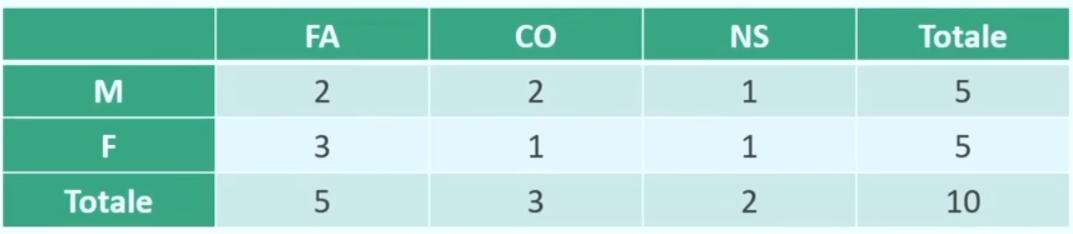
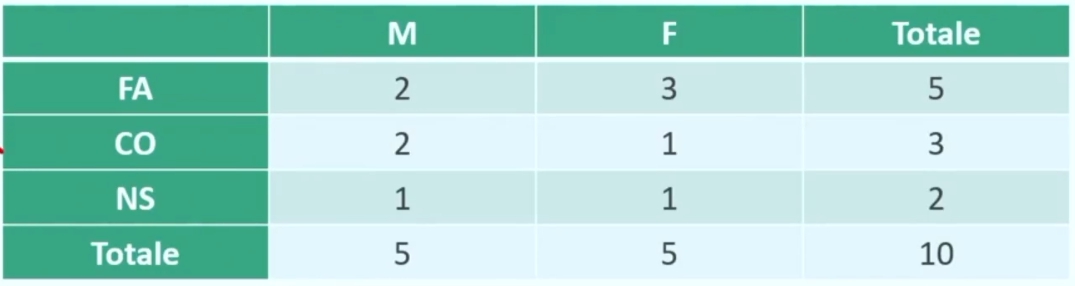
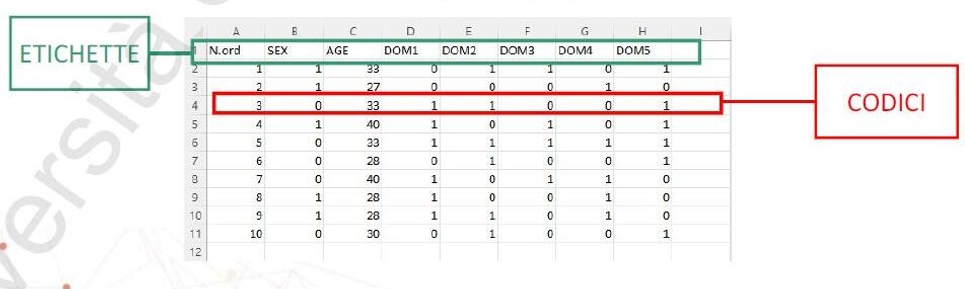
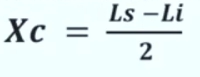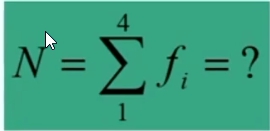Table of Contents
Indicatori di tendenza centrale
Il ricercatore è interessato allo studio di fenomeni che variano. Proprio questa variabilità consente di stabilire dei nessi e di formulare ipotesi.
A tal fine, è necessario identificare parametri che sono capaci di riassumere la variabilità dei dati grezzi e descrivere l’oggetto di ricerca.
I due parametri fondamentali che consentono di sintetizzare i dati sono:
- INDICATORE DI TENDENZA CENTRALE → valore che rappresenta un insieme dei dati grezzi.
- INDICATORE DI DISPERSIONE → valore che specifica la variabilità di un insieme di dati grezzi.
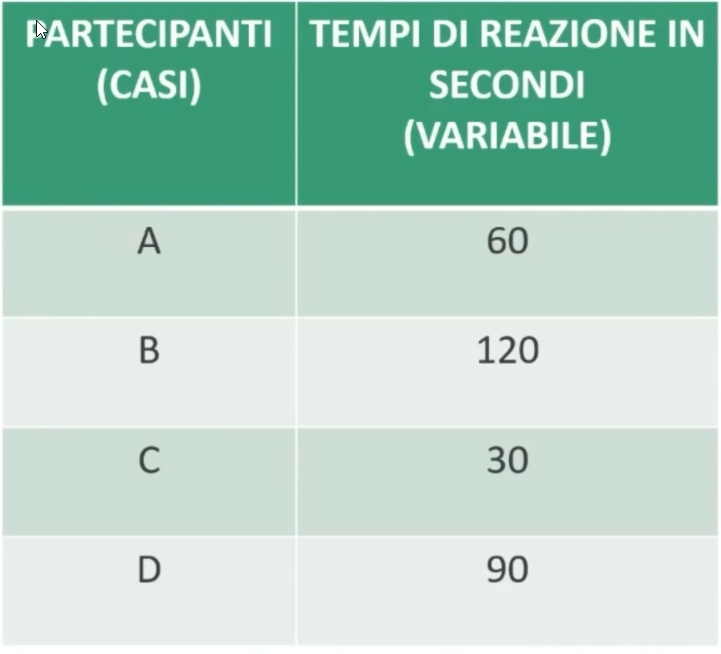
Ad esempio, potremmo essere interessati a confrontare la prestazione complessiva di due diversi gruppi ad una medesima prova. In questo caso sarebbe utile disporre di un valore o parametro capace di rappresentare la prestazione complessiva fornita da ciascun gruppo.
Tale valore o parametro è definito INDICATORE DI TENDENZA CENTRALE.
Il valore o parametro maggiormente adeguato per descrivere l’insieme di dati grezzi sarà diverso in funzione della scala di misura attraverso cui sono stati rilevati i dati (cioè, scala nominale, ordinale, a intervalli o rapporti equivalenti). A ciascuna scala di misura corrisponde un INDICATORE DI TENDENZA CENTRALE capace di rappresentare in modo maggiormente efficace il relativo insieme di dati.
Gli indicatori che consentono di sintetizzare un insieme di dati tramite un unico valore sono tre: moda, mediana e media
Moda
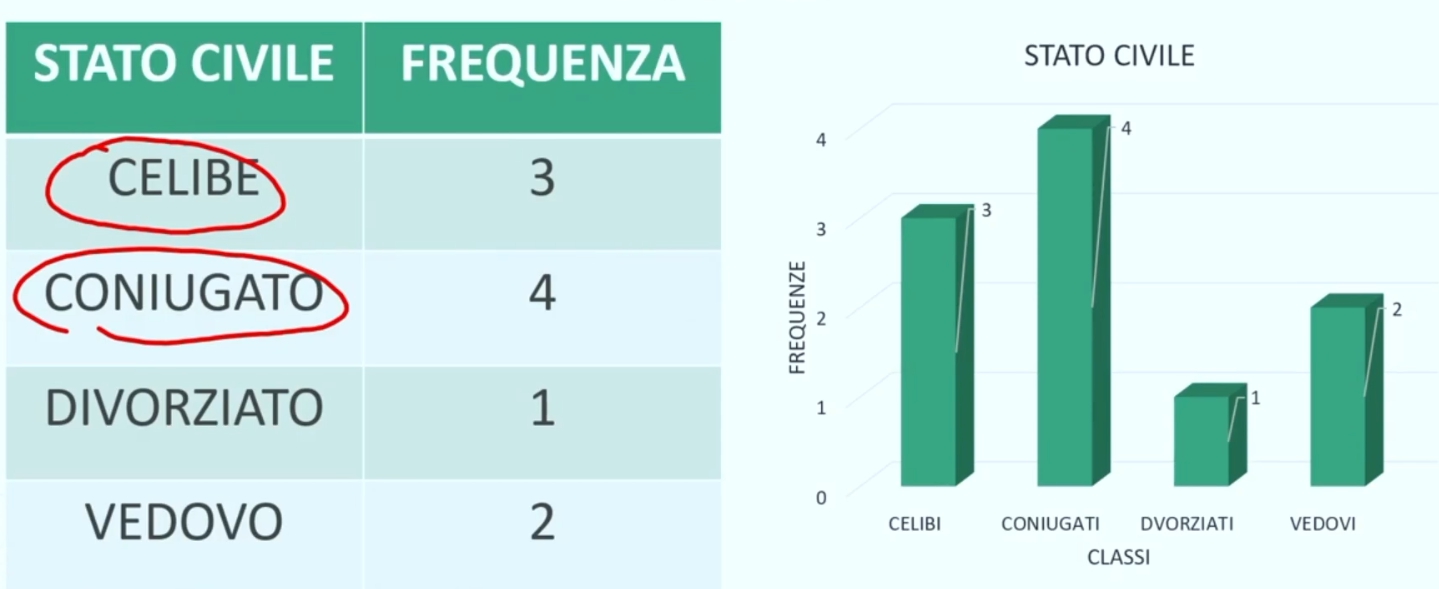
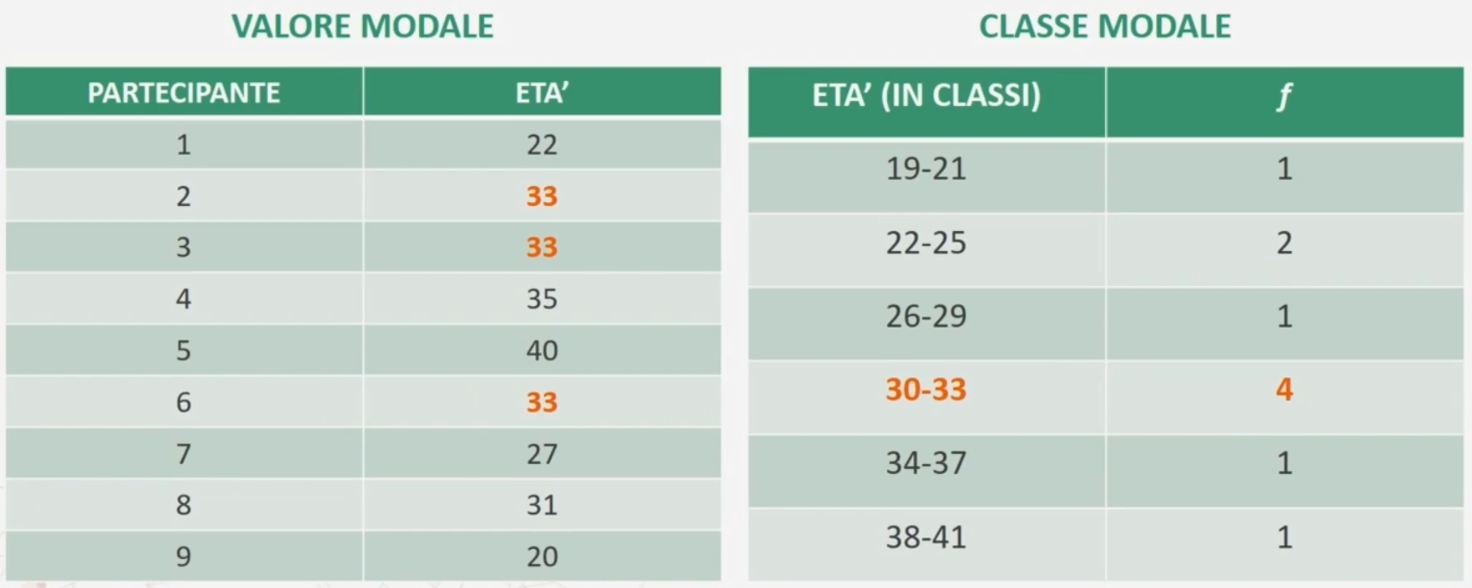
La moda corrisponde alla modalità di una variabile che si presenta con una frequenza maggiore all’interno della distribuzione oggetto di studio. Viene indicata con Mo. Tale modalità è altresì detta valore modale.
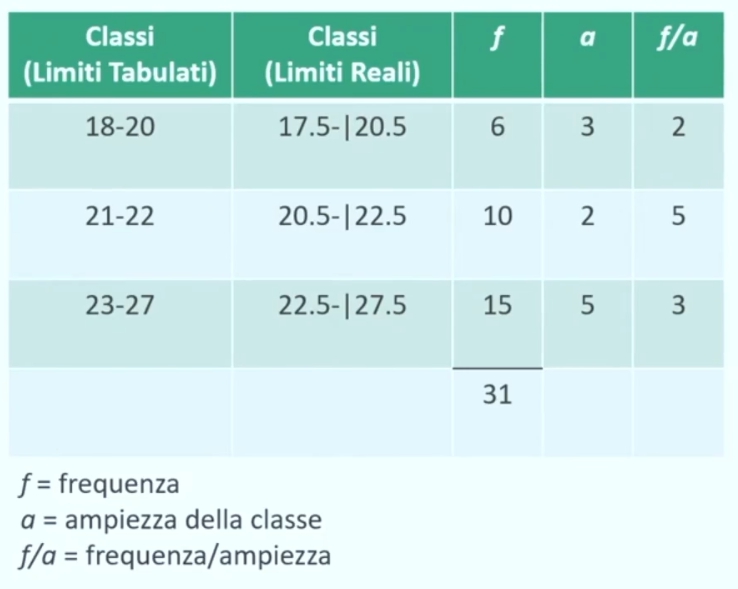
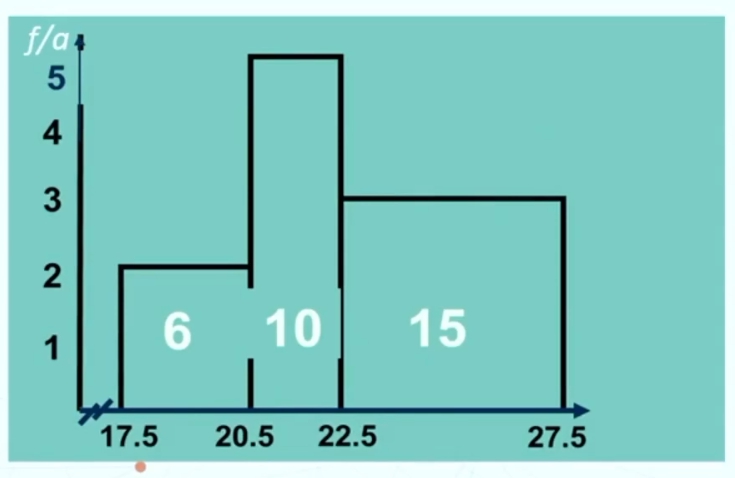
Nel caso la distribuzione di frequenza oggetto di studio è in classi si parla di classe modale.
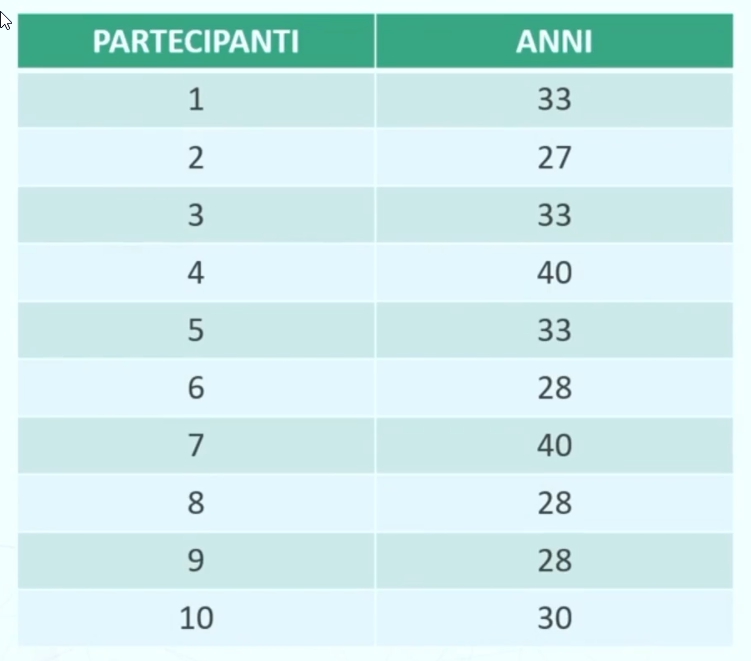
Esempio con moda 33 (valore che si presenta più volte) e classe modale 30-33 (che ha la frequenza maggiore, ovvero 4)
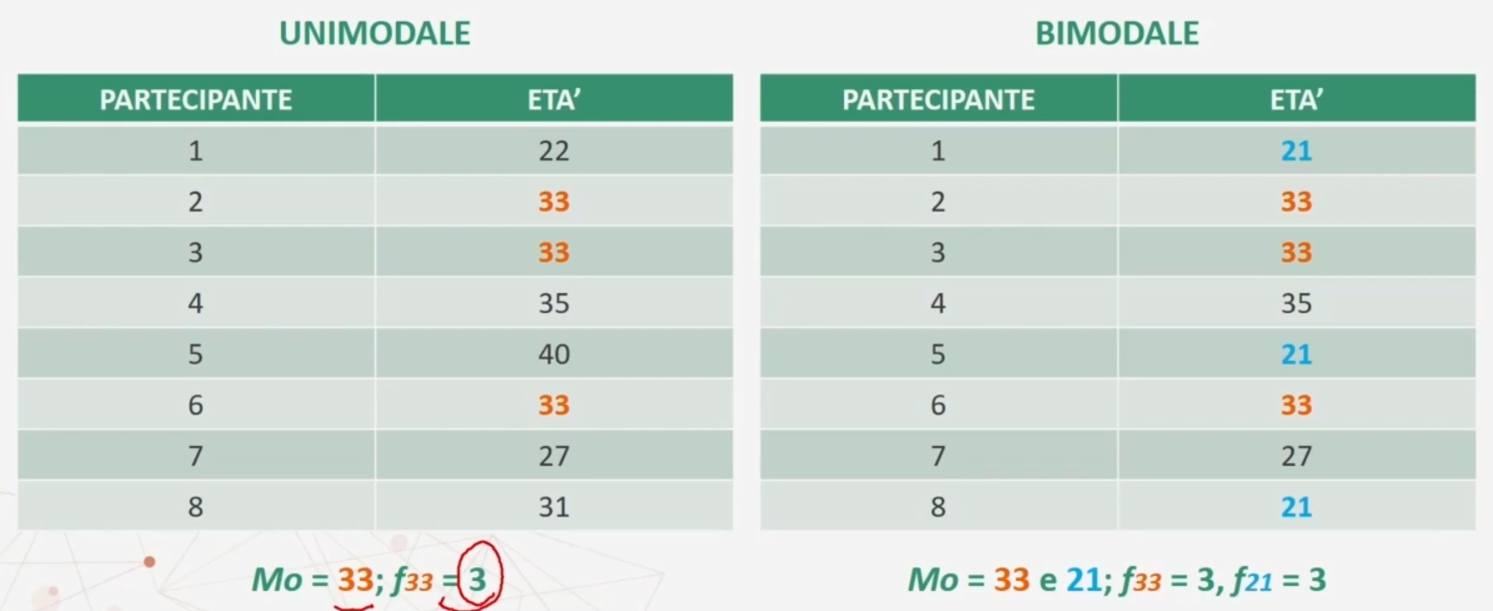
Una distribuzione di frequenza può avere più di un valore o classe modale:
- DISTRIBUZIONE UNIMODALE → la moda è definita da un unico valore.
- DISTRIBUZIONE BIMODALE → la moda è definita da due valori.
Esempio di una distribuzione unimodale e bimodale. Nel primo caso la moda è 33. Nel secondo caso la moda è composta due valori, 33 e 21. In entrambi i casi ho frequenza 3 (la più alta).
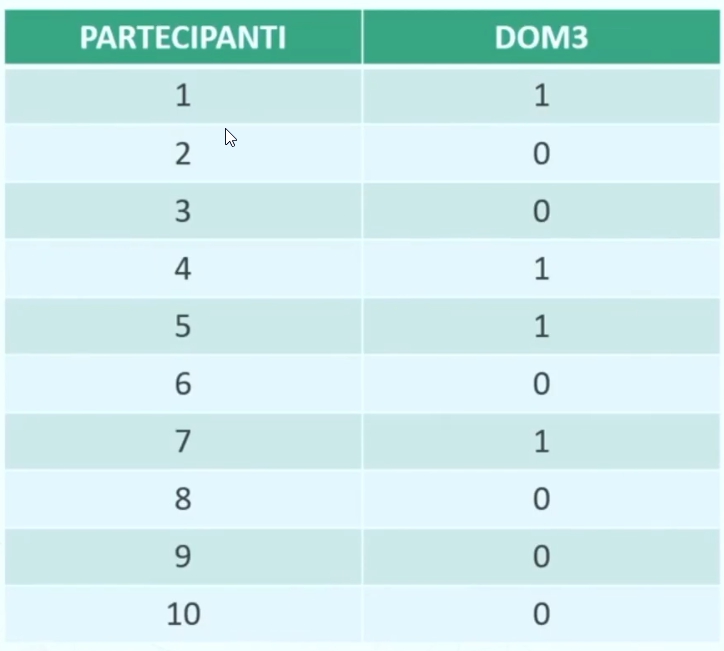
La moda può essere ottenuta con dati rilevati con tutte le scale di misura (cioè, nominale ordinale, a intervalli o rapporti). Tuttavia, è l’unico indicatore di tendenza centrale che può essere utilizzato per i dati qualitativi, misurati su scala nominale.
Rappresenta un indice puramente descrittivo, poco informativo, poco duttile e ambiguo. Per queste caratteristiche è generalmente poco utilizzato.
Mediana
La MEDIANA corrisponde alla modalità di una variabile che occupa la POSIZIONE CENTRALE in una distribuzione ordinata.
È il valore al di sopra o al di sotto del quale ricade il 50% dei casi (o un uguale numero di casi).
In altre parole, è quel valore che divide la distribuzione in due parti uguali.
Viene indicata con Me o Mdn.
La mediana indica quindi la POSIZIONE CENTRALE (cioè, MEDIANA) di una distribuzione ordinata. La posizione della mediana si ottiene con
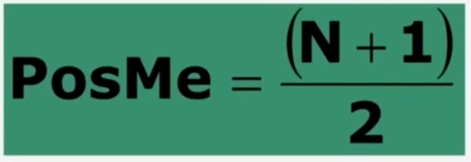
N rappresenta la somma totale dei casi.
Attraverso la formula, siamo in grado di stabilire in corrispondenza di quale caso otteniamo il valore della mediana.
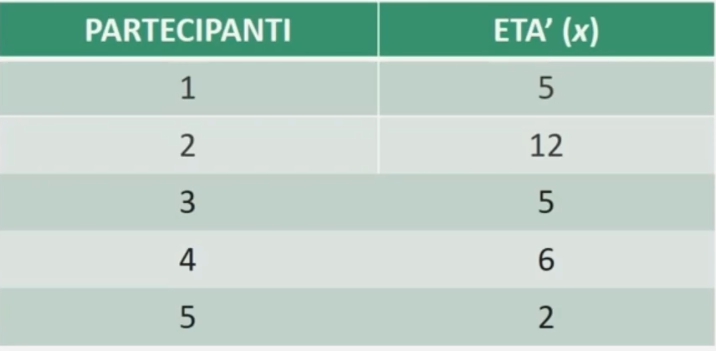
esempio con n=5 dispari: distribuzione di frequenza dell’età di 5 partecipanti. La mediana è rappresentata dal valore corrispondente al caso individuato
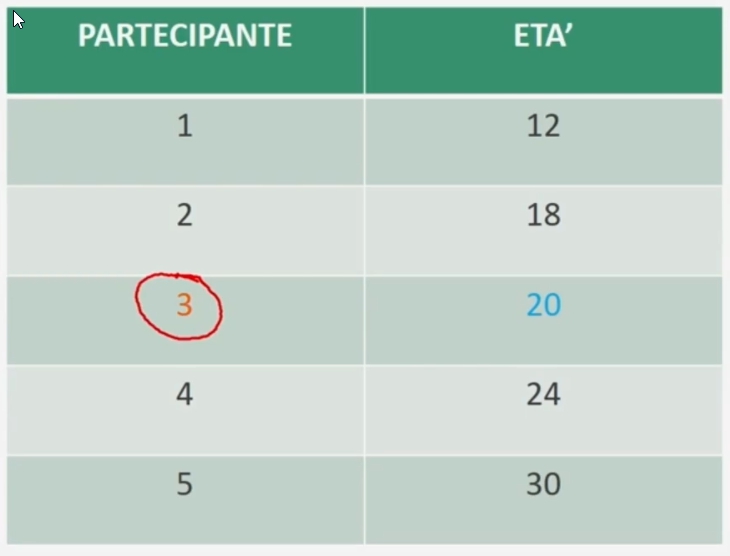
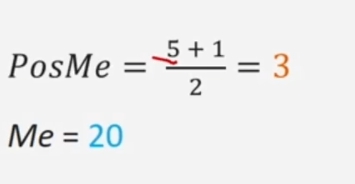
La mediana è rappresentata dal valore che occupa la terza posizione.
Vediamo ora un caso con n=6 pari. La mediana NON è direttamente rappresentata dal valore corrispondente al caso individuato. Occorre calcolare la semisomma dei valori intorno al caso individuato
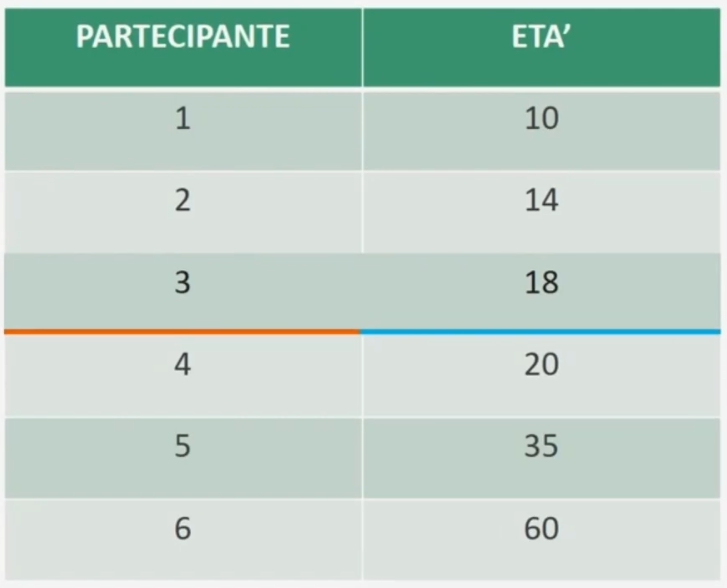
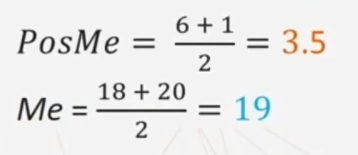
La mediana è rappresentata dal valore che occupa la posizione tra 3 e 4 o 18 e 20.
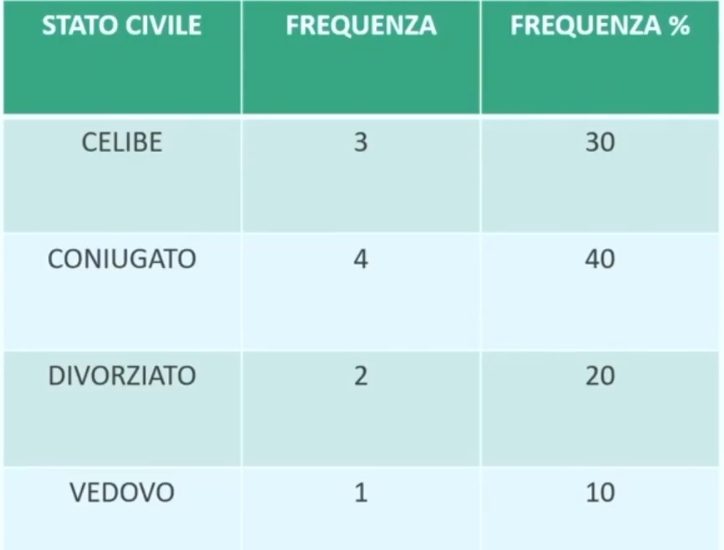
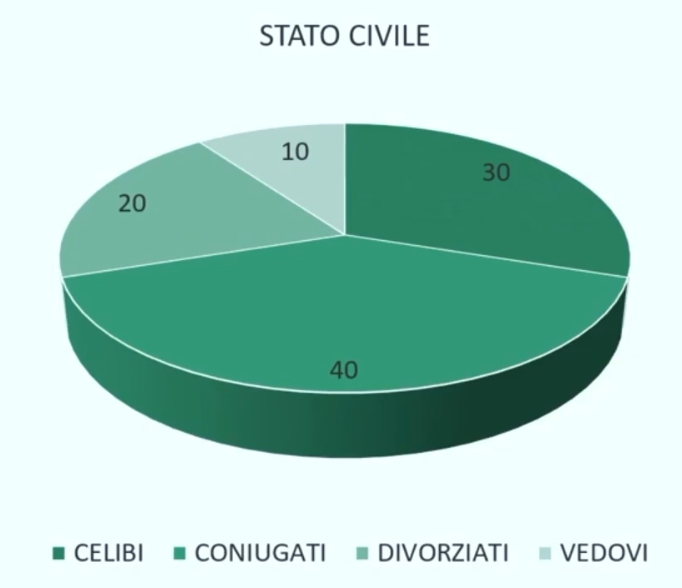
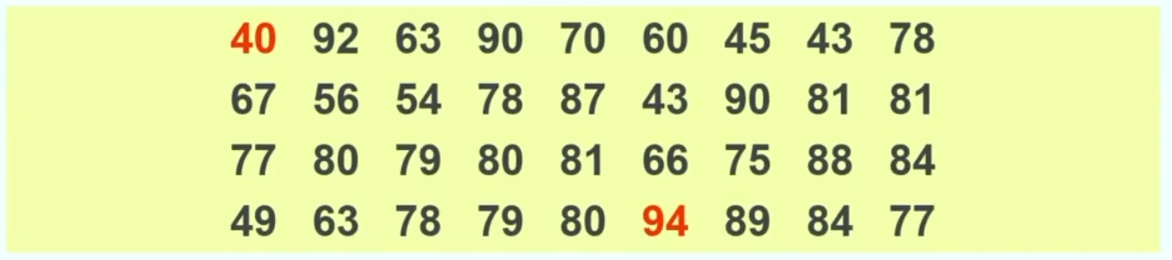
Proviamo a fare un esempio più concreto. Supponiamo di avere le risposte di 100 (Numero di casi pari) e 101 (Numero di casi dispari) partecipanti ad una domanda (“quanto spesso vai al cinema” ordinate secondo una scala di risposta a 6 punti):
6 = più volte a settimana; 5 = una volta a settimana; 4 = una volta al mese; 3 = più volte all’anno; 2 = una volta all’anno; 1 = mai;
Questi sono i dati raccolti
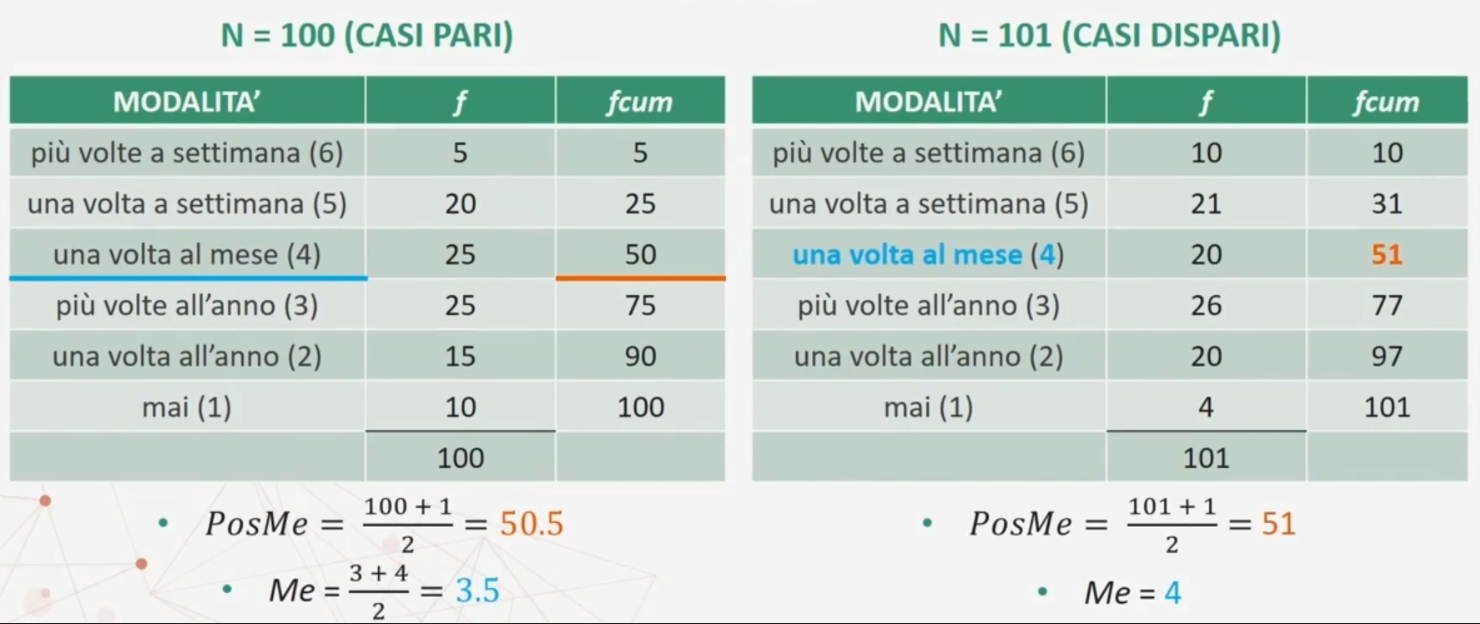
La mediana può essere ottenuta con dati rilevati con scale di misura:
- ordinale
- a intervalli
- a rapporti
La MEDIANA, insieme alla moda, rappresenta l’INDICATORE DI TENDENZA CENTRALE per i dati qualitativi misurati su SCALA ORDINALE.
Media
Il concetto di MEDIA è un concetto comune. Temperatura media di una ragione dell’anno, l’età media di una popolazione, il reddito medio all’interno di una nazione, ecc.
Tutti questi indicatori sono il risultato di una sintesi ed è stata effettuata su un insieme di dati. Ciò che potrebbe essere meno noto, è il procedimento che consente di arrivare a tale indicatore, e soprattutto quali sono le sue caratteristiche indipendenti dall’oggetto che viene misurato.
La MEDIA aritmetica si definisce come la somma delle misure osservate diviso il numero delle osservazioni fatte (totale dei casi).
Viene usualmente indicata con M o con X̄ in relazione al campione.
Quando ci si riferisce alla popolazione si indica con μ.
Nel caso di una serie di dati non raggruppati, la media è calcolabile con una semplice formula.

Dove:
- Σ = sommatoria
- Xi = generica osservazione
- N = totale dei casi osservati
Facciamo un esempio con la media (dati non raggruppati): Proviamo a calcolare l’età media di N = 8 partecipanti.
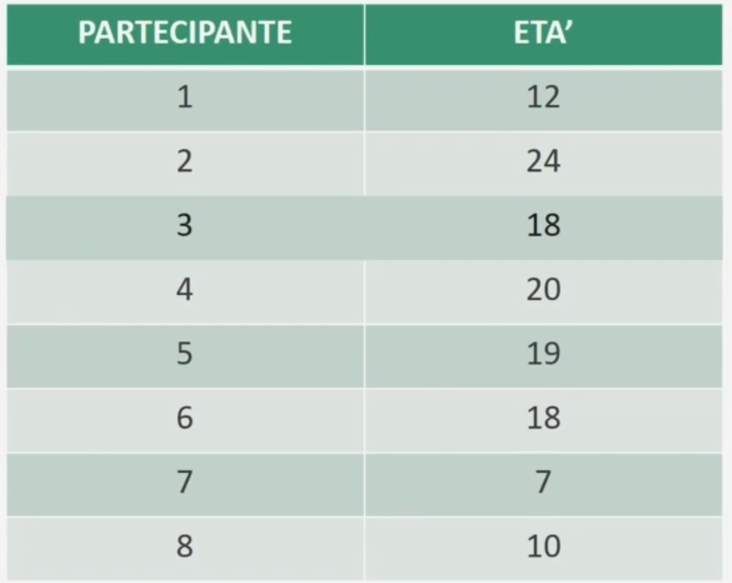
Per ottenere la media si sommano le 8 età dei partecipanti e si divide per il numero totale dei casi:
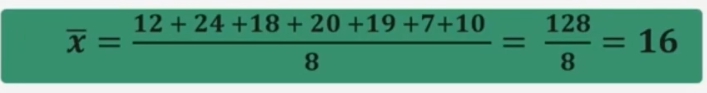
Nel caso di una serie di dati organizzati in una distribuzione di frequenza, la media è calcolabile:
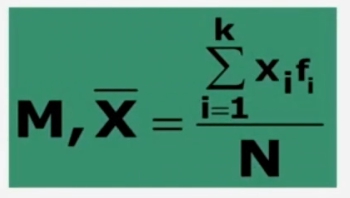
Dove:
- Σ = sommatoria
- Xi = generica osservazione
- fi = frequenza associata a ciascun valore
- k = numero dei diversi valori (modalità di xi)
- N = totale dei casi osservati
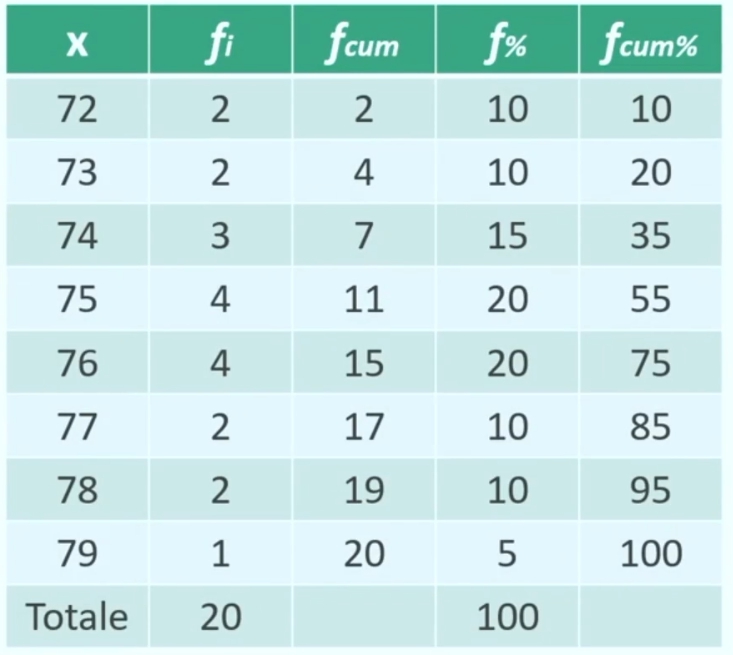
Facendo un esempio proviamo a calcolare l’età media di N = 10 partecipanti.
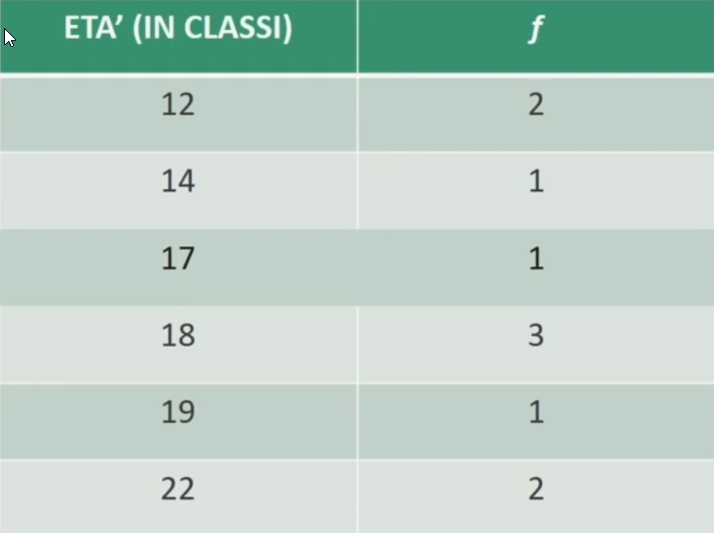
Per ottenere la media si sommano le 10 età dei partecipanti tenendo conto (moltiplicando) della frequenza in cui si presentano, e poi si divide per il numero totale dei casi:

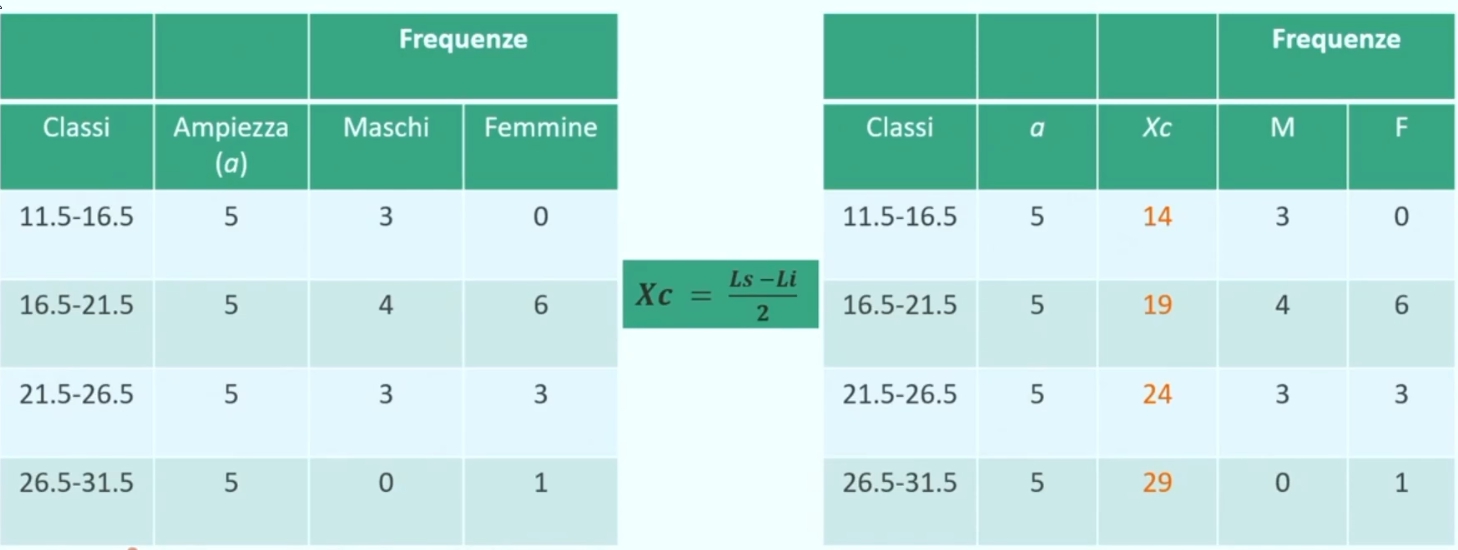
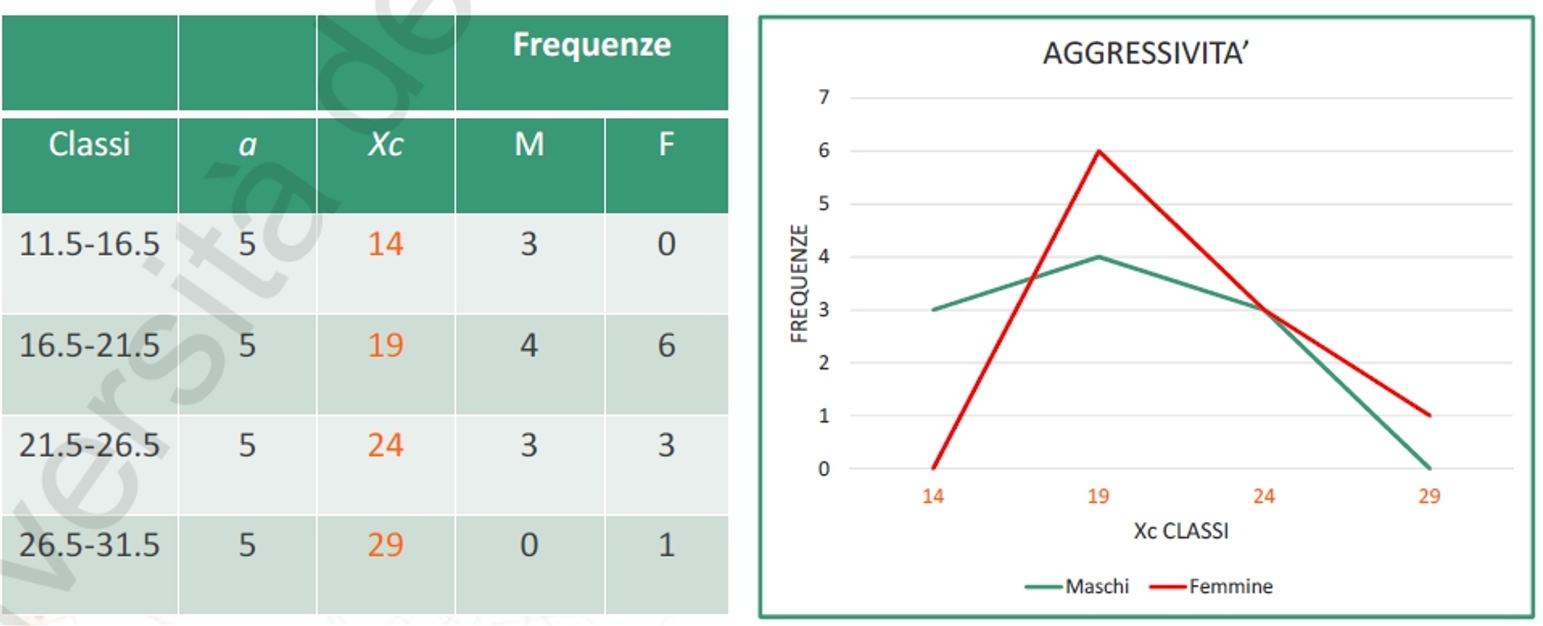
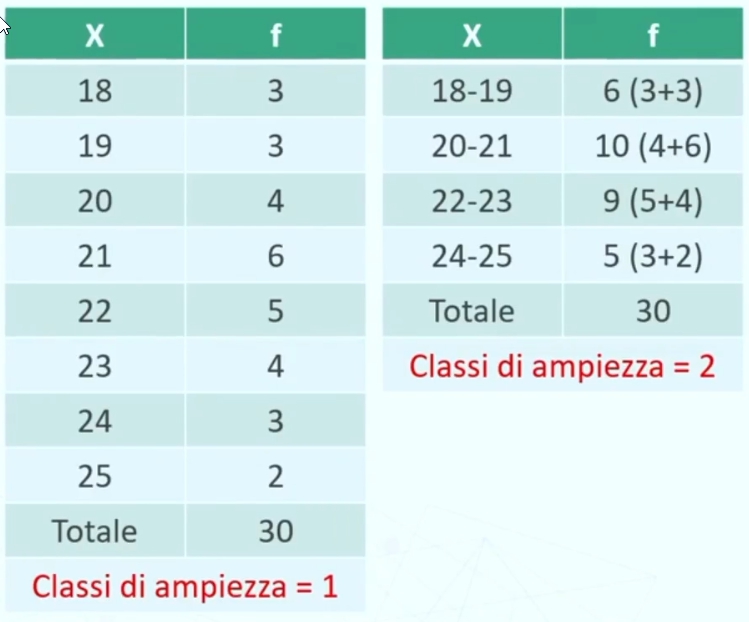
Nel caso di una serie di dati raggruppati in classi di ampiezza > 1, la media è calcolabile:
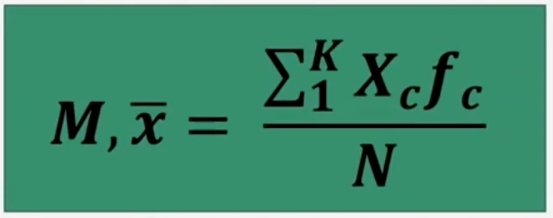
Dove:
- Σ = sommatoria
- Xc = punto medio di classe
- fc = frequenza associata a ciascun classe
- k = numero dei diversi valori (modalità di xi)
- N = totale dei casi osservati
Esempio: Proviamo a calcolare l’età media di N = 10 partecipanti.
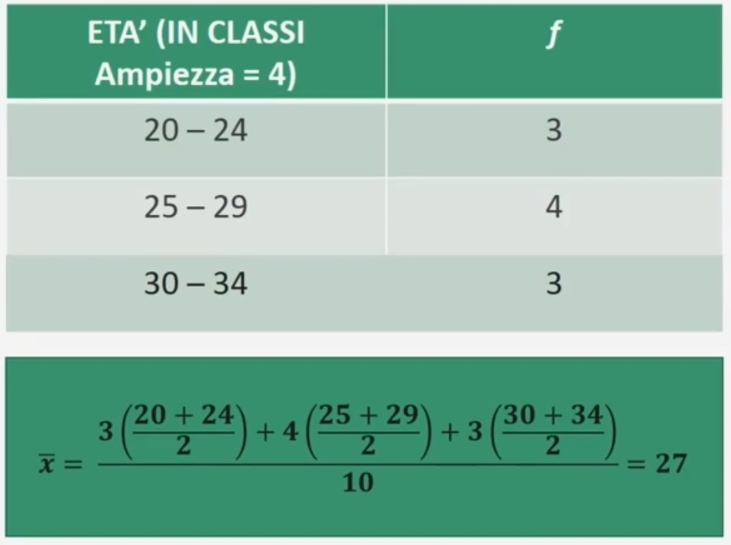
Per ottenere la media Si moltiplica la frequenza di ogni classe per il valore effettivo del punto medio di classe, prima di fare la somma e dividere per il numero totale dei casi
Proprietà della media
La MEDIA aritmetica ha due importanti proprietà che sono alla base di operazioni statistiche più complesse (es, varianza, deviazione standard, regressione, ecc.):
- La somma degli scarti dei singoli valori che compongono la media è sempre uguale a zero.
- La somma dei quadrati degli scarti di ciascun valore dalla media è minore della somma degli scarti degli stessi valori da un qualsiasi altro numero (proprietà dei minimi quadrati).
Vediamo la prima proprietà “La somma degli scarti dei singoli valori che compongono la media è sempre uguale a zero.”
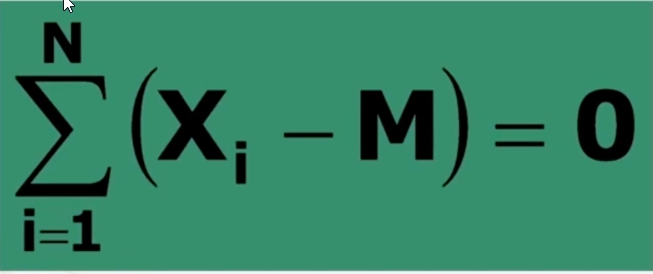
Lo scarto è quanto si discosta ciascun valore dalla sua media.
La dimostrazione è verificabile dalle seguenti immagini


Vediamo ora la proprietà “La somma dei quadrati degli scarti di ciascun valore dalla media è minore della somma degli scarti degli stessi valori da un qualsiasi altro numero (proprietà dei minimi quadrati).”
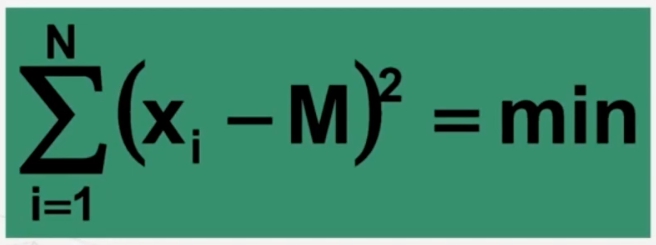
La dimostrazione nella seguente immagine

come si vede 38 > 18 e anche 23 > 18.
In generale possiamo dire che la media può essere ottenuta con dati rilevati con scale di misura:
- a intervalli
- a rapporti
La MEDIA, insieme alla moda e alla mediana, rappresenta l’INDICATORE DI TENDENZA CENTRALE per i dati quantitativi misurati su SCALE METRICHE.
Confronto tra media e mediana
La MEDIA può essere trattata con il CALCOLO ALGEBRICO, mentre la MEDIANA non può esserlo. Questo comporta che la MEDIA può essere PONDERATA per confrontare campioni con N diverso, mentre la MEDIANA non può.
La MEDIANA varia maggiormente passando da un campione all’altro, mentre la MEDIA è più stabile. Questo comporta che la MEDIA può essere utilizzata per la STATISTICA INFERENZIALE, mentre la MEDIANA non può.
Come vantaggio della mediana abbiamo che la MEDIANA è più stabile rispetto ai VALORI ESTREMI, mentre la MEDIA non lo è, comportando svantaggi e svantaggi a seconda dei casi.
Facciamo i seguenti esempi:
Esempio 1: 4, 6, 8, 9, 11, 12, 12 → Me=9 M=8.8
In questo caso media e mediana sono pressoché identiche.
Esempio 2: 4, 6, 8, 9, 11, 12, 56 → Me=9 M=15.1
In questo caso la mediana è più rappresentativa dei dati.
Esempio 3: 4, 6, 8, 9, 91, 92, 96 → Me=9 M=44.3
In questo caso la media è maggiormente rappresentativa.
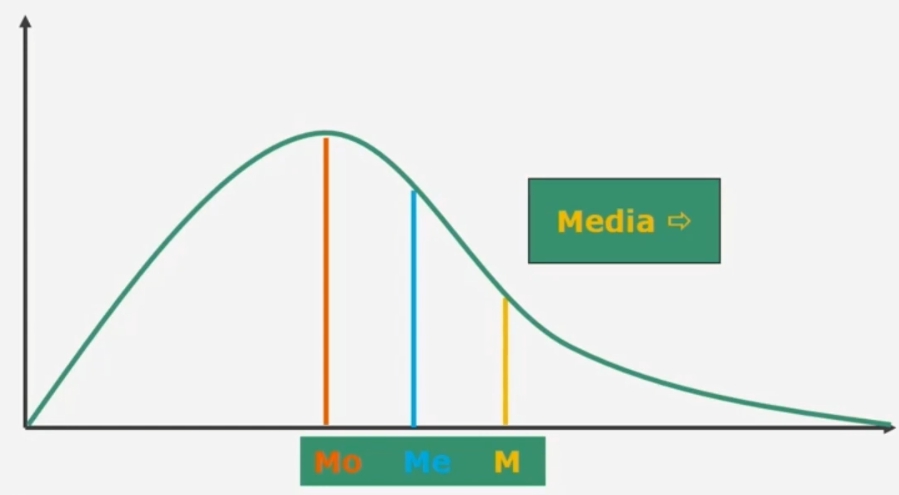
Confronto tra moda, media e mediana
Nel caso di una distribuzione simmetrica media moda e mediana coicidono.
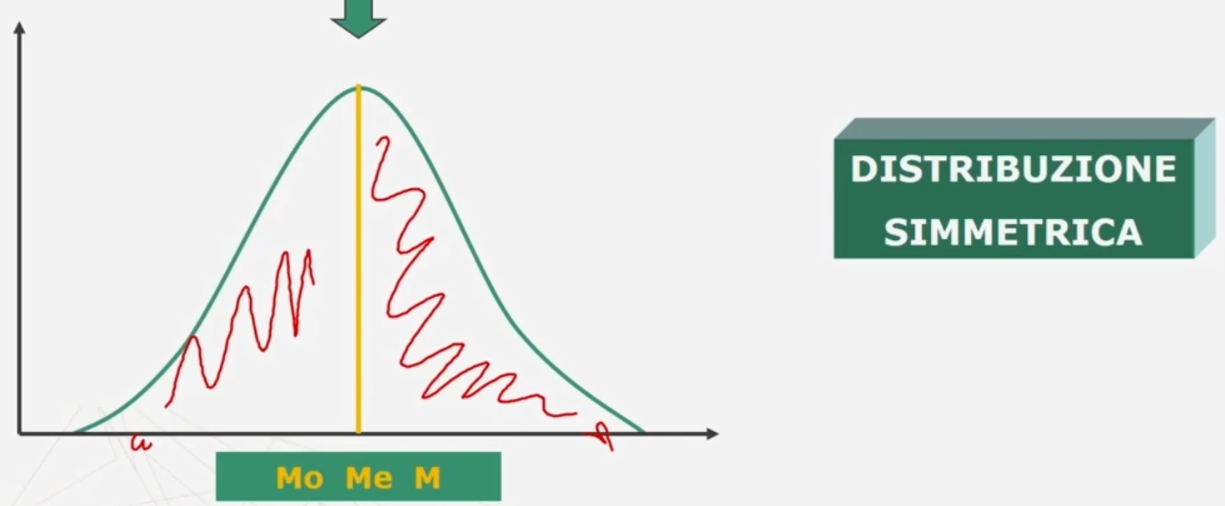
Nel caso di una distribuzione asimmetrica negativa e positiva
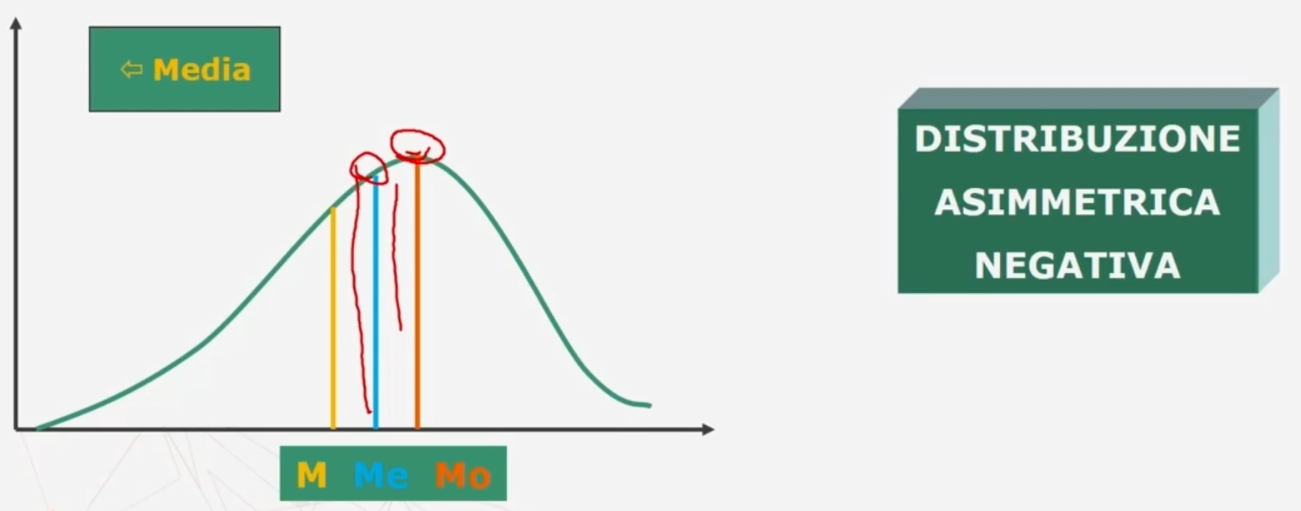
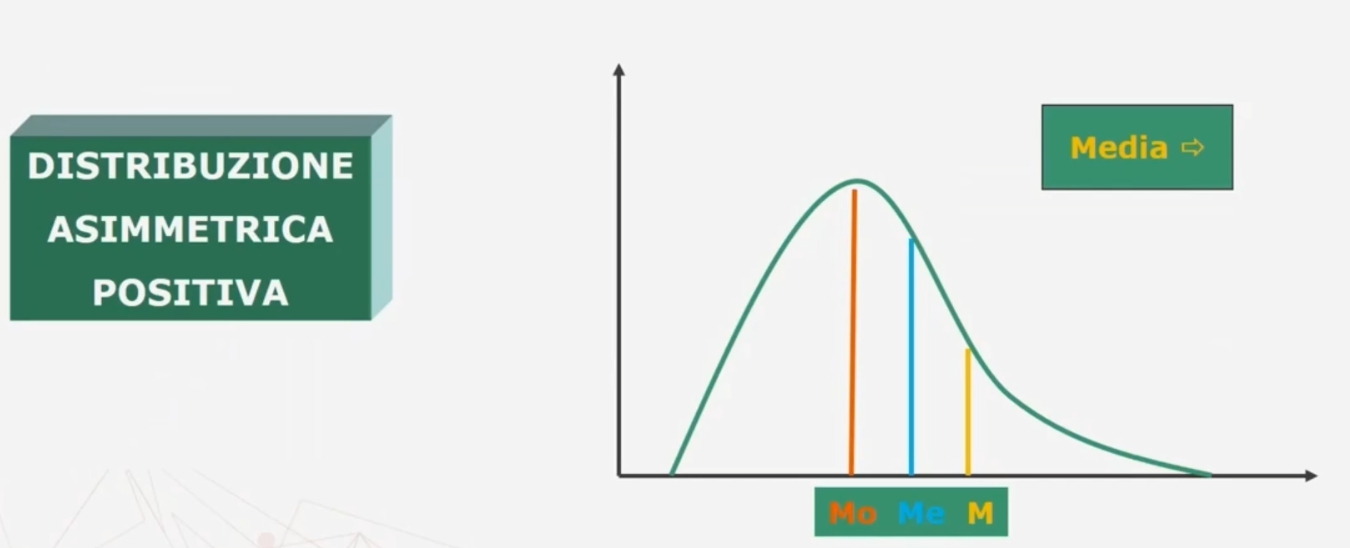
Se esiste una forte asimmetria (sia positiva che negativa) è preferibile la mediana alla media (come in questo caso)