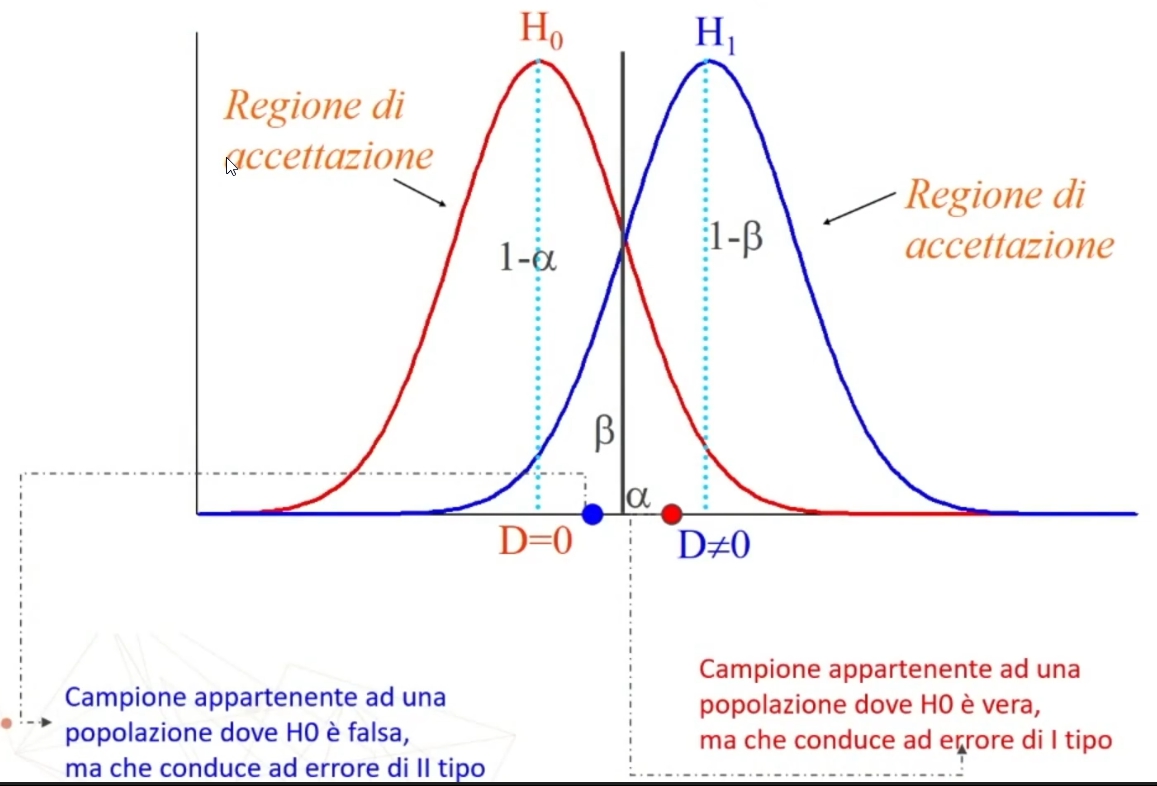
Sopra rappresentate le distribuzioni di h0 e h1.
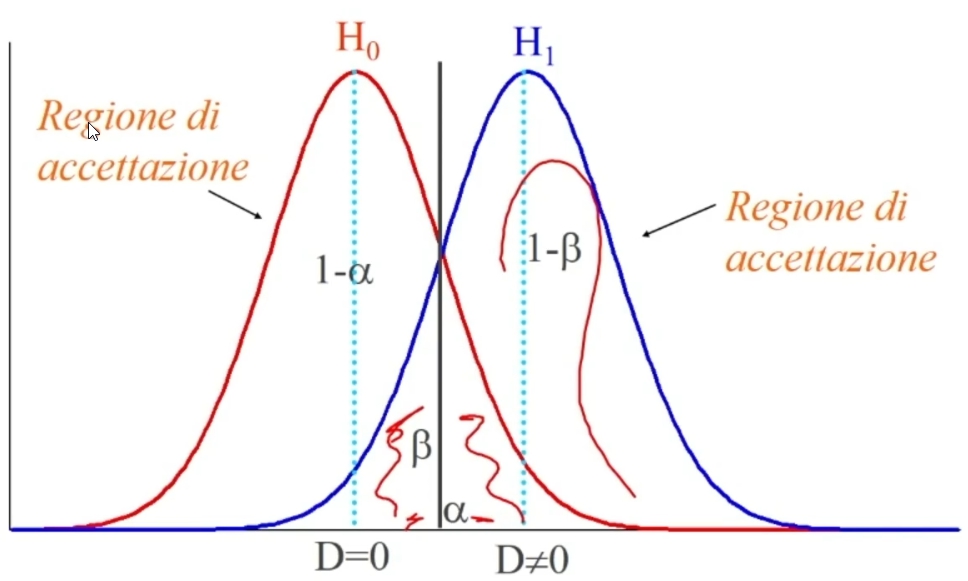
La regione di accettazione di H0 sarà dato da 1-alpha. In maniera simile la regione di acettazione di H1 sarà dato da 1-beta.
Se α diminuisce, β aumenta. Evitare errori di I° tipo può portare ad una elevata probabilità di commettere errori di II° tipo.
Riassumendo possiamo dire
Potenza del test
La potenza del test (ovvero la Capacità del test di arrivare alla decisione corretta) è la probabilità di respingere H₀ quando è vera H₁:
La potenza del test è data da 1 – β
La potenza del test è determinata da diversi parametri
- ampiezza del campione (è il parametro più importante)
- grandezza dell’effetto
- la potenza è in parte influenzata dal tipo di analisi statistica effettuata. L’applicabilità delle tecniche di analisi dipende a sua volta da:
- Livello di misura
- Grandezza campione
- Distribuzione
Riassunto Mistral
La verifica delle ipotesi è uno dei concetti fondamentali in statistica e psicometria, e comprendere H₀ (ipotesi nulla), H₁ (ipotesi alternativa), e gli errori di primo e secondo tipo è essenziale per interpretare correttamente i risultati di un test statistico. Provo a spiegartelo in modo chiaro e pratico.
1. Cos’è la verifica delle ipotesi?
È un metodo statistico per prendere decisioni su una popolazione basandosi su un campione. L’obiettivo è stabilire se c’è abbastanza evidenza nei dati per rifiutare o non rifiutare un’ipotesi predefinita (di solito l’ipotesi nulla, H₀).
2. Le ipotesi: H₀ e H₁
- H₀ (Ipotesi nulla):
- Rappresenta lo status quo, l’assenza di effetto o di differenza.
- Esempio: “Non c’è differenza tra i punteggi medi di due gruppi” o “Il trattamento non ha effetto”.
- Presunzione di innocenza: in statistica, partiamo sempre assumendo che H₀ sia vera, fino a prova contraria.
- H₁ (Ipotesi alternativa):
- Rappresenta l’effetto o la differenza che vogliamo dimostrare.
- Esempio: “C’è differenza tra i punteggi medi dei due gruppi” o “Il trattamento ha effetto”.
- Può essere unidirezionale (es. “il punteggio del gruppo A è maggiore di quello del gruppo B”) o bidirezionale (es. “c’è differenza tra i due gruppi”).
3. Gli errori nella verifica delle ipotesi
Quando prendiamo una decisione (rifiutare o non rifiutare H₀), possiamo commettere due tipi di errore:
| Decisione | H₀ è vera | H₀ è falsa |
|---|---|---|
| Non rifiutiamo H₀ | ✅ Corretto | ❌ Errore di II tipo (β) |
| Rifiutiamo H₀ | ❌ Errore di I tipo (α) | ✅ Corretto |
Errore di primo tipo (α, “falso positivo”)
- Cosa succede? Rifiutiamo H₀ quando in realtà è vera.
- Esempio: Concludiamo che un trattamento funziona (H₁), ma in realtà non ha alcun effetto (H₀ vera).
- Probabilità: α (livello di significatività, di solito 0.05 o 5%).
- Controllo: Lo fissiamo a priori (es. α = 0.05). Più α è basso, meno probabile è commettere questo errore.
Errore di secondo tipo (β, “falso negativo”)
- Cosa succede? Non rifiutiamo H₀ quando in realtà è falsa.
- Esempio: Concludiamo che il trattamento non funziona (H₀), ma in realtà funziona (H₁ vera).
- Probabilità: β (dipende dalla dimensione del campione, dalla variabilità dei dati e dalla differenza reale tra le ipotesi).
- Controllo: Aumentando la potenza statistica (1 – β) del test, riduciamo β. La potenza dipende da:
- Dimensione del campione (più grande = più potenza).
- Livello di significatività (α più alto = più potenza, ma anche più rischio di errore di I tipo).
- Effetto reale (più grande è la differenza/effetto, più facile da rilevare).
4. Relazione tra α, β e potenza
- α e β sono inversamente correlati: se riduci α (es. da 0.05 a 0.01), β aumenta (e viceversa), a parità di altre condizioni.
- Potenza (1 – β): Probabilità di rifiutare correttamente H₀ quando è falsa. Un test con alta potenza ha meno rischio di errore di II tipo.
5. Esempio pratico
Contesto: Vuoi testare se un nuovo metodo di studio migliora i punteggi di un test rispetto al metodo tradizionale.
- H₀: “Il nuovo metodo non migliora i punteggi (differenza media = 0)”.
- H₁: “Il nuovo metodo migliora i punteggi (differenza media > 0)”.
Risultati possibili:
- Rifiuti H₀ (concludi che il metodo funziona):
- Se H₀ era vera → Errore di I tipo (falso positivo).
- Se H₀ era falsa → Decisione corretta.
- Non rifiuti H₀ (concludi che il metodo non funziona):
- Se H₀ era vera → Decisione corretta.
- Se H₀ era falsa → Errore di II tipo (falso negativo).
6. Come ridurre gli errori?
- Errore di I tipo (α): Fissare un livello di significatività rigoroso (es. α = 0.01 invece di 0.05).
- Errore di II tipo (β): Aumentare la dimensione del campione o usare test più sensibili.