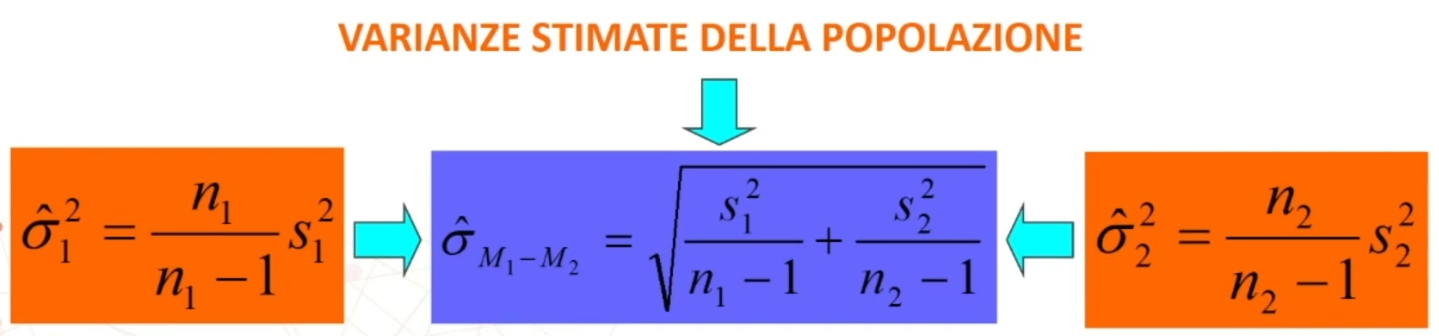
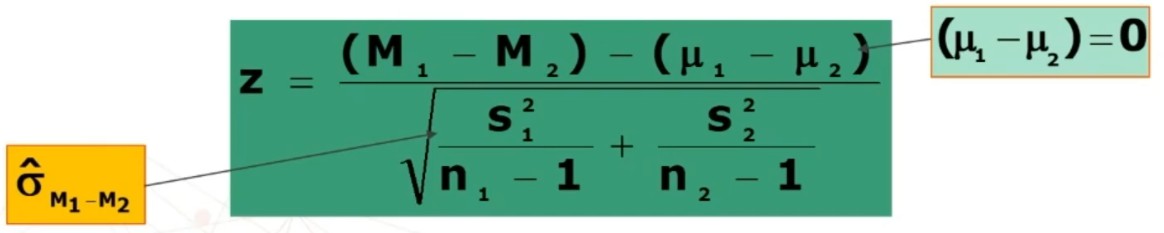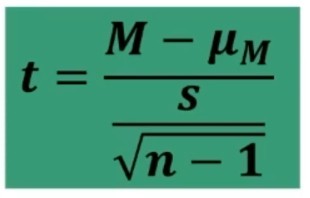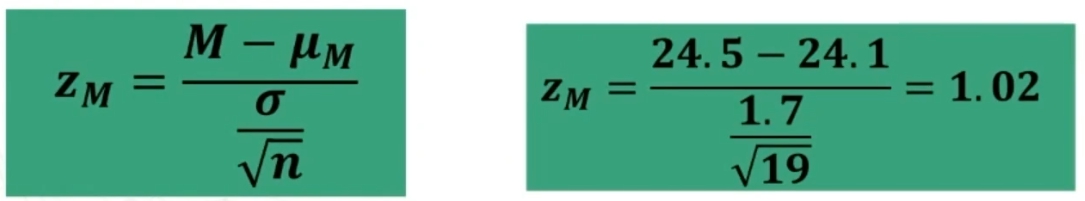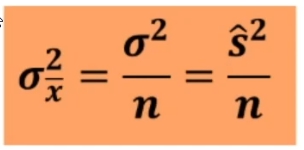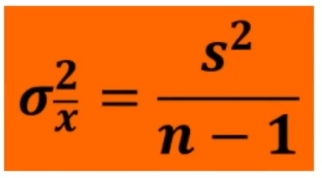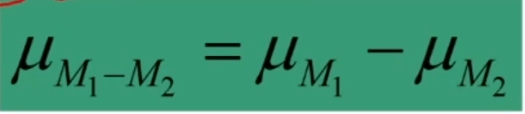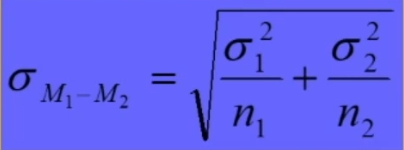Table of Contents
- Verifica delle ipotesi con χ²: il caso di un campione
- Verifica delle ipotesi con X2: il caso di due campioni
Verifica delle ipotesi con χ²: il caso di un campione
Per capire l’utilità del test con χ² andiamo a fare un esempio.
Immaginiamo di avere un campione di 120 depressi (Maschi 42 e femmine 78). Possiamo dire che la depressione ha un’incidenza maggiore fra le donne?
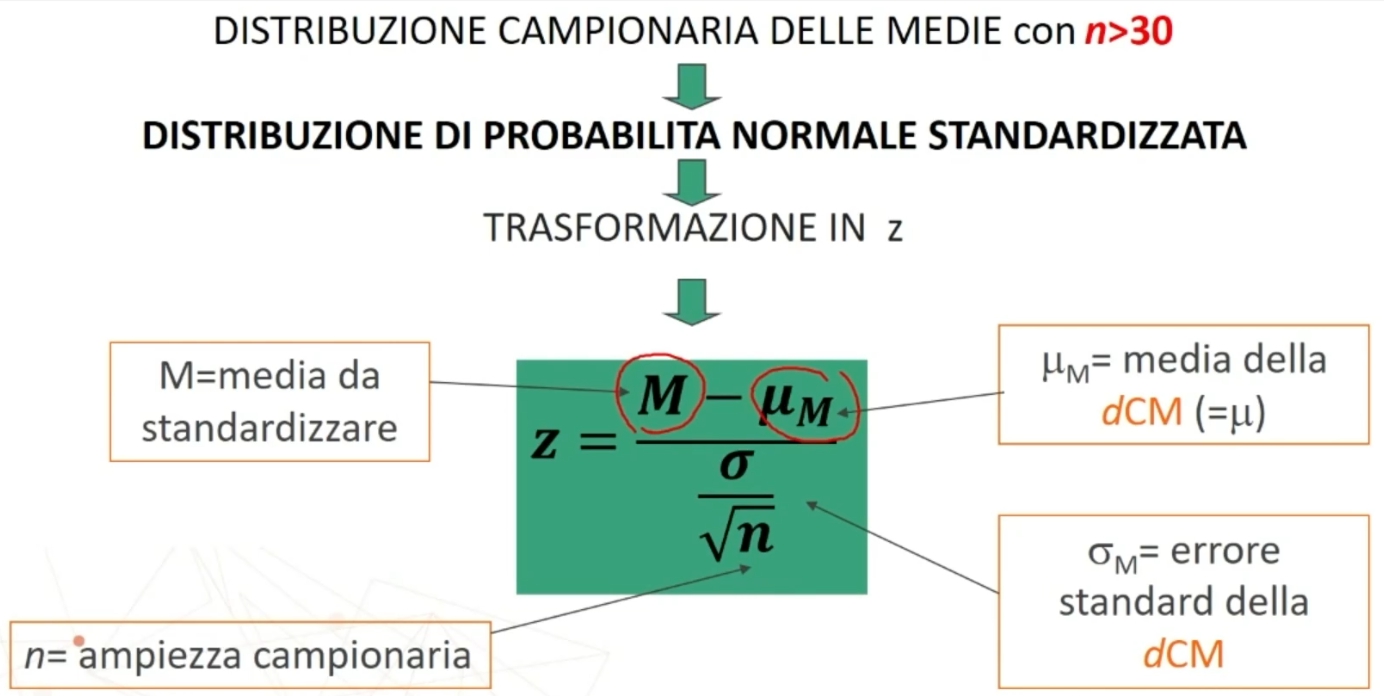
La statistica del chi quadro χ² consente di confrontare una distribuzione teorica (frutto di un modello supposto vero sulla popolazione) e una distribuzione osservata (nel campione).
Ci troveremo quindi di fronte a u disegno di ricerca con
- 1 variabile con k categorie (⇒ e quindi 1 solo campione)
- una distribuzione di frequenza con k categorie
Questa distribuzione di frequenze osservata nel campione la andremo a confrontare con la distribuzione teorica del chi quadro, della quale i valori sono tabulati.
Quindi ciò che si valuta, attraverso il campione estratto dalla popolazione, è la probabilità che il modello risulti vero nella popolazione.
Uno dei modelli sottoposti a verifica è quello dell’equidistribuzione (gli n casi del campione si distribuiscono equamente nelle k categorie, fₜ = fₒ = … fₖ).
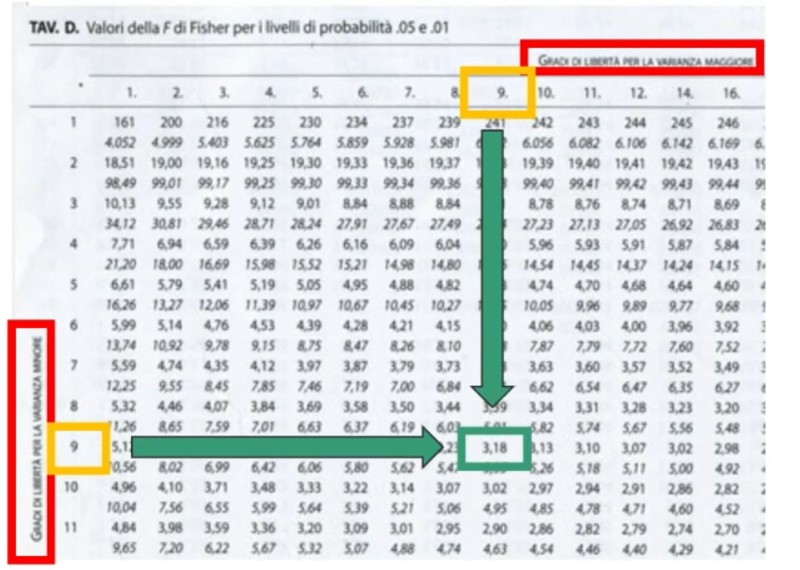
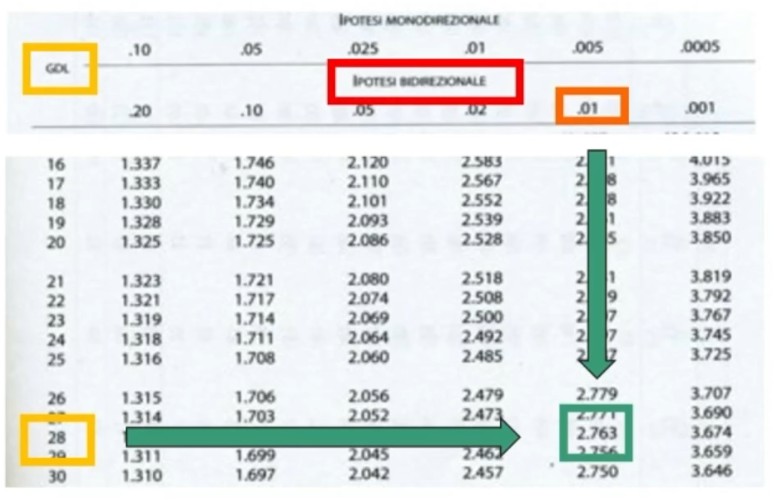
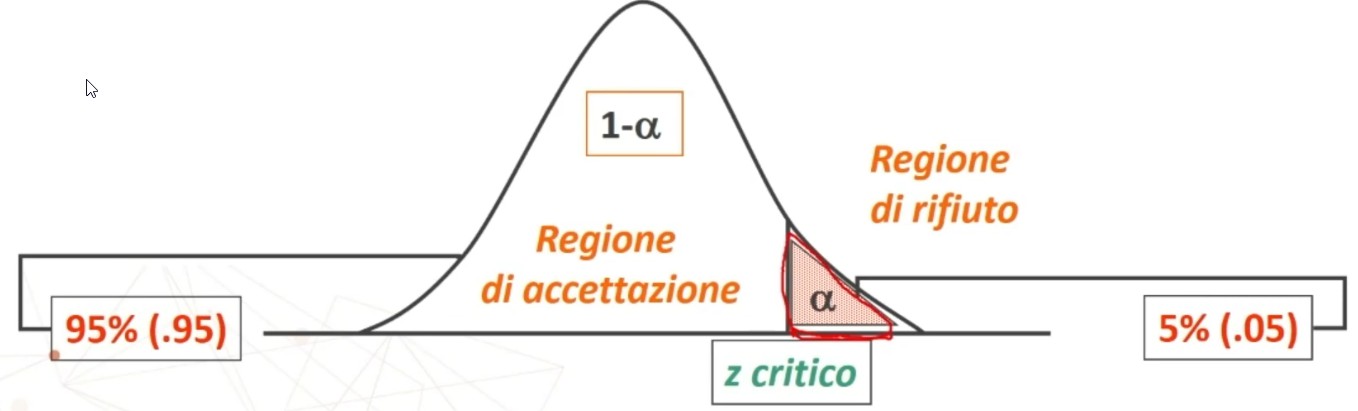
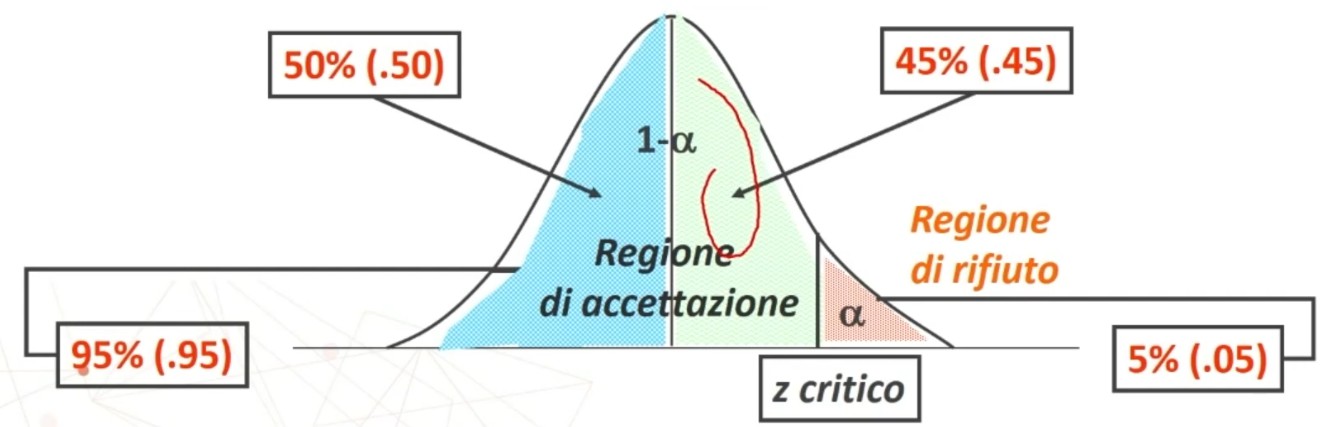
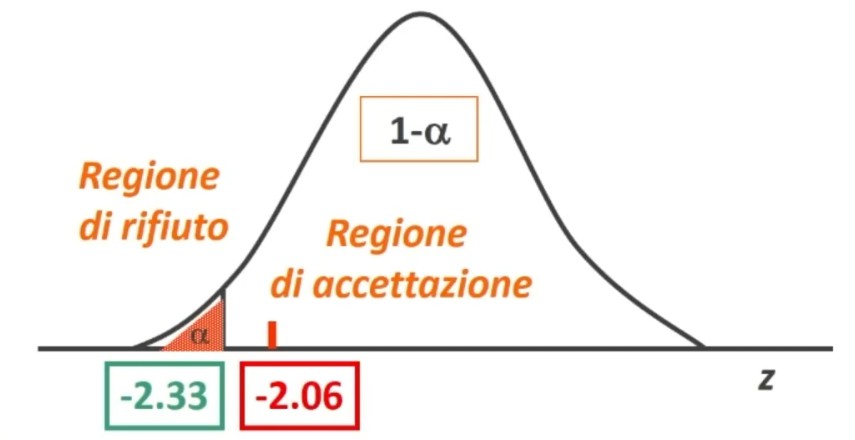
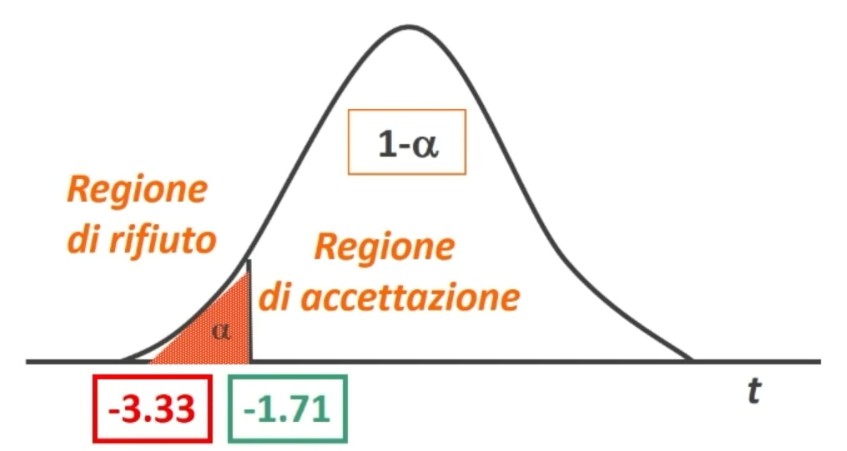
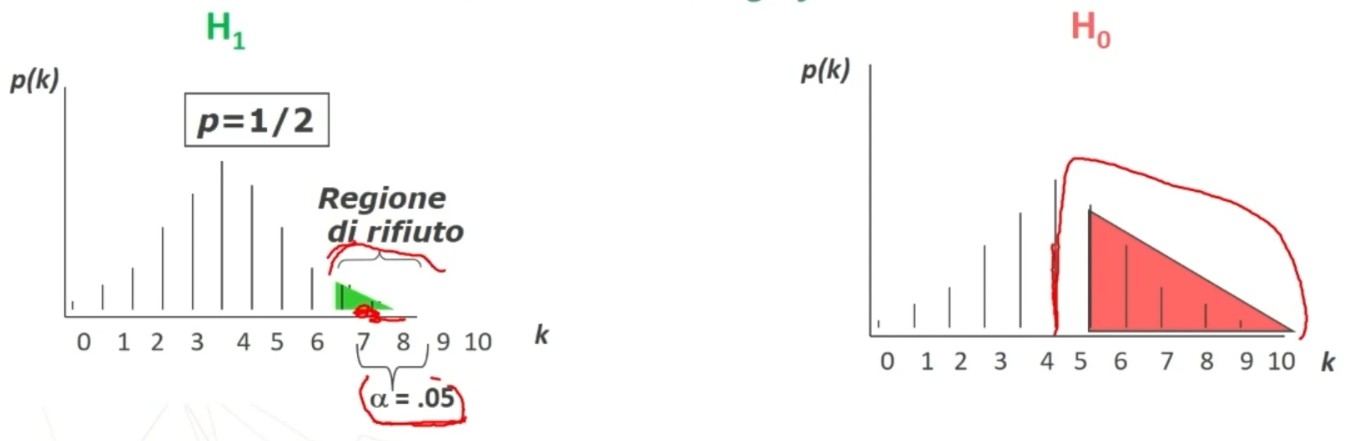
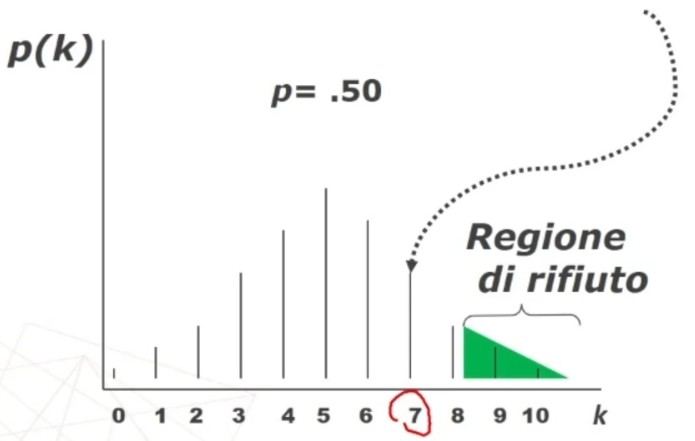
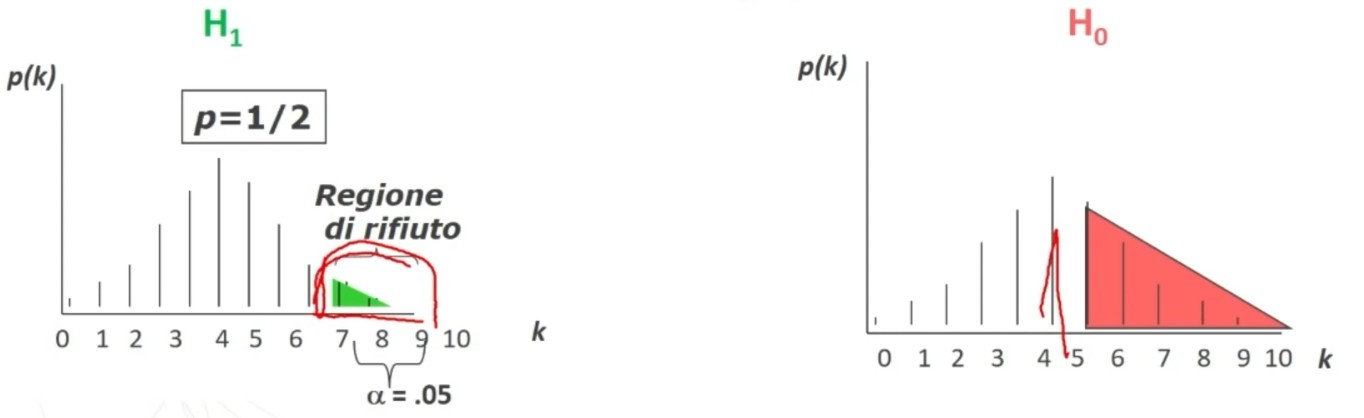
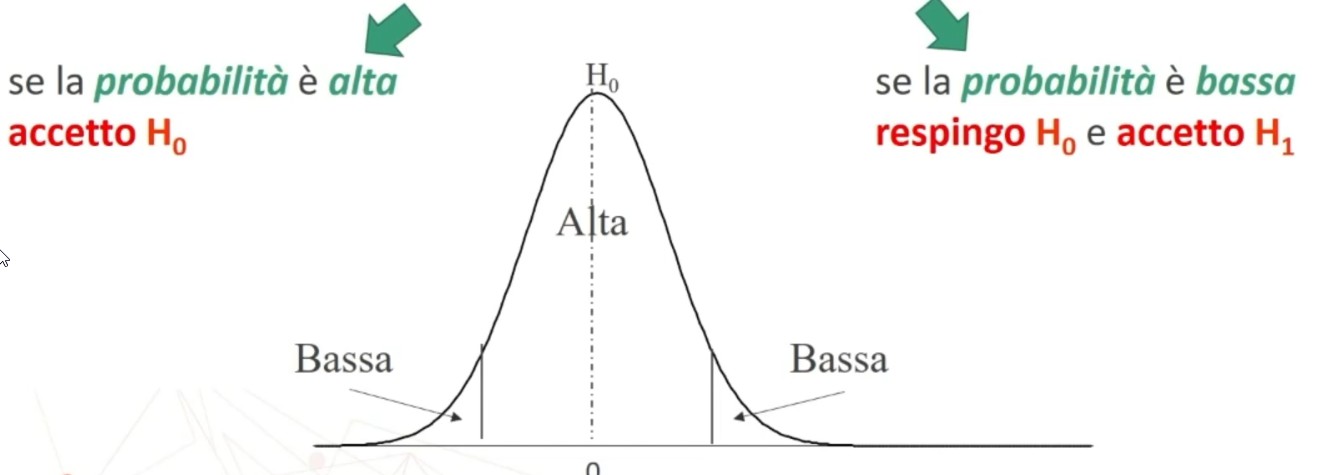
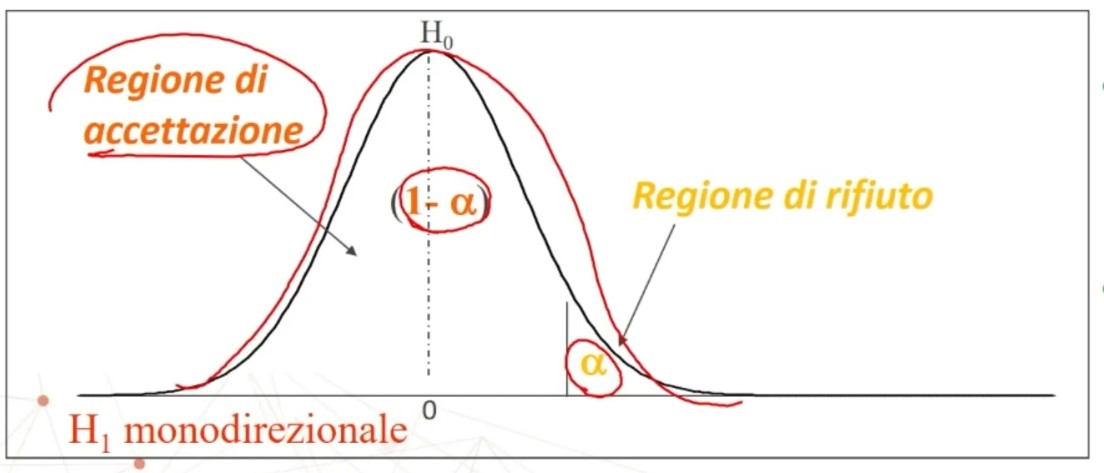
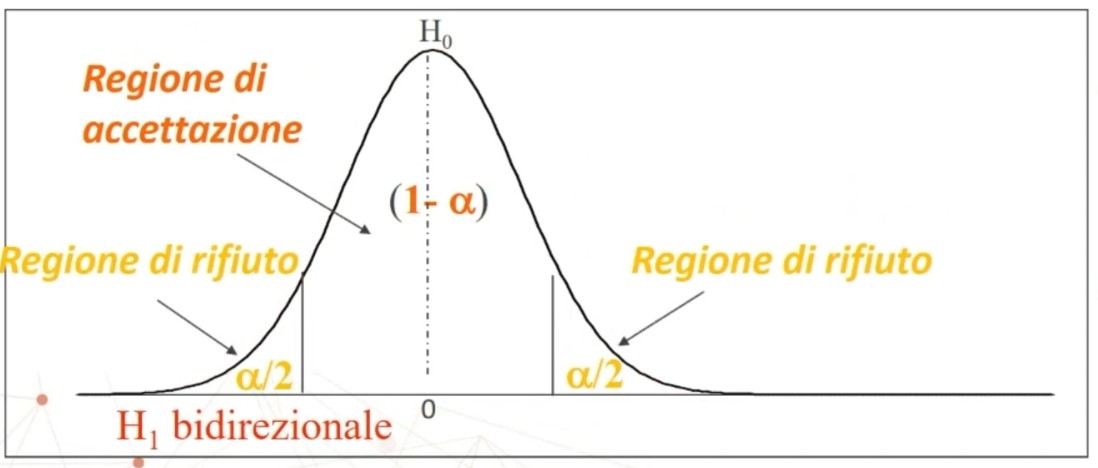
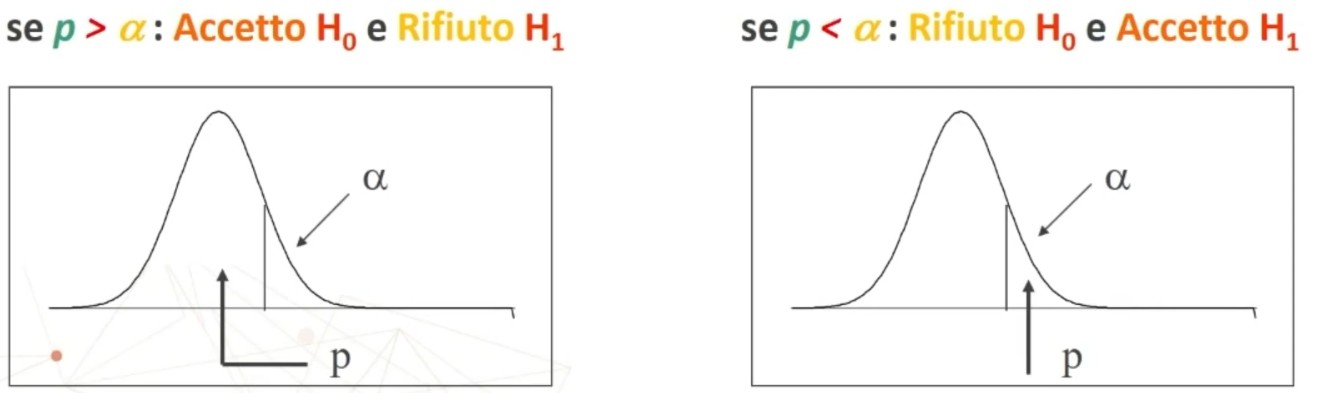
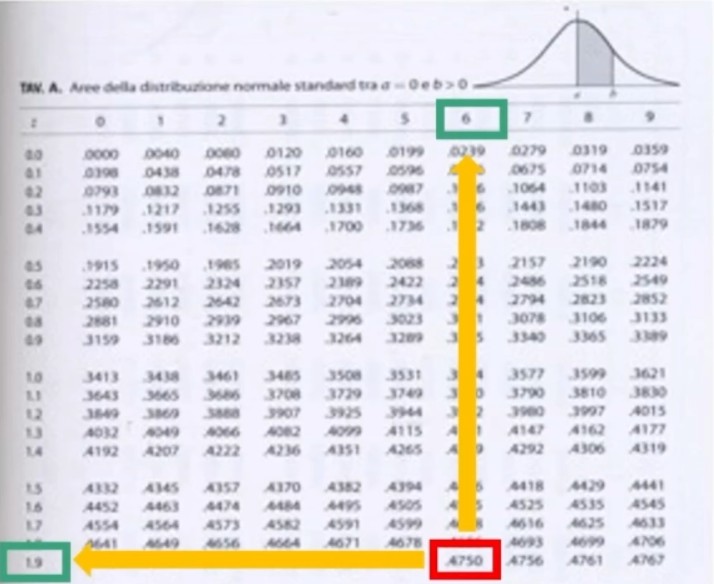
La tavola del χ² mi consente di definire un valore critico di χ² (oltre il quale si rifiuta l’ipotesi nulla e accetta quella sostantiva) a partire da:
- α = regione di rifiuto di H₀
- Gradi di libertà (gdl)
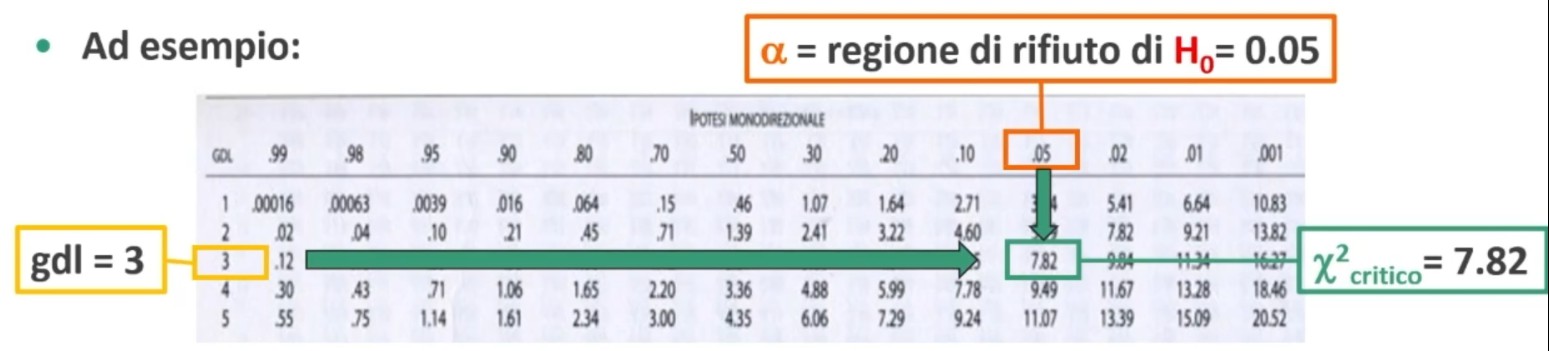
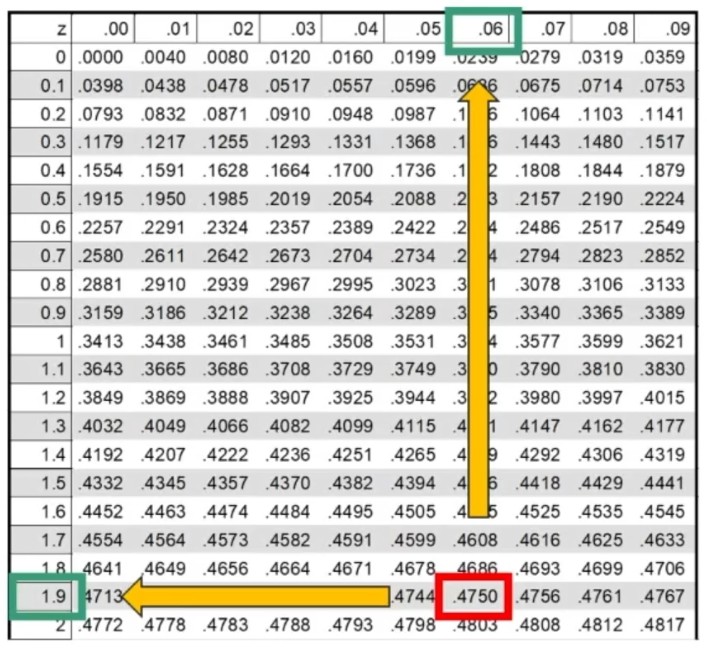
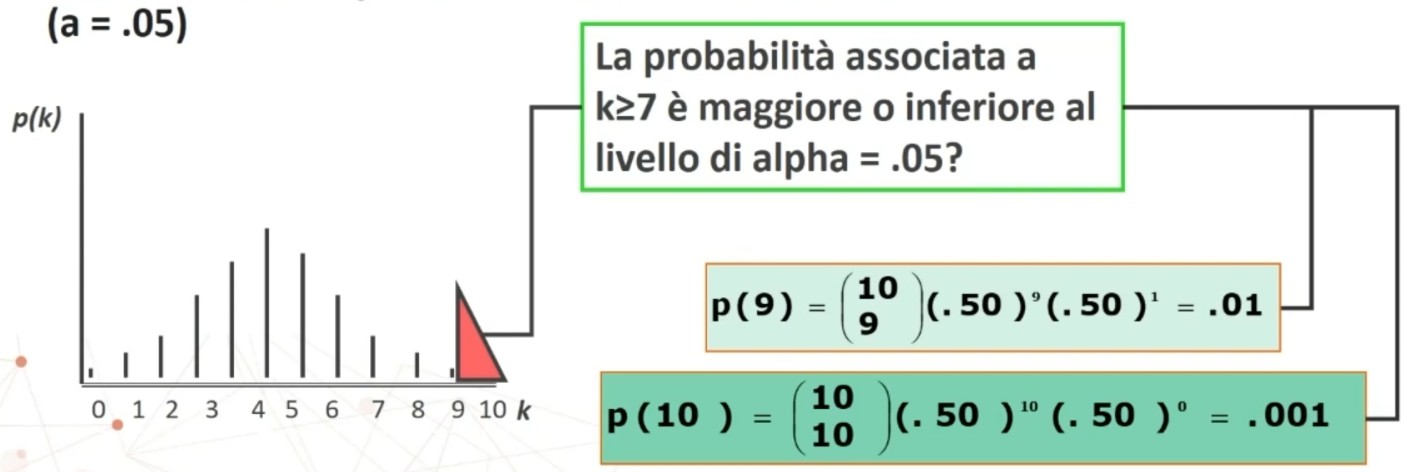
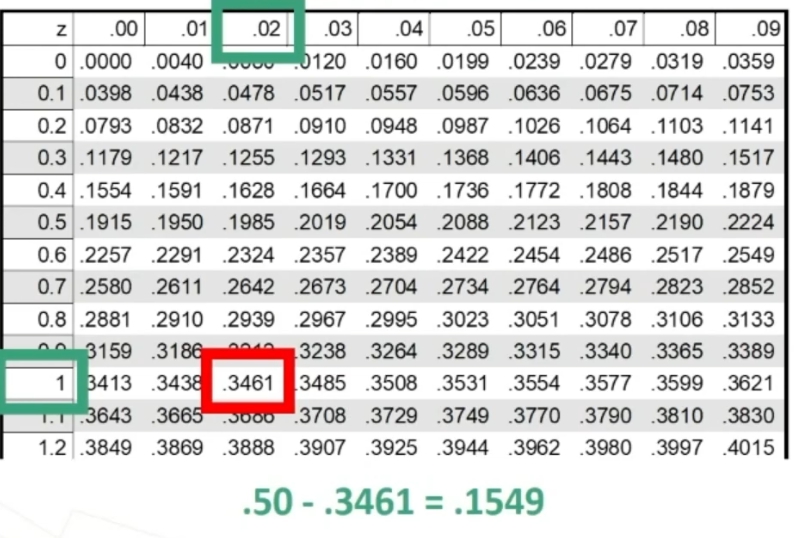
All’incrocio fra gdl=3 e α = 0.05 si trova χ² critico, cioè quello che lascia alla sua destra il 5% di probabilità di H₀ e alla sua sinistra il 95%:
- p(0 < χ² < 7.82) = .95
- p(7.82 < χ² < ∞) = .05
Vediamo ora la procedura da seguire nel caso della verifica delle ipotesi con il x2.
1. Scelta del test statistico (di significatività):
Si calcola χ² facendo riferimento alla distribuzione di frequenza
2. Definizione dell’ipotesi:
Confronta tra la dist. delle popolazioni (teorica) e quella del campione (osservata)
- H₀: χ² = 0 → o equidistribuzione nei diversi livelli della nostra variabile categoriale
- H₁: χ² ≠ 0 → o non equidistribuzione all’interno delle diverse categorie
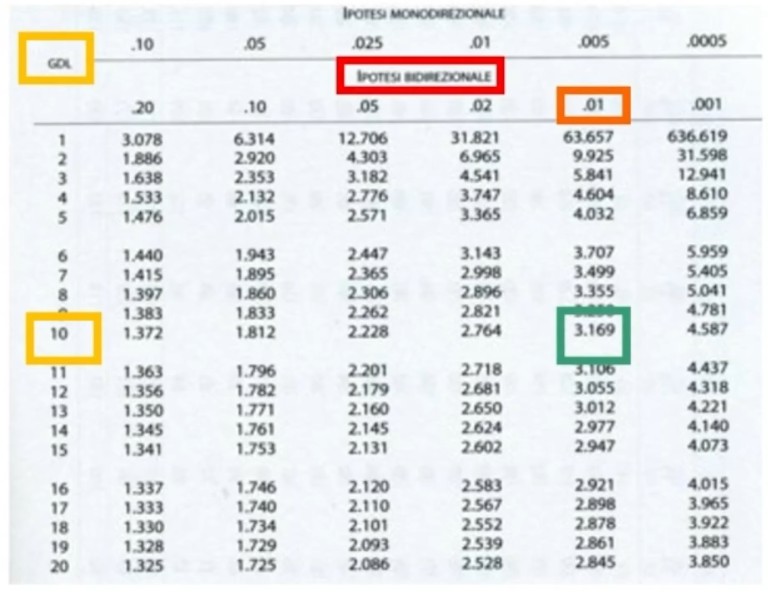
3. Fissare il livello di significatività α e calcolare i gradi di libertà:
Si definisce la regione di rifiuto di H₀ in base a:
- α fissato ad es. 0.05, 0.01, ecc.
- gdl = k-1 → Si calcolano in base a k e n (vincolo dato dal totale dei casi osservati)
Si trova così un χ² critico sulla Tavola
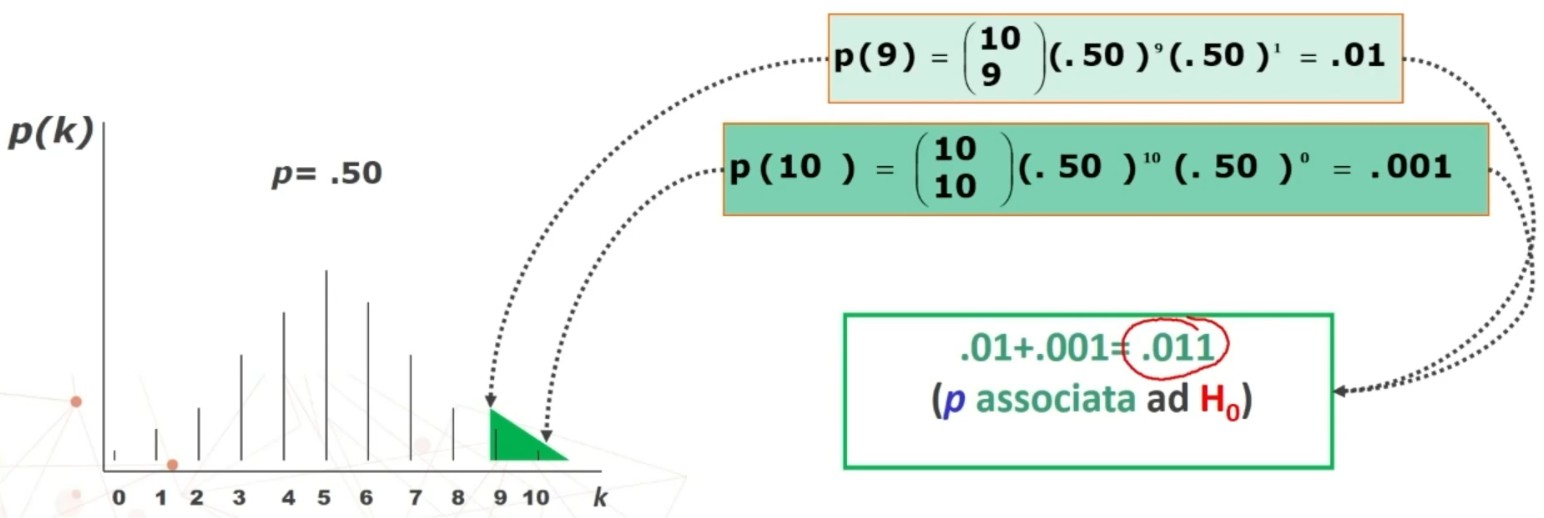
4. Associare una probabilità ad H₀:
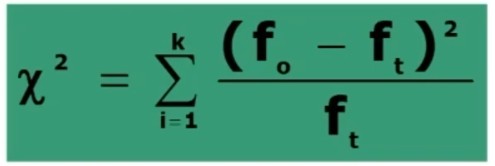
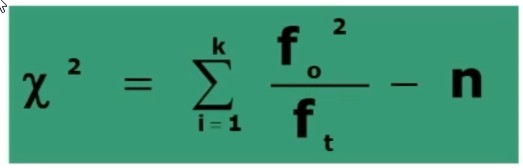
Si associa una probabilità ad H₀, calcolando χ² per confrontare la distribuzione osservata (fₒ = dati campionari) con la distribuzione teorica (fₜ) ottenuta in base all’equidistribuzione degli n casi nelle k categorie:
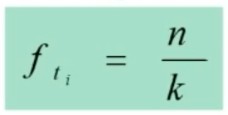
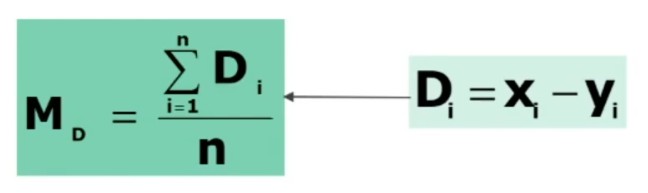
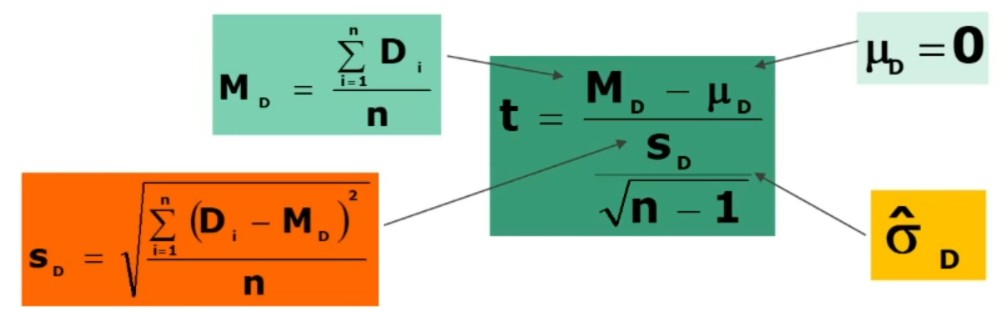
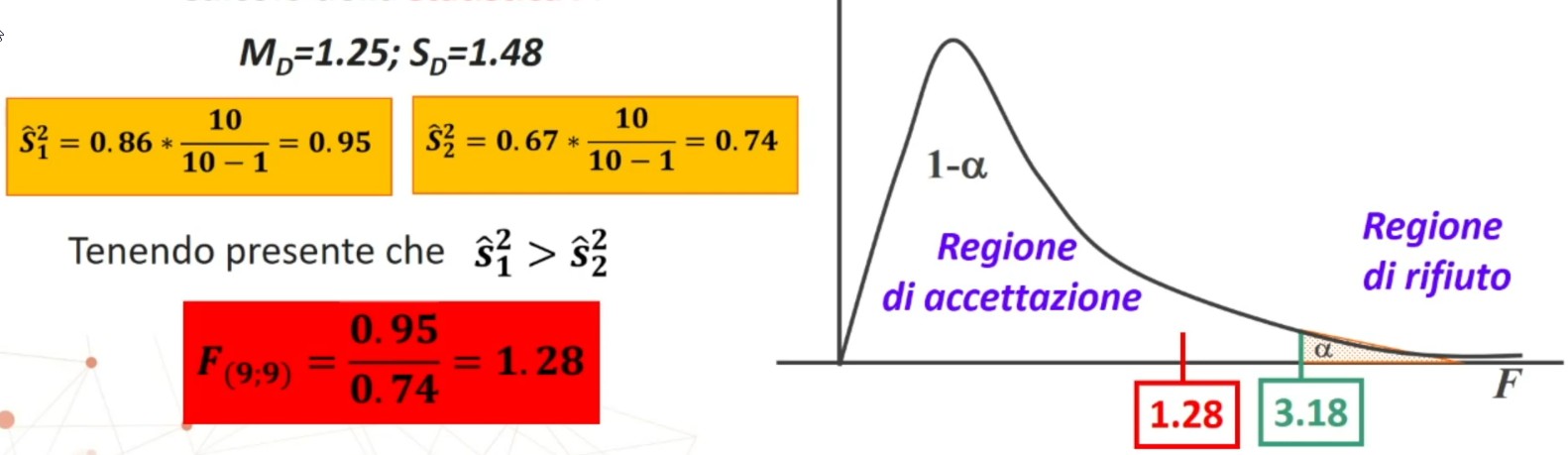
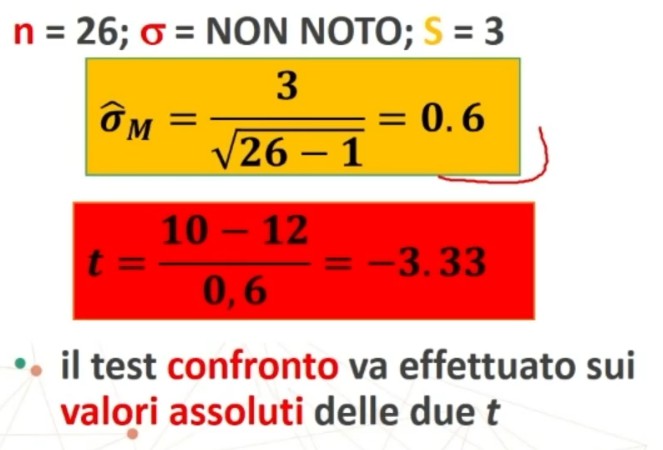
Per il calcolo del x2 posso utilizzare le seguenti 2 formule (la seconda derivata dalla prima)
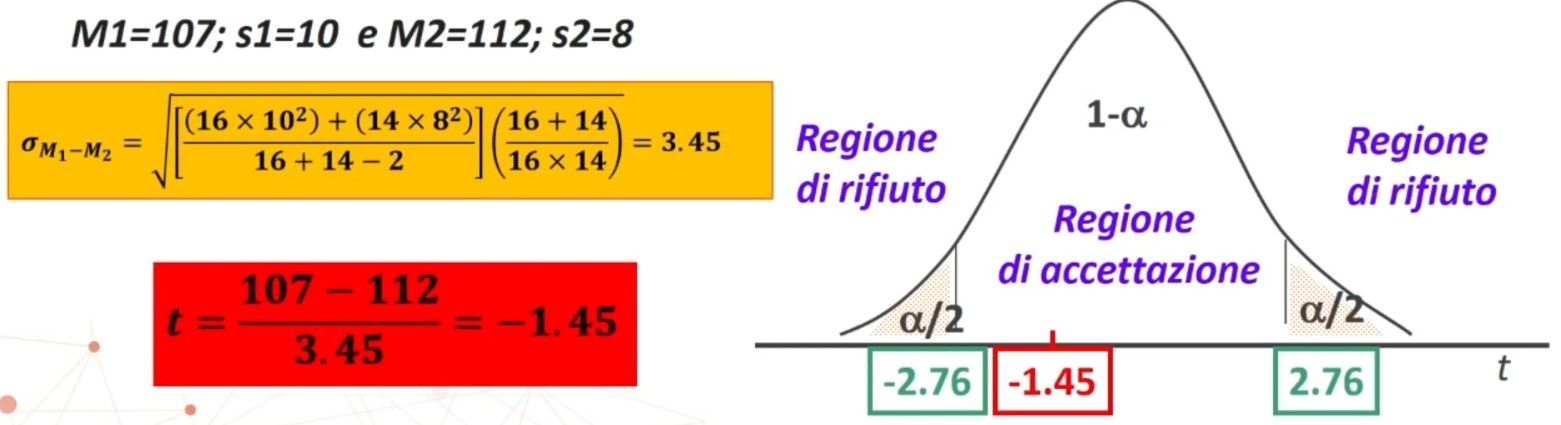
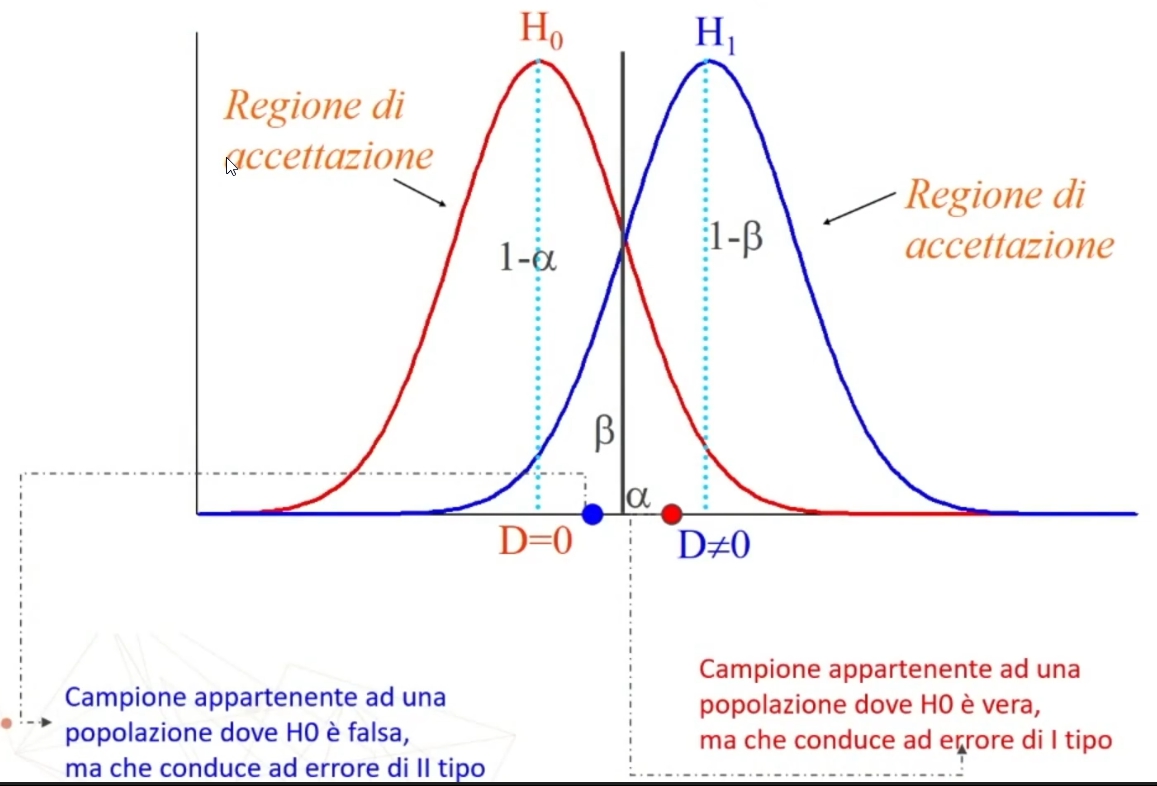
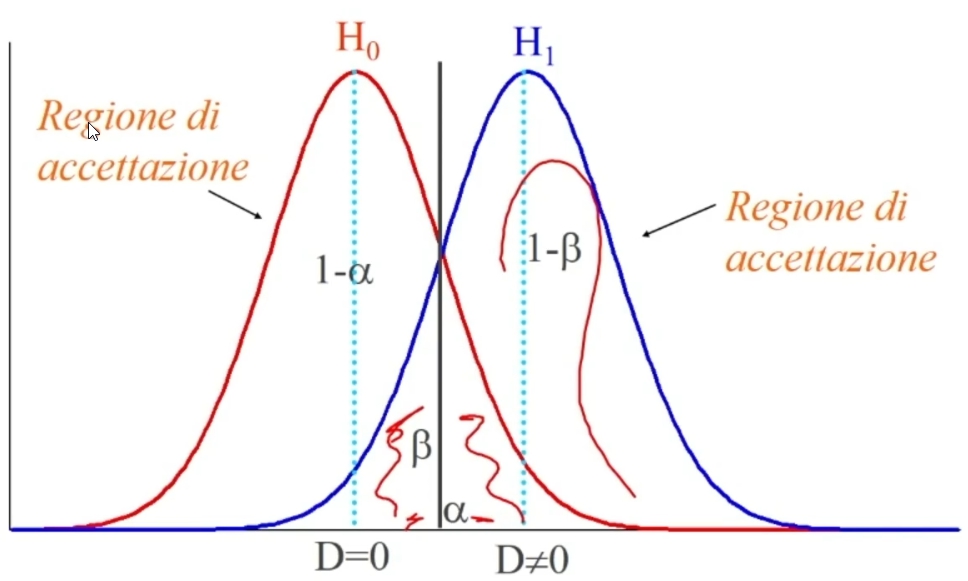
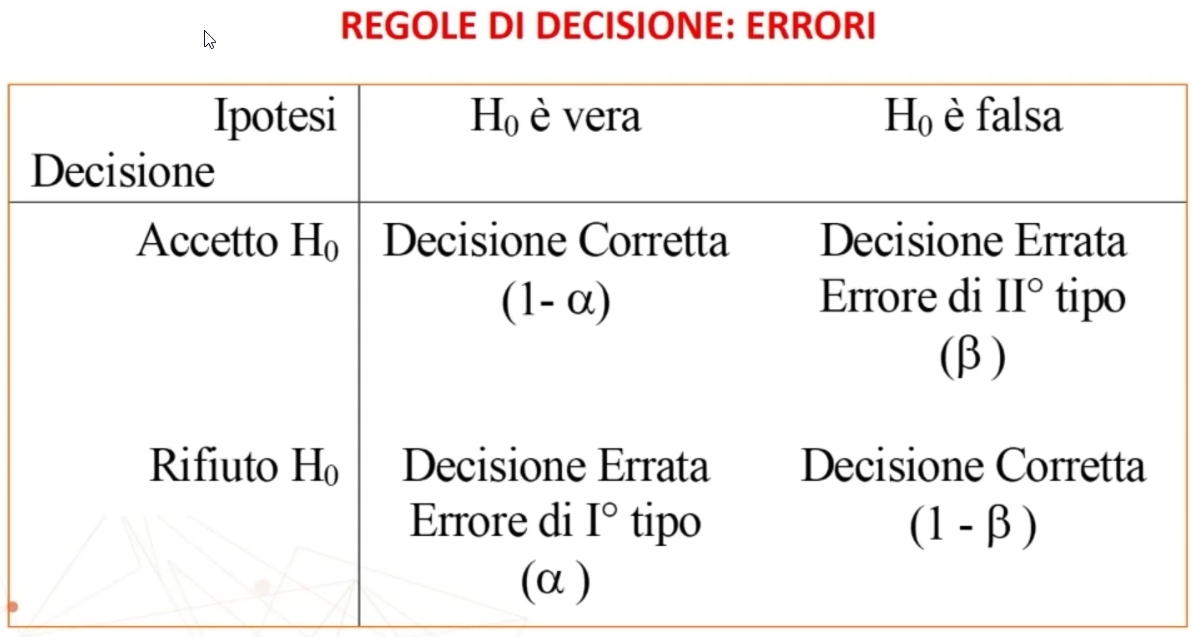
5. Decisioni su H₀: (H₀:⇒H₁)
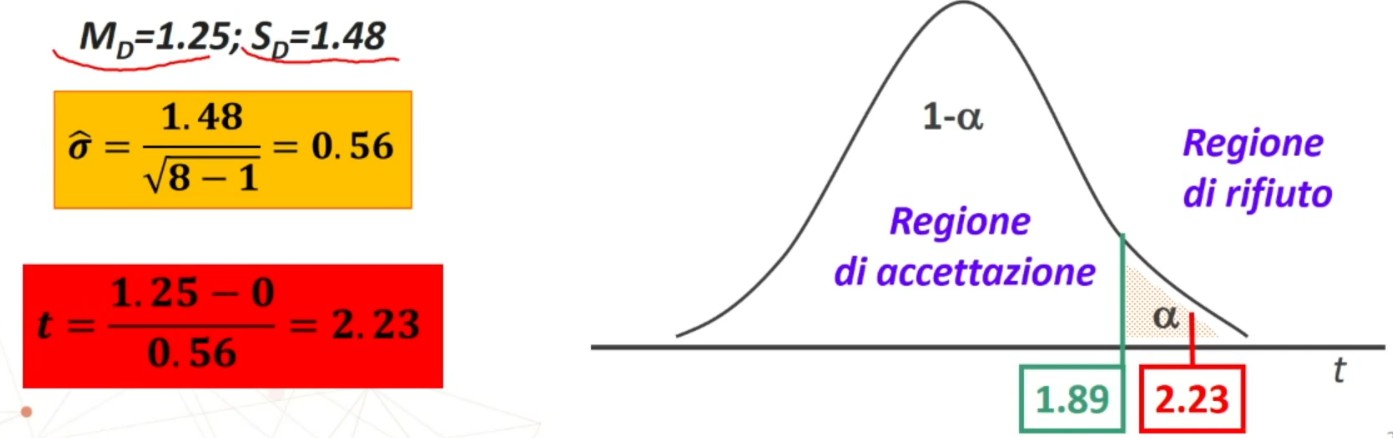
Il confronto avviene tra χ² e χ² critico. Se χ² < χ² critico ⇒ p > α allora
- Accetto H₀: Posta vera l’equidistribuzione, la probabilità di ottenere una distribuzione come quella osservata è sufficientemente elevata (maggiore di α)
- La differenza tra distribuzione teorica e osservata è imputabile al caso ⇒ L’ipotesi di equidistribuzione è probabilmente vera
Se χ² > χ² critico ⇒ p < α allora
- Rifiuto H₀: Posta vera l’equidistribuzione, la probabilità di ottenere una distribuzione come quella osservata è molto bassa (minore di α) ⇒ La differenza tra distribuzione teorica e osservata NON è imputabile al caso ⇒ L’ipotesi di equidistribuzione NON è probabilmente vera
Esempio
Lanciando un dado 120 volte si otteniene:
- 1 esce 19
- 2, 3 escono 21 volte
- 4 esce 23 volte
- 5 e 6 escono 18 volte
Il dado è truccato? Siamo di fronte a una sola variabile con k categorie (6 possibili)
1. Scelta del test statistico (di significatività):
Si calcola χ² facendo riferimento alla distribuzione di frequenze che caratterizzano i nostri dati
2. Definisco le ipotesi:
H₀: χ² = 0 ovvero p(1) = p(2) = p(3) = p(4) = p(5) = p(6);
H₁: χ² ≠ 0 ovvero almeno 2 probabilità siano diverse.
3. Delineo la regione di rifiuto di H₀:
α = .05; gdl = 6 – 1 = 5 con k = 6 (1, 2, 3, 4, 5, 6)
Da tabelle otteniamo χ² critico = 11.07
4. Associare una probabilità ad H₀:
Osservare le frequenze osservate fo e le frequenze teoriche ft osservando il principio dell’equidistribuzione
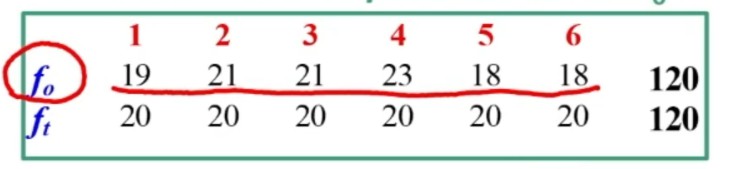
Calcoliamo ft = 120 / 6 = 20
Infine calcoliamo la statistica test del x2

5. Decisione su H₀ (⇒ H₁):
χ² < χ² critico (1.00 < 11.07) ⇒ p > .05
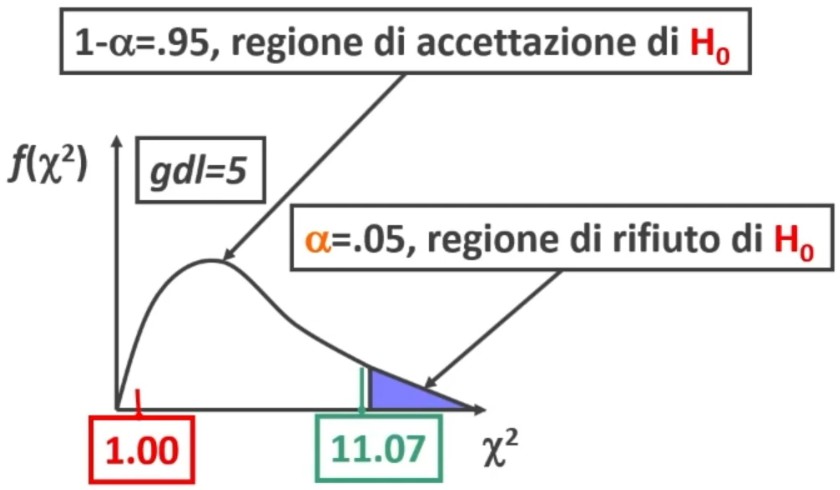
Quindi si accetta H0. La differenza tra distribuzione teorica e osservata è casuale. Il dado molto probabilmente non è truccato. Infatti, la probabilità di avere i risultati ottenuti supponendo vera l’equidistribuzione è molto alta.
Verifica delle ipotesi con X2: il caso di due campioni
In questo caso Il confronto avviene tra distribuzione teorica (popolazione) e una distribuzione osservata (nel campione) considerando due o più variabili. E quindi procederemo con un’analisi delle contigenze.
Andando ad eseguire un’analisi delle contigenze si analizza una cosidetta “tabella doppia entrata” o di contingenza.
Ad esempio consideriamo due variabili con due livelli
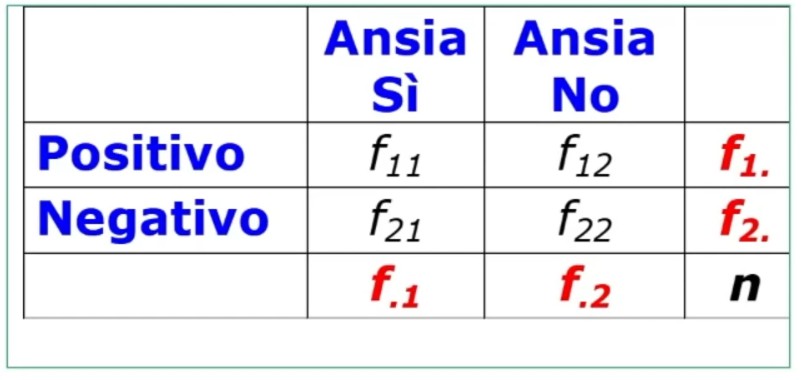
Il problema che ci poiniamo è se le frequenze sono distribuite casualmente, oppure i caratteri sono assocaiti in modo sistematico?
Quindi ciò che abbiamo sono
- 2 variabili (2 o più campioni indipendenti)
- Tabella di contingenza a doppia entrata (r = righe) x (c = colonne)
La distribuzione teorica che useremo per il confronto è la distribuzione teorica del chi quadro.
Si analizza una cosiddetta “tabella a doppia entrata” o di contingenza.
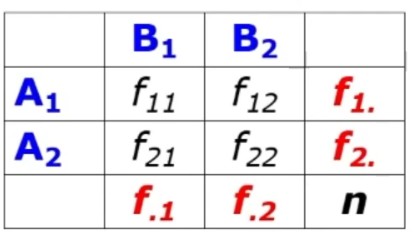
Il modello sottoposto a verifica H₀ è quello di indipendenza tra le due variabili in esame. Questo modello prevede che la variabile A varii indipendentemente dalla variabile B (e viceversa), ovvero tra le due variabili non c’è relazione (H₀).
Le fasi del processo di verifica sono le seguenti
1. Scelta del test statistico (di significatività):
Si calcola χ² facendo riferimento alle (due o più) distribuzioni di frequenza.
2. Definizione delle ipotesi:
Confronto la distribuzione teorica (indipendenza variabili) e quella osservata (dati campionari):
- H₀: χ² = 0 ovvero p(A1|B1) = p(A1)p(B2)
- H₁: χ² ≠ 0 ovvero p(A1|B1) ≠ p(A1)p(B2)
3. Fissare il livello di significatività α e calcolare i gradi di libertà:
Delineamo la regione di rifiuto H0 in base a
- α fissato a .05, .01, ecc.
- gdl = (r-1)(c-1) → Si calcolano in base a righe (r) e colonne (c) della tabella di contingenza.
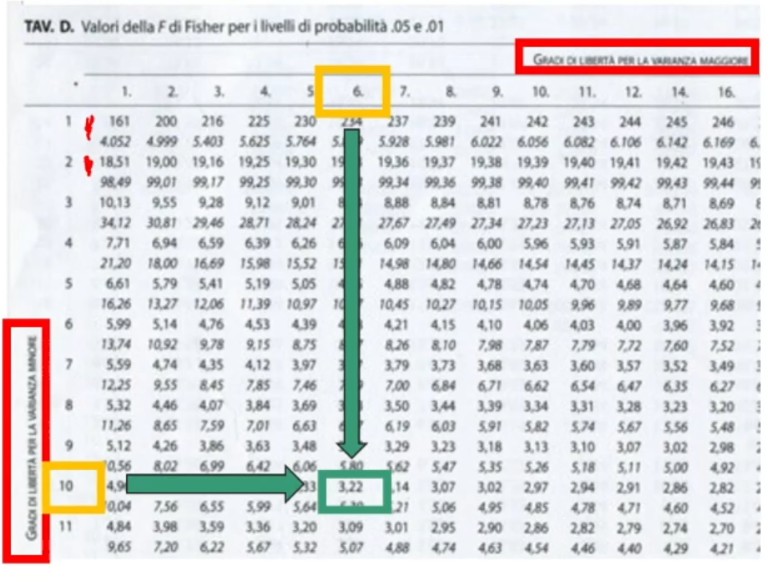
Si calcola χ² critico sulla Tavola.
I gradi di libertà data da una tabella di contingenza dipendono dai vincoli posti
- Se l’unico vincolo è costituito dal totale dei casi osservati n allora la formula è ν = (r × c) – 1
- Se i vincoli derivano anche dai marginali di riga (r-1) e colonna (c-1)allora la formula da usare è ν = (r – 1) × (c – 1)
Esempio del primo caso
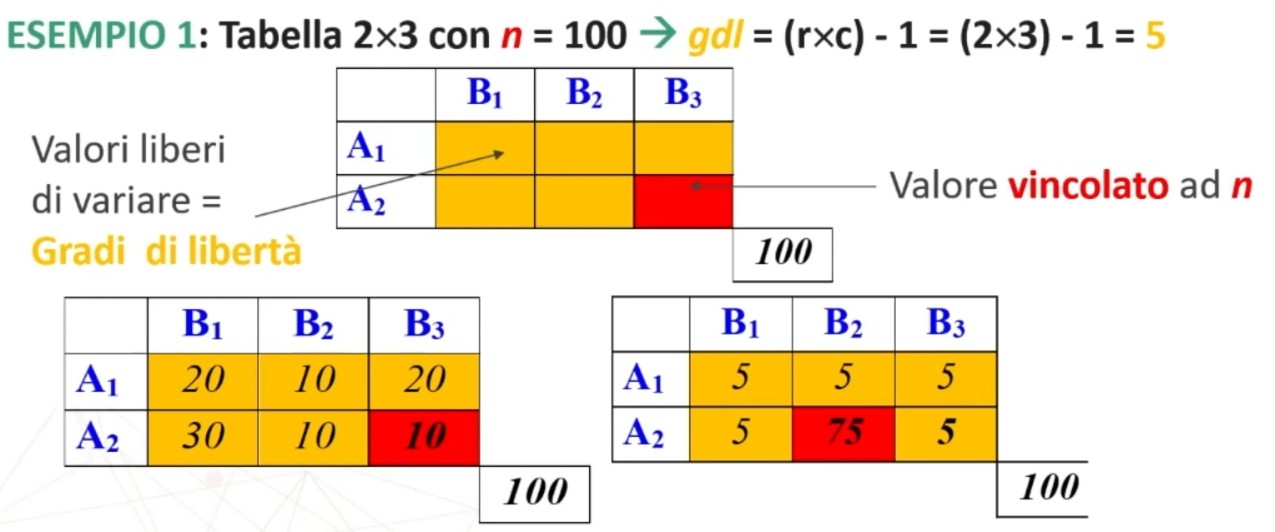
Esempio del secondo caso
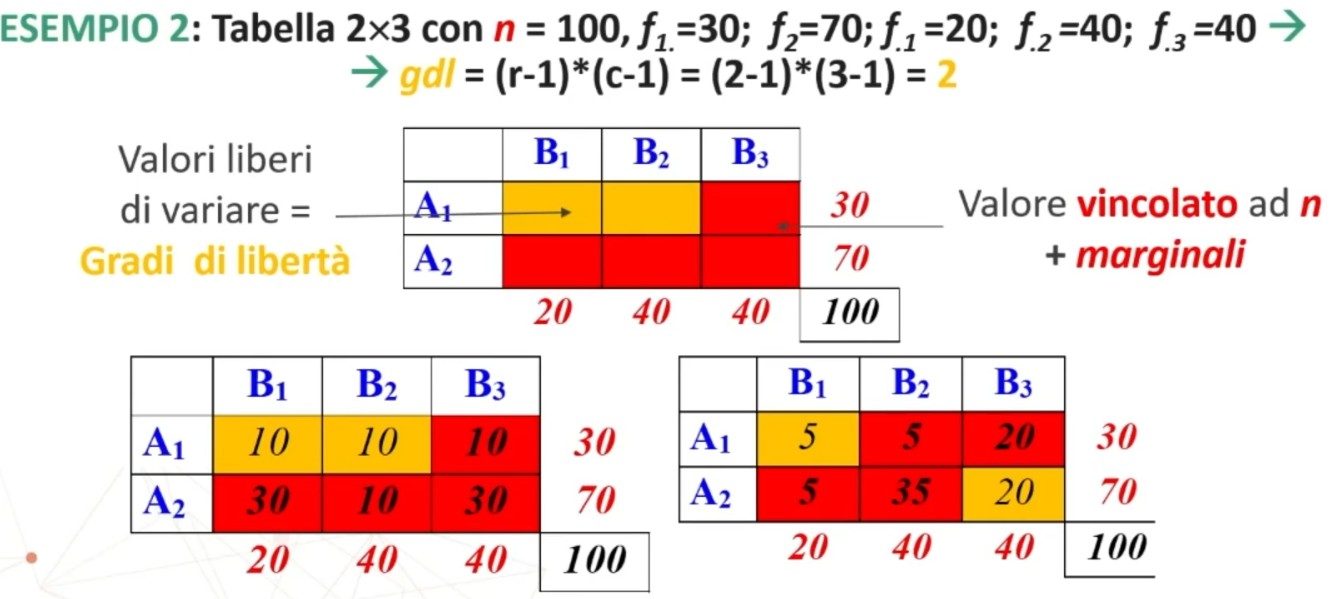
4. Associare una probabilità ad H₀:
Si associa una probabilità ad H₀ calcolando χ² per confrontare la distribuzione osservata (fₒ dati campionari) con la distribuzione teorica (fₜ) ottenuta in base all’indipendenza tra le variabili.
Ogni ft, la si ottiene dividendo il prodotto dei marginali corrispondenti alla cella in questione per il totale dei casi
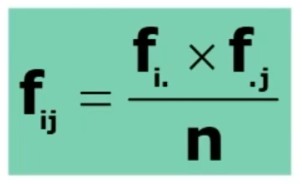
Il calcolo ci informa su quanto dovrebbero essere le frequenze teoriche per ogni cella se i due caratteri fossero indipendenti.
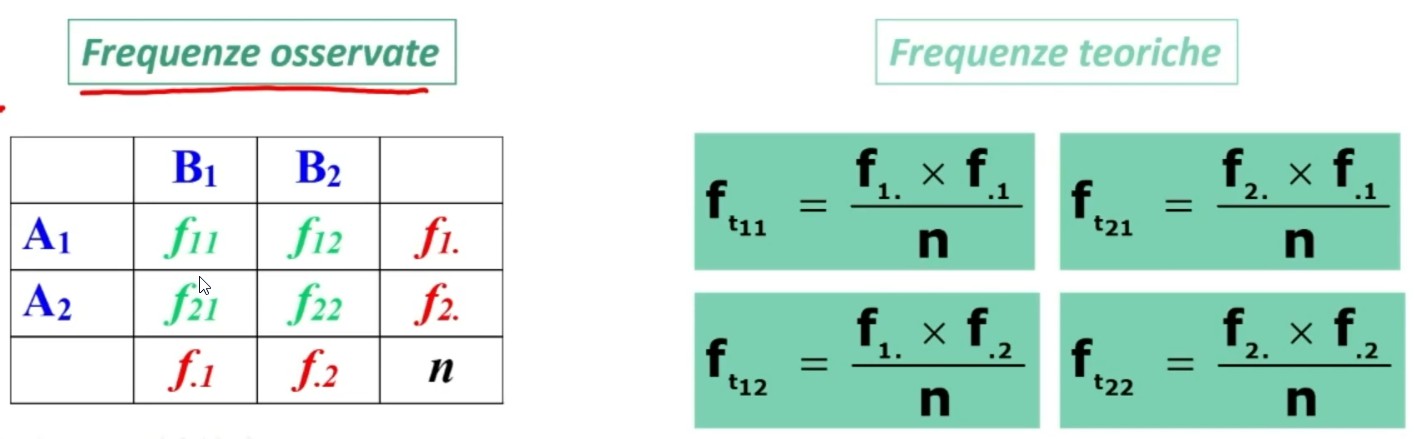
Di seguito le frequenze osservate e il successivo calcolo per le frequenze teoriche
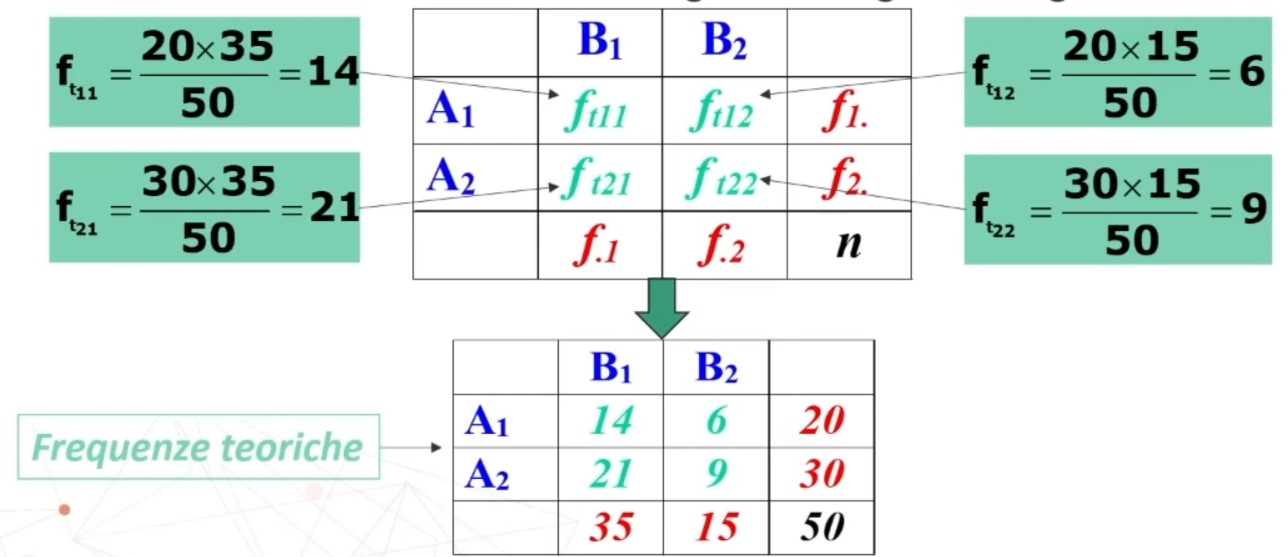
Ad esempio data la tabella 2×2 con n=50 e i seguenti marginali di riga e colonna, ho
Caso particolare: se i marginali di riga e colonna sono tutti uguali (tabella quadrata, per es. 2×2, 3×3, 4×4, ecc.) il calcolo delle frequenze teoriche è dato da:
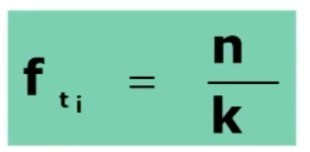
- n = totale casi osservati
- k = numero delle celle della tabella
Una volta ottenuta la distribuzione teorica di frequenze (ft), si procede al calcolo del χ² per confrontarla con la distribuzione osservata (fₒ = dati campionari).
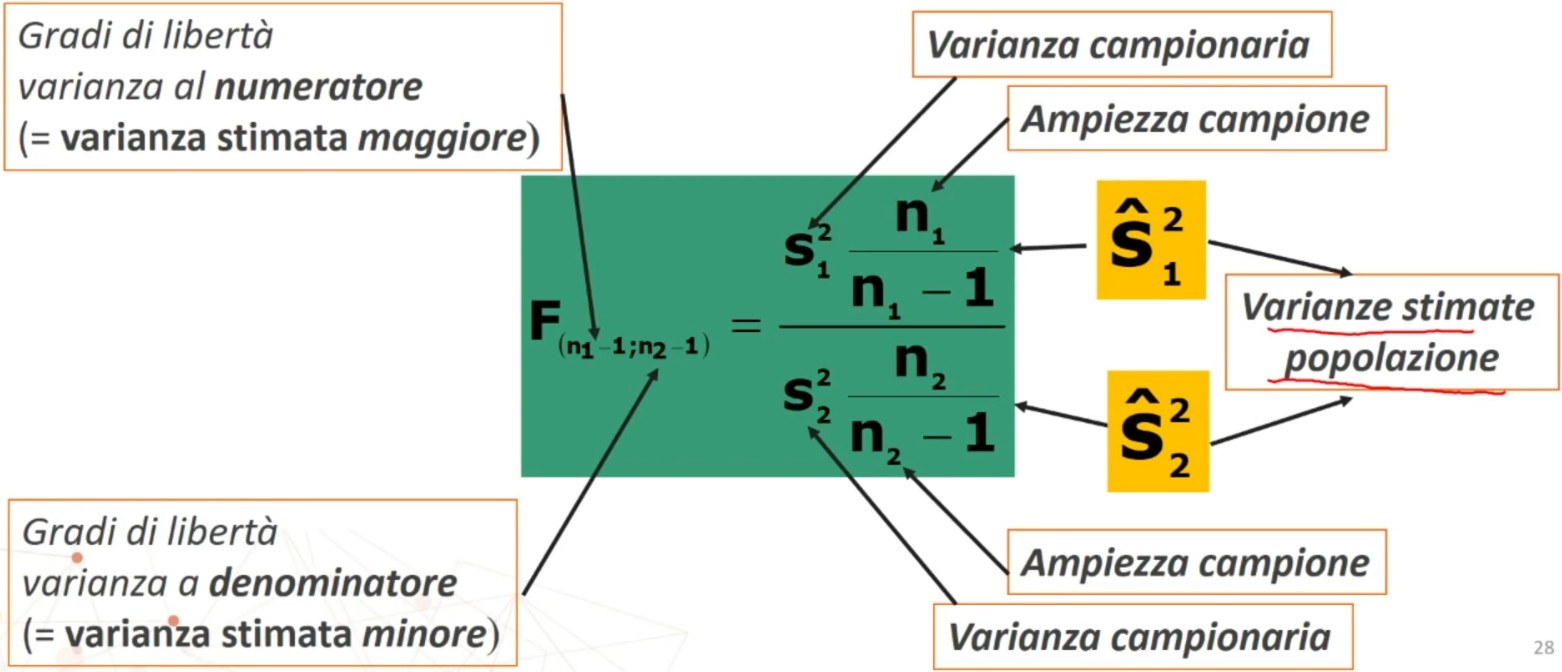
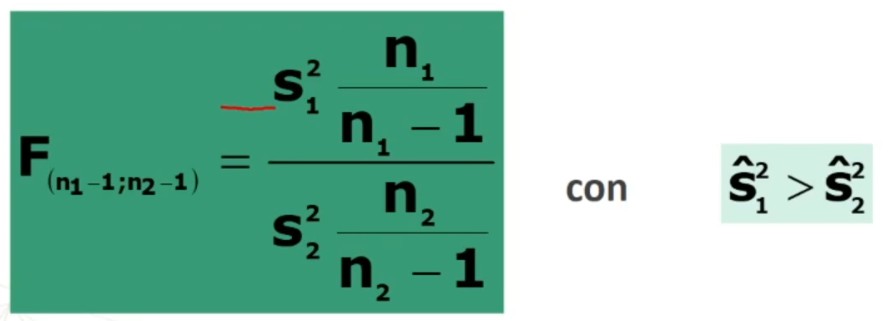
Per il calcolo del χ² posso utilizzare indifferentemente una delle due formule:
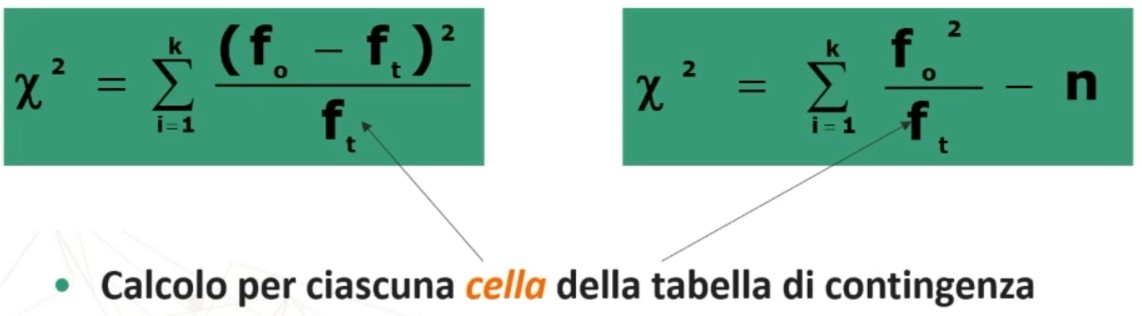
5. Decisione su H₀ (⇒ H₁):
Il confronto avviene tra χ² e χ² critico
Se χ² < χ² critico (p > α):
- Accetto H₀: Posta vera l’indipendenza, la probabilità di ottenere una distribuzione come quella osservata è maggiore di α ⇒ La differenza tra distribuzione teorica e osservata è imputabile al caso ⇒ L’ipotesi di indipendenza è probabilmente vera, quindi tra le due variabili non c’è relazione
Se χ² > χ² critico (p < α):
- Rifiuto H₀: Posta vera l’indipendenza, la probabilità di ottenere una distribuzione come quella osservata è minore di α ⇒ La differenza tra distribuzione teorica e osservata NON è imputabile al caso ⇒ L’ipotesi di indipendenza NON è vera ⇒ Tra le due variabili c’è una qualche relazione, ovvero c’è dipendenza.
Esempio
Sono stati raccolti dati relativi alle iscrizioni ad una laurea triennale di 160 studenti. Osserviamo la seguente distribuzione di frequenze:
Prima variabile: scuola di provenienza. Seconda variabile che è la scelta di iscriversi o meno a una larea triennale
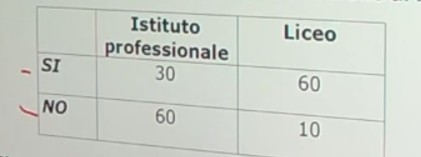
Si vuole verificare se la scelta di iscriversi all’università è legata alla scuola di provenienza.
La variabile indipendente è la scuola di provenienza, la dipendente la scelta di iscriversi all’università.
1. Scelta del test statistico (di significatività):
Si calcola χ² facendo riferimento alla distribuzione di frequenze (tabella di contingenza).
2. Definisco le ipotesi:
Posto che IP (istituto professionale), L (liceo) e le risposte Si e No, per le ipotesi ho
- H₀: χ² = 0 ovvero p(Sì | IP) = p(Sì | L);
- H₁: χ² ≠ 0 ovvero p(Sì | IP) ≠ p(Sì | L).
3. Delineo la regione di rifiuto di H₀:
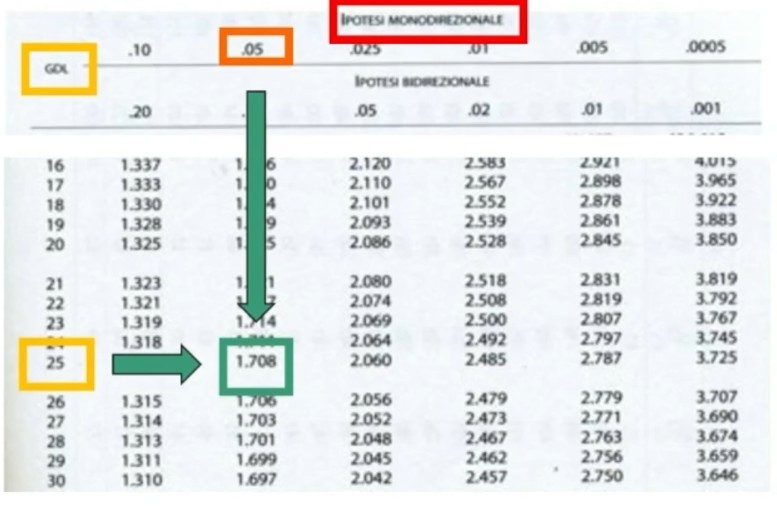
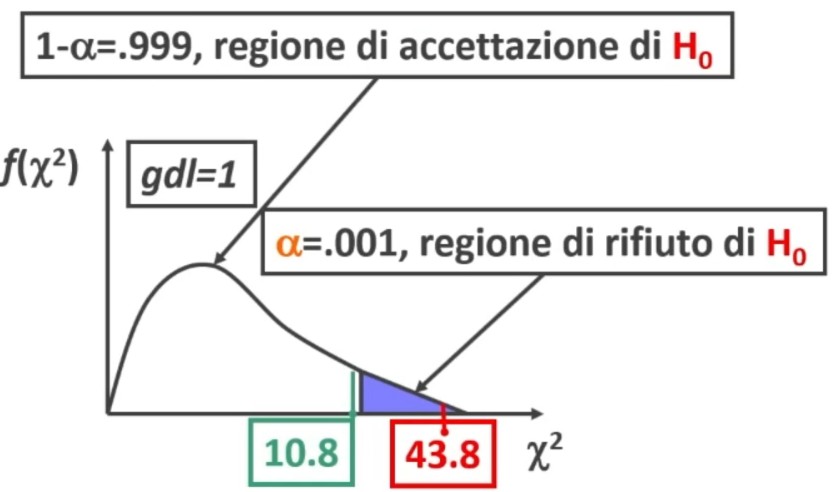
Pongo α = .001; gdl = (2-1)(2-1) = 1 con r = 2 e c = 2. Da cui il χ² critico = 10.83
4. Associare una probabilità ad H₀:
Calcolo le frequenze teoriche e la statistica test χ²:
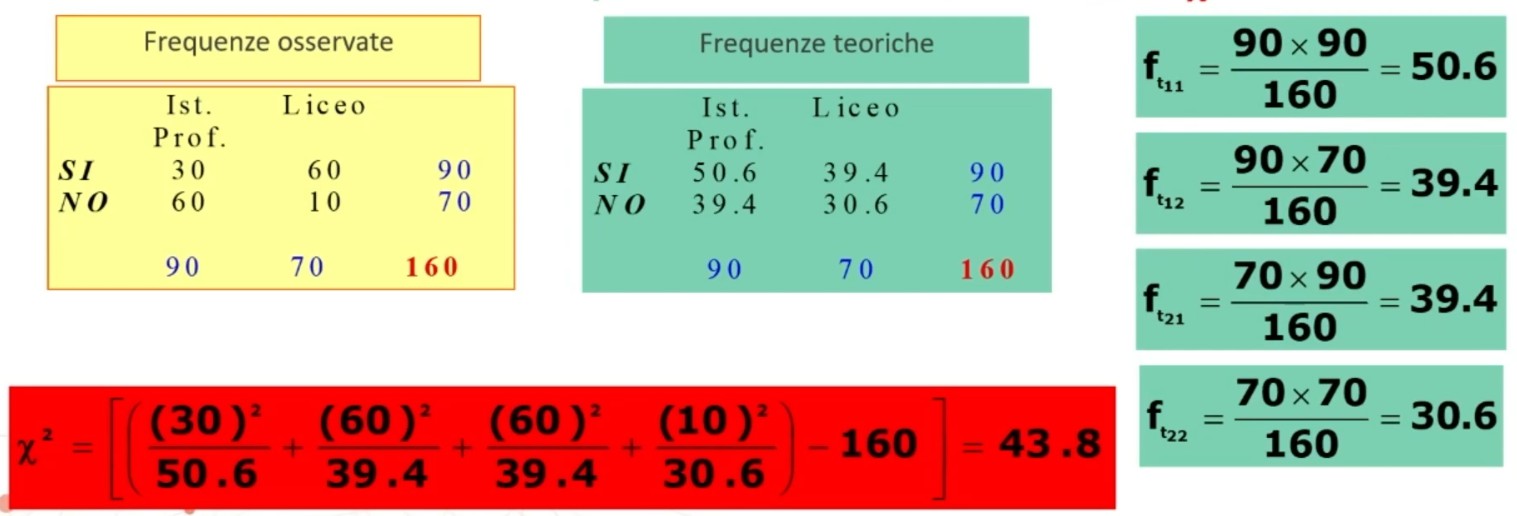
5. Decisione su H₀ (⇒ H₁):
χ² > χ² critico (43.8 > 10.83) ⇒ p < .05
Quindi rifiuto H₀. La differenza tra distribuzione teorica e osservata NON è casuale. Le due variabili molto probabilmente sono dipendenti.
Infatti la probabilità di avere i risultati ottenuti supponendo vera l’indipendenza è molto bassa.
Tra la provenienza scolastica e la scelta di iscriversi all’università c’è relazione.
Infine, poiché il χ² è usato con variabili discrete (non metriche) ma la distribuzione χ² è continua, si utilizza la correzione di continuità di Yates (sottrazione .5):
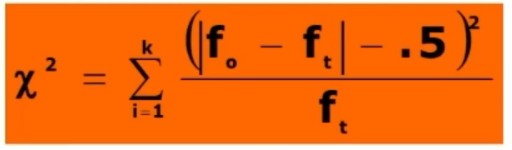
Alla differenza, in valore assoluto, tra le frequenze teoriche o attese e quelle osservate viene tolta la quantità di 0.5.
Questa correzione è necessaria quando:
- gdl > 1 e 20% delle frequenze teoriche fₜ ≤ 5
- gdl = 1 e 50% di fₜ ≤ 5