Table of Contents
- Popolazioni e campioni
- Parametri e indicatori
- Distribuzione campionario della media (dcm)
- Uso della distribuzione campionaria della media
- Distribuzione campionaria della differenza tra le medie
Popolazioni e campioni
La Popolazione (o Universo) è l’insieme di tutti gli elementi a cui si rivolge il ricercatore nel fare la sua indagine. Quindi tutte le persone (o cose) che possono essere oggetto della ricerca.
Esempi:
- tutti i cittadini italiani aventi diritto al voto (indagini elettorali)
- tutti i giovani dai 13 ai 18 anni (indagine sulla contraccezione)
Definiamo inoltre:
- Popolazioni finite: insieme finito
- Popolazioni infinite: insieme infinito
In entrambi i casi non è quasi mai possibile studiare l’intera popolazione, per motivi di tempi e di costi. Si deve pensare ad un sottoinsieme di n elementi della popolazione.
Tale sottoinsieme di n<N è detto campione (n elementi che compongono il campione, N elementi che compongono la popolazione).
Per fare in modo che il risultato ottenuto sul campione sia valido per la popolazione, occorre che il campione sia rappresentativo.
Un campione è rappresentativo quando ha tutte le più importanti caratteristiche della popolazione da cui proviene.
È difficile avere un campione perfettamente rappresentativo ma, se viene estratto casualmente dalla popolazione, le eventuali differenze tra popolazione e campione sono imputabili al caso e non a cause sistematiche.
Facciamo un esempio, sondaggi elettorali. In questo caso abbiamo:
- Popolazione di riferimento = tutti i cittadini italiani aventi diritto al voto.
Se si intervistasserо sulle intenzioni di voto gli iscritti ad un partito, si otterrebbe un risultato distorto. Mentre invece se si intervistasserо solo i residenti in un’area geografica oppure solo i cittadini di una certa fascia d’età, si otterrebbe un risultato distorto a causa di un errore sistematico.
Se, invece, si estraggono a caso dalle liste elettorali n<N elettori, si ottiene un campione abbastanza rappresentativo della popolazione. Gli errori sono casuali e, aumentando la numerosità del campione, tendono a ridursi (i margini d’errore sono sempre più ridotti man mano che le proiezioni si basano su un maggior numero di schede scrutinate).
Da questo esempio possiamo concludere dicendo che il modo di campionare una popolazione è dunque importante. Il campionamento casuale è quello che, a parità di condizioni, dà maggiori garanzie che il campione sia rappresentativo.
Esistono diverse tipologie di campionamento:
- Campione casuale semplice: tutti gli elementi della popolazione hanno la stessa probabilità di essere estratti.
- Con reinserimento: ad ogni successiva estrazione del campione, non cambia la popolazione di riferimento.
- Senza reinserimento: la popolazione cambia ad ogni estrazione. È il metodo maggiormente utilizzato in psicologia (non serve far compilare lo stesso test o lo stesso questionario alle stesse persone).
Parametri e indicatori
Nella ricerca ciò che interessa è lo studio di una caratteristica di una popolazione (che può essere un’atteggiamento verso un problema sociale, età media degli studenti universitari, …).
Tale caratteristica, riferita:
- alla popolazione si definisce Parametro
- al campione si definisce Indicatore
L’indicatore sintetizza la caratteristica oggetto di esame nel campione (estratto dalla popolazione).
Ciò a cui siamo interessati è quindi: che rapporto c’è tra l’Indicatore e il Parametro? La statistica inferenziale si occupa proprio della stima dei parametri attraverso gli indicatori del campione (unici valori empirici disponibili).
A questo scopo si utilizzano le distribuzioni campionarie degli indicatori (proporzioni, medie, varianze, …) che hanno forma e caratteristiche conosciute.
Le distribuzioni campionarie (media, proporzioni, varianza, e qualsiasi altro indicatore) assumono forme simili alle più importanti distribuzioni teoriche di probabilità (normale, t di Student, c2, F di Fisher, …).
Di queste ultime (distribuzioni teoriche) si possono usare le proprietà e i valori tabulati. Ciascuna di esse ha, infatti, media, varianza, deviazione standard noti.
Distribuzione campionario della media (dcm)
La più importante distribuzione campionaria è la distribuzione campionaria della media.
Le sue proprietà sono:
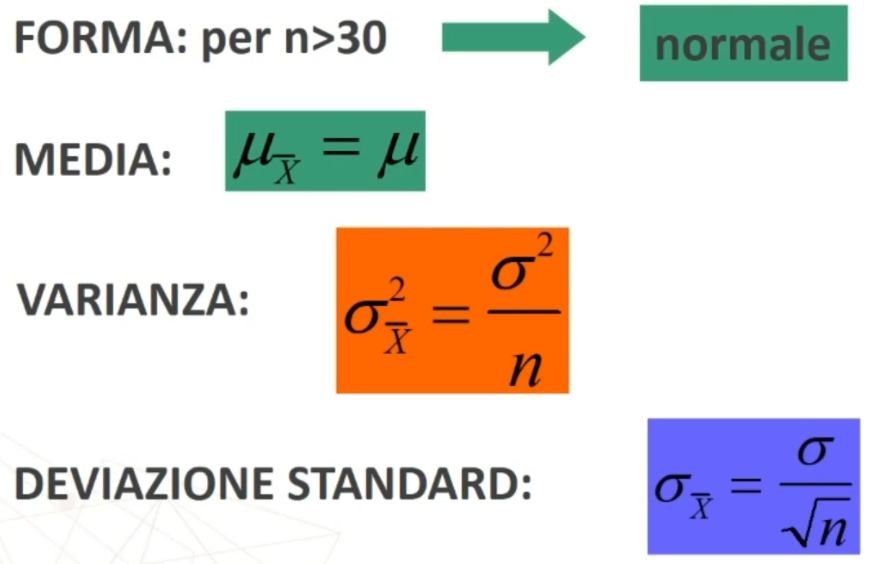
- La media delle medie dei campioni coincide con la media della popolazione dalla quale i campioni sono stati estratti:
μx̄ = μ
Nonostante ciò, non è detto che la forma delle due distribuzioni coincida, ma, mano a mano che l’ampiezza dei campioni aumenta, la media di ciascuno di essi diventa una stima sempre più precisa della media della popolazione. - Le due medie coincidono quando n=N, cioè quando i campioni estratti coincidono con l’intera popolazione.
Possiamo dire allora che esiste una relazione tra:
- variabilità della distribuzione campionaria delle medie
- variabilità della popolazione
- ampiezza del campione
Tale relazione è espressa dalla formula
Dove
- è la varianza distribuzione campionaria
- è la varianza della popolazione
- n è l’ampiezza del campione
All’aumentare di n la variabilità della distribuzione campionaria delle medie diminuisce fino a tendere a zero.
La forma della distribuzione campionaria delle medie non è sempre nota. Esiste però il Teorema del limite centrale che dimostra che per campioni di numerosità n>30 la distribuzione campionaria delle medie si approssima alla distribuzione normale, qualunque sia la forma della distribuzione della popolazione.
Nella ricerca empirica di solito non si conosce la varianza della popolazione, cioè σ2 non è nota. Tuttavia è possibile calcolare la varianza della popolazione stimandola a partire dalla varianza di uno dei campioni estratti.
Ricordiamo che:
- σ2x̄ è la varianza della distribuzione campionaria della media;
- σ2 è la varianza della popolazione;
- s2 è la varianza del campione.
Il nostro scopo è calcolare la varianza della popolazione. Non si può calcolare σ2x̄ = σ2/n perché, essendo σ2 riferita ad un solo campione, è una stima distorta di σ2.
Passaggi teorici
Si dimostra che una stima non distorta di σ2 si ha dividendo la varianza del campione per (n-1) invece che per n, cioè:

In pratica, conoscendo s2, si possono stimare la varianza della distribuzione campionaria della media e lo scarto quadratico medio della distribuzione campionaria della media (σx̄).
Chiamiamo ŝ2 la varianza stimata della popolazione e s2 la varianza di un campione. Si può dimostrare che:
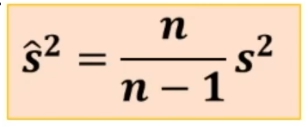
Allora la varianza della distribuzione campionaria della media sarà:
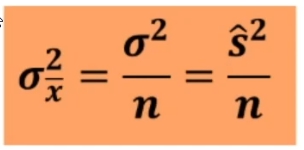
Da ciò si rica va che

Quindi
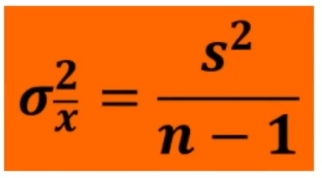
È la varianza della distribuzione campionaria della media stimata a partire dalla varianza del campione.
Esempio
Facciamo ora un esempio di distribuzione campionaria della media. Supponiamo di avere una popolazione con media μ e varianza s2 e supponiamo di estrarre in modo casuale campioni tutti di numerosità n. Si dimostra che calcolando le medie X̄ dei campioni estratti, la distribuzione di tali medie è una normale con media μ e varianza σ2/n.
Esempio: Consideriamo una popolazione fittizia di N=3 che assume i seguenti valori:
- X = 5, 7, 9
I parametri della popolazione sono:
- μ = 7
- σ2 = 2.66 (varianza)
- σ = 1.63 (deviazione standard)
Estraiamo tutti i possibili campioni di numerosità n = 2 e calcoliamo su ciascuno il valore medio x.

Per riassumere le proprietà della distribuzione campionaria della media:
La forma della distribuzione campionaria della media dipende dalla n (numerosità dei campioni). Se n è piccolo (numerosità scarsa) la media sarà meno precisa.
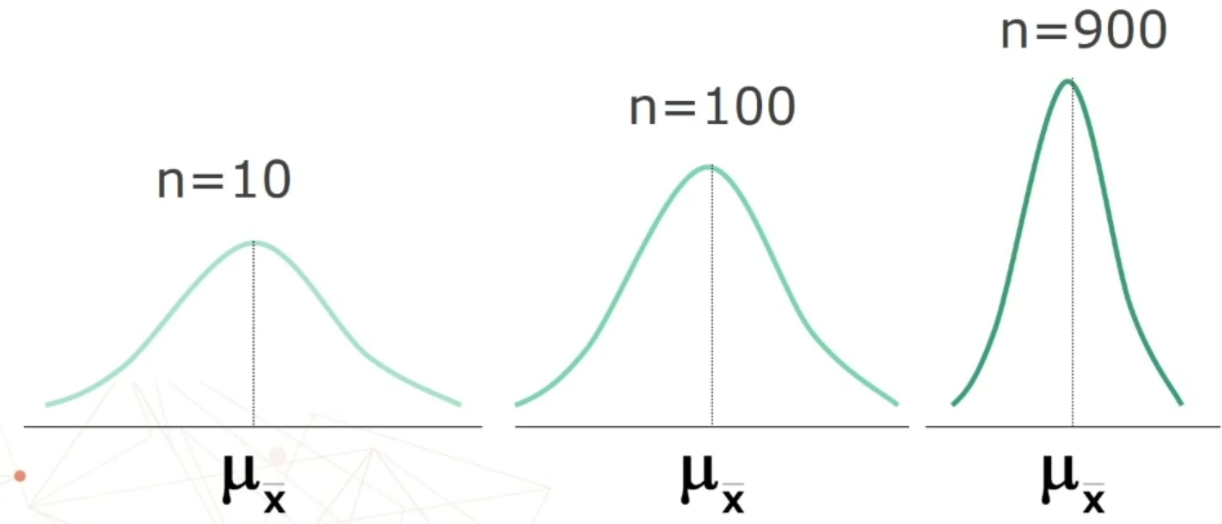
Se si estraggono ripetuti campioni di ampiezza n da una popolazione, qualunque sia la forma della distribuzione nella popolazione,
con l’aumento di n, la distribuzione campionaria della media tende ad avvicinarsi alla normale e può essere considerata normale per n ≥ 30.
Uso della distribuzione campionaria della media
La distribuzione campionaria della media (dCM) si ottiene calcolando la media di ciascun campione estratto da una popolazione con una sua distribuzione con μ e σ.
La media della dCM è la media delle medie di tutti i campioni. La deviazione standard si calcola con gli scarti di ciascuna media campionaria dalla media delle medie.
La POPOLAZIONE può avere dunque distribuzione:
- Normale
- Diversa dalla normale
- Non nota
Se n > 30, la distribuzione delle medie dei campioni da essa estratti è NORMALE, per qualsiasi distribuzione della variabile. Per fare le nostre inferenze sulla popolazione, partendo dai dati campionari, faremo riferimento alla normale e normale standardizzata, impiegando z.
Se n < 30, la distribuzione delle medie dei campioni da essa estratti NON è NORMALE, per qualsiasi distribuzione della variabile.
Per fare le nostre inferenze sulla popolazione, partendo dai dati campionari, faremo riferimento alla distribuzione teorica di probabilità t di Student, impiegando t.
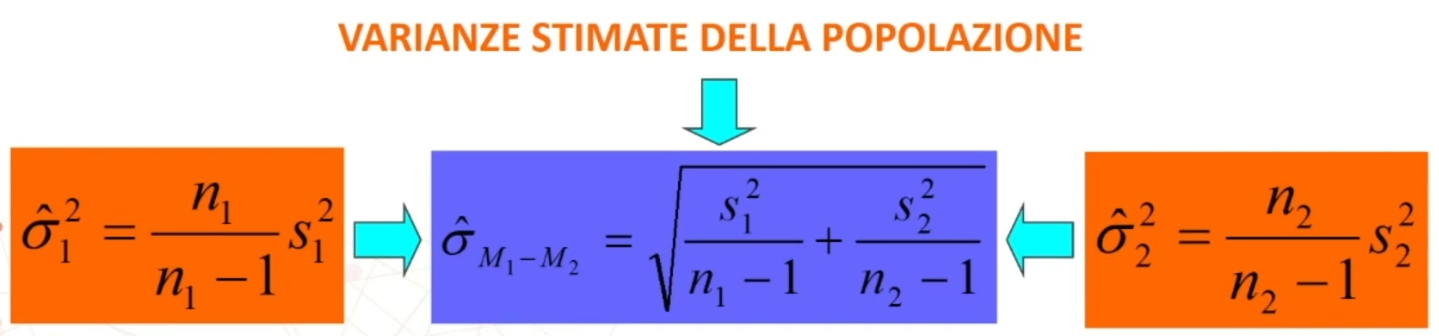
Distribuzione campionaria della differenza tra le medie
Per fare il confronto tra due diverse popolazioni possiamo fare riferimento alla DISTRIBUZIONE CAMPIONARIA DELLA DIFFERENZA TRA MEDIE (dCDM).
Se si estraggono da due popolazioni distribuite normalmente (con medie μ₁ e μ₂, varianze σ₁² e σ₂²) un gran numero di campioni indipendenti di ampiezza n₁ e n₂, e si calcola la differenza tra le loro medie ottengo la (dCDM)
La dCDM è caratterizzata da:
- una media (μM1-M2);
- un errore standard (σM1-M2).
Se n₁ e n₂ sono maggiori di 30, per il Teorema del limite centrale, la dCDM è normale qualunque sia la distribuzione delle popolazioni.
La media della distribuzione campionaria della differenza tra medie è uguale alla differenza delle medie μ₁ e μ₂ delle due popolazioni:
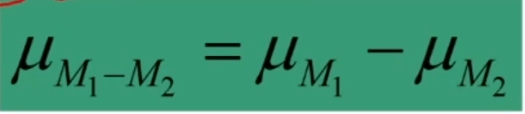
L’errore standard è uguale alla radice quadrata della somma delle varianze σ₁² e σ₂² delle due popolazioni fratto le rispettive ampiezze campionarie n₁ e n₂:
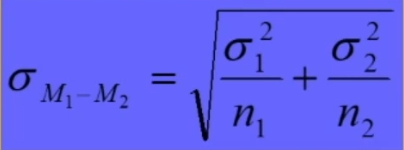
Usando questo errore standard possiamo riscalare la differenza osservata fra le due medie in termini di errore standard (trasformazione in z).
Spesso in psicologia non abbiamo la minima idea di quali siano le varianze delle popolazioni. Dobbiamo quindi stimare l’errore standard a partire dalle varianze dei campioni che abbiamo tratto dalle popolazioni.
Se σ₁² e σ₂² non sono note, occorre stimarle a partire da s₁² e s₂² → Stima dell’errore standard