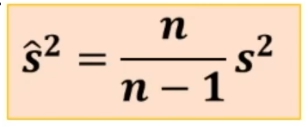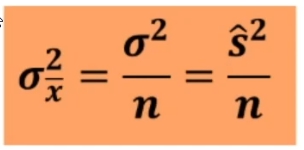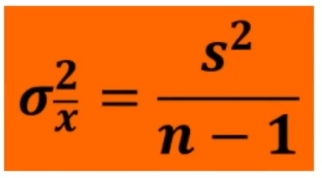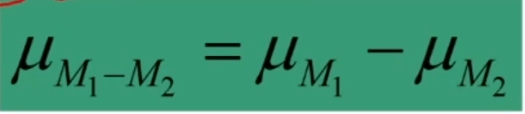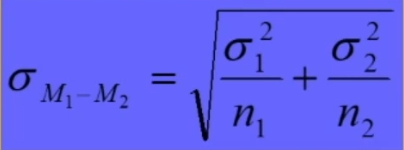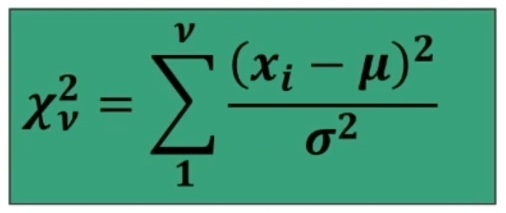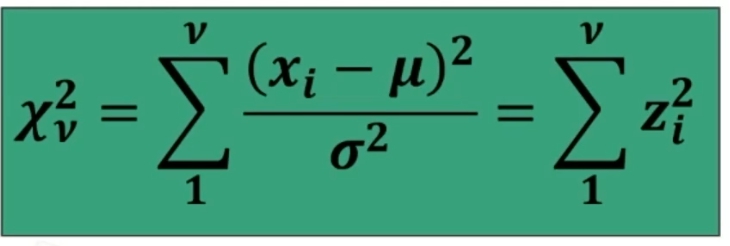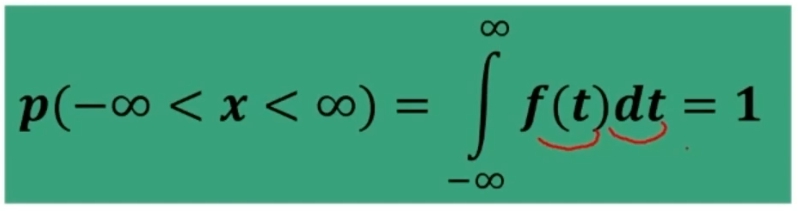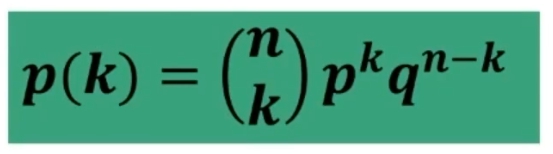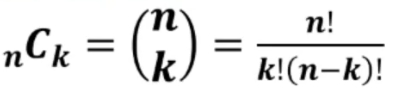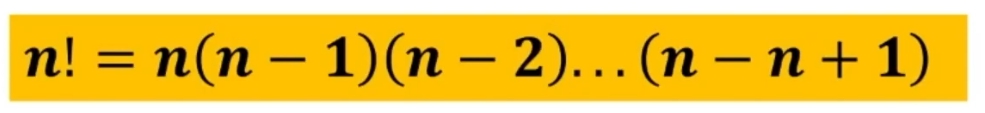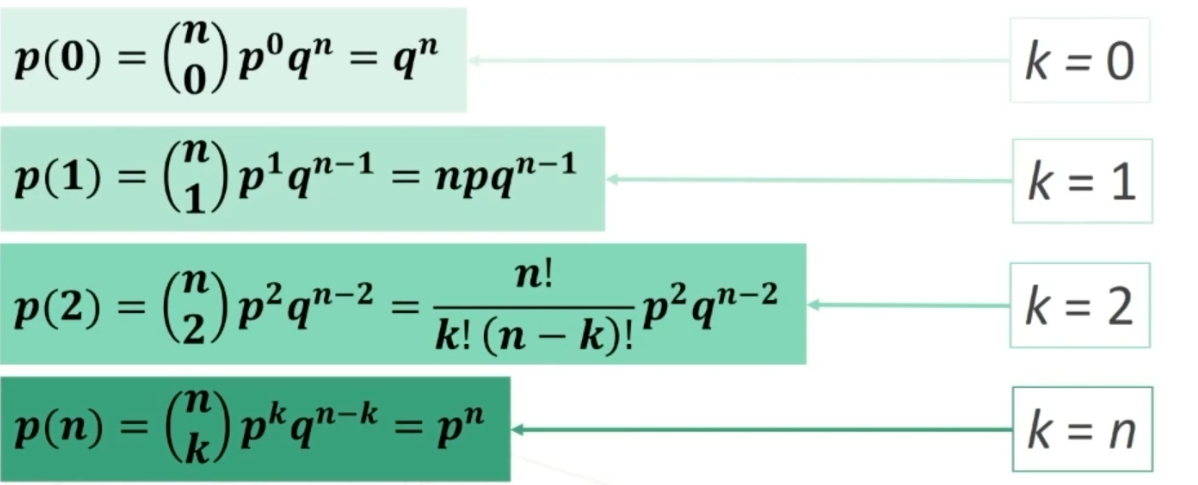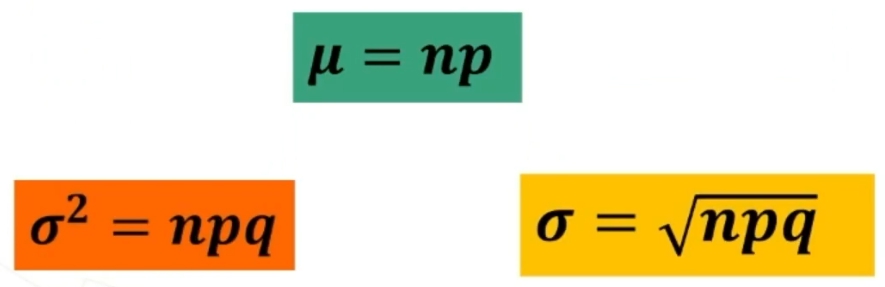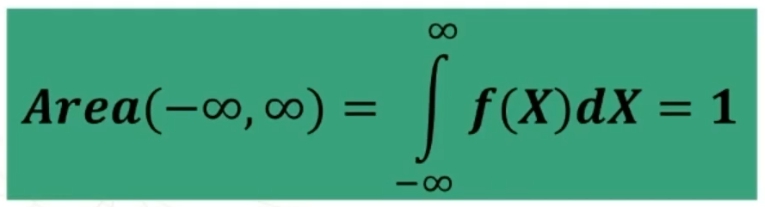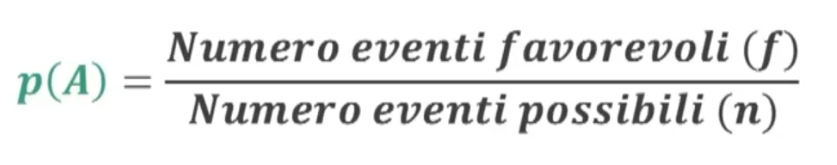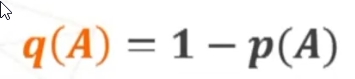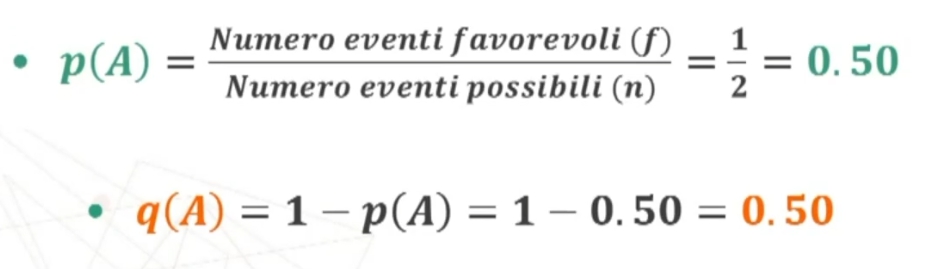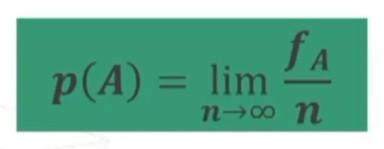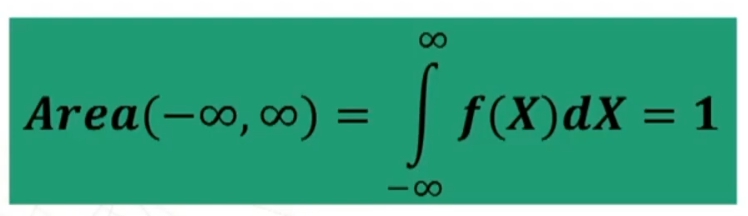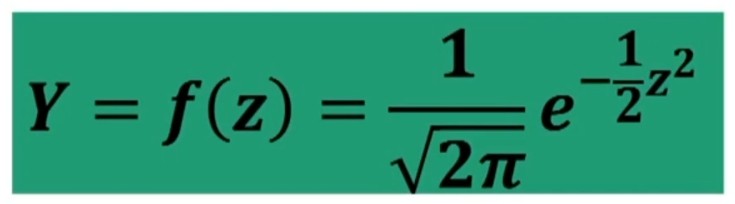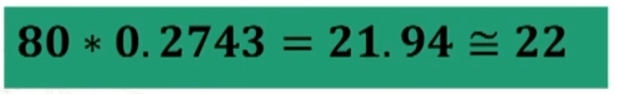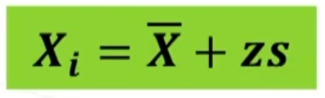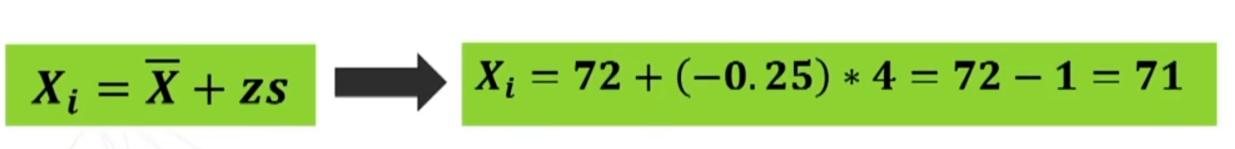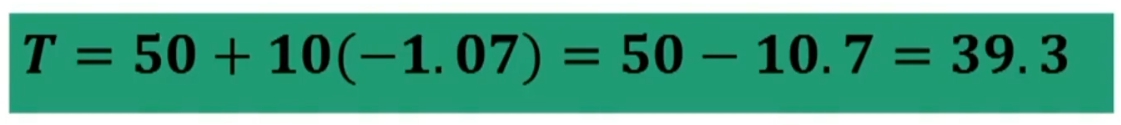Table of Contents
Uso della distribuzione campionaria della media
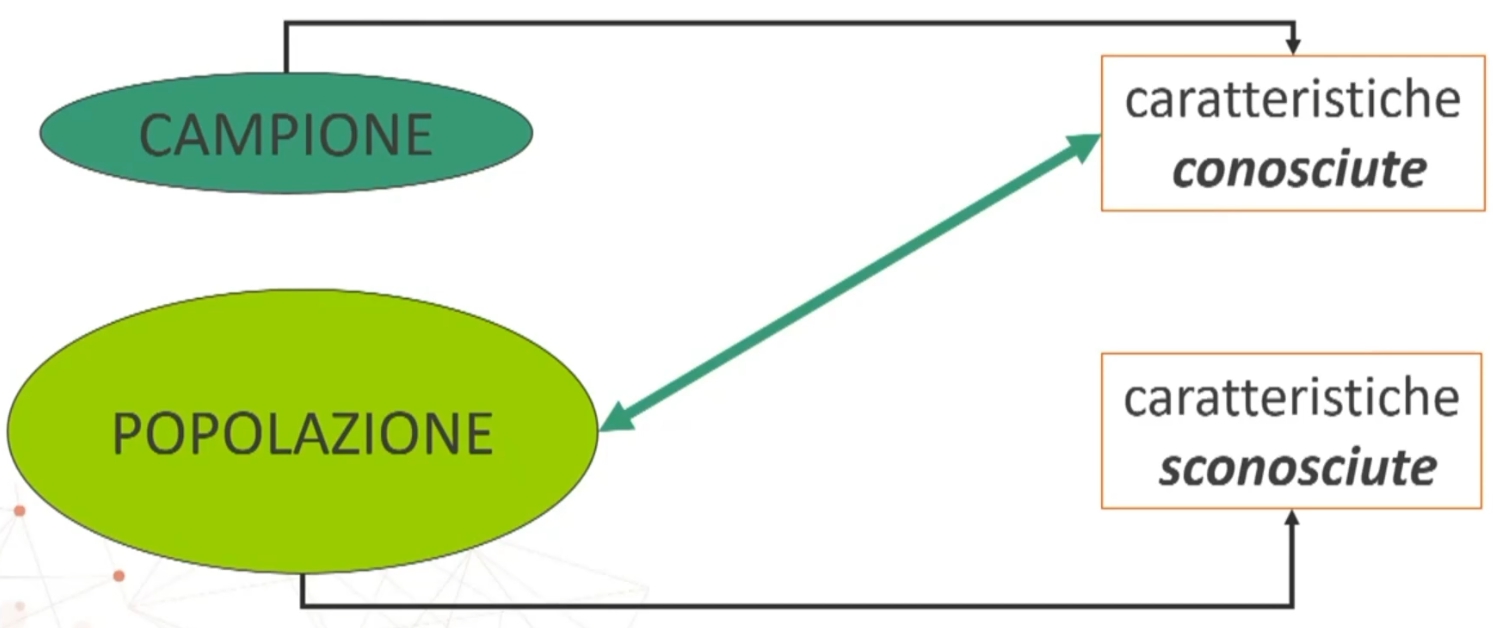
Statistica inferenziale
Abbiamo visto che nella statistica inferienziale possiamo studiare le caratteristiche della popolazione studiando le caratteristiche su un campione di interesse.
Con la statistica inferienziale possiamo ottenere i seguenti risultati:
- Teoria della verifica dell’ipotesi: si verifica, in termini probabilistici, se una certa affermazione relativa alla popolazione è da ritenersi vera sulla base dei dati campionari
- Teoria della stima dei parametri: si stabilisce, in termini probabilistici, il valore numerico di uno o più parametri incogniti della popolazione a partire dai dati campionari
Per conoscere le caratteristiche della popolazione posso procedere sequenzialmente nel seguente modo:
- Estraggo un campione in modo casuale
- Misuro la statistica (indicatore) sul campione (attraverso dei test per esempio)
- Con la STATISTICA INFERENZIALE definisco, in termini probabilistici, il parametro della popolazione a partire dalla statistica del campione
Uso della distribuzione campionaria della media
In questo processo gioca un ruolo fondamentale la distribuzione campionaria della media (dcm).
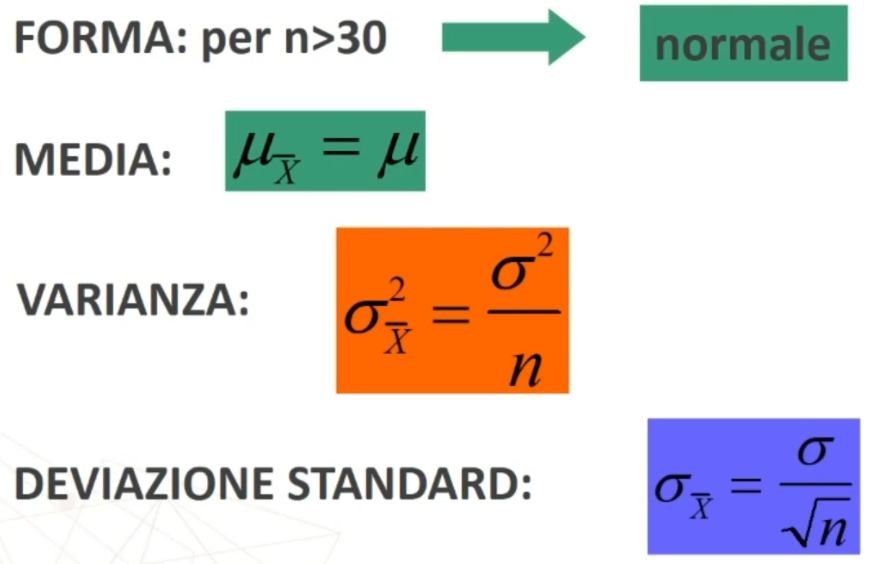
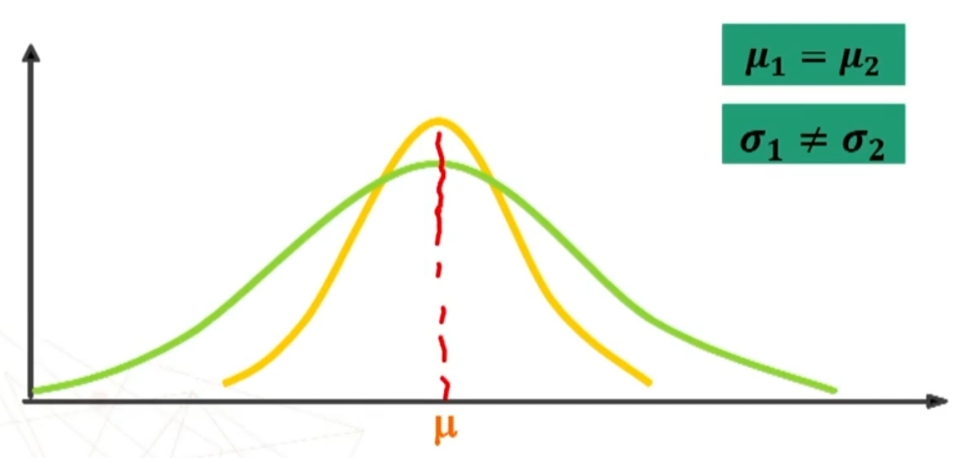
La dcm la si ottiene calcolando la media di ciascun campione estratto da una popolazione con una sua distribuzione con μ e σ
La media della dcm è la media delle medie, la deviazione standard si calcola con gli scarti di ciascuna media campionaria dalla media delle medie.
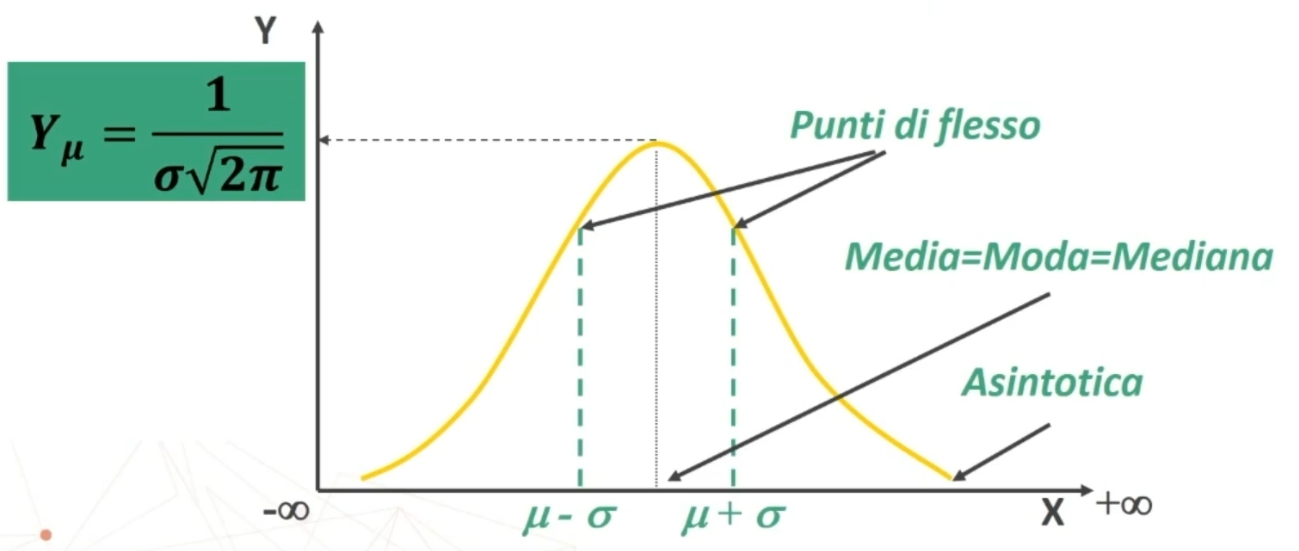
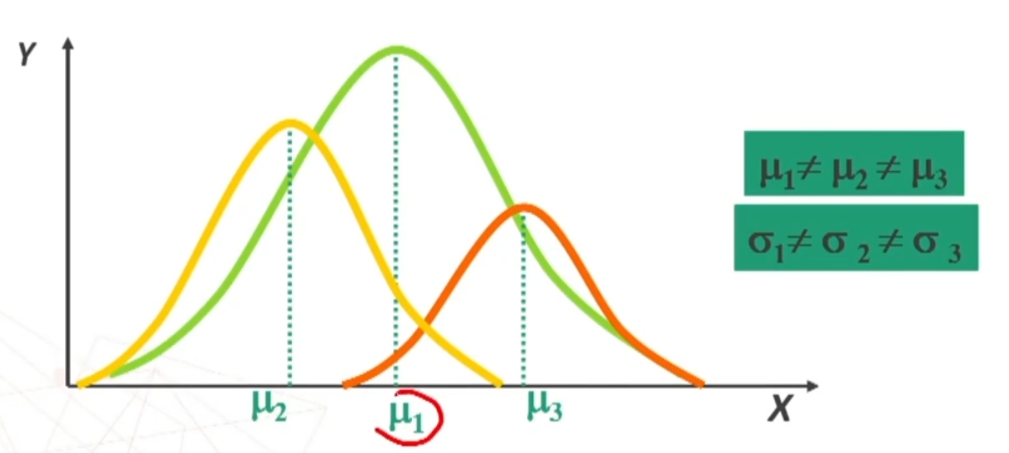
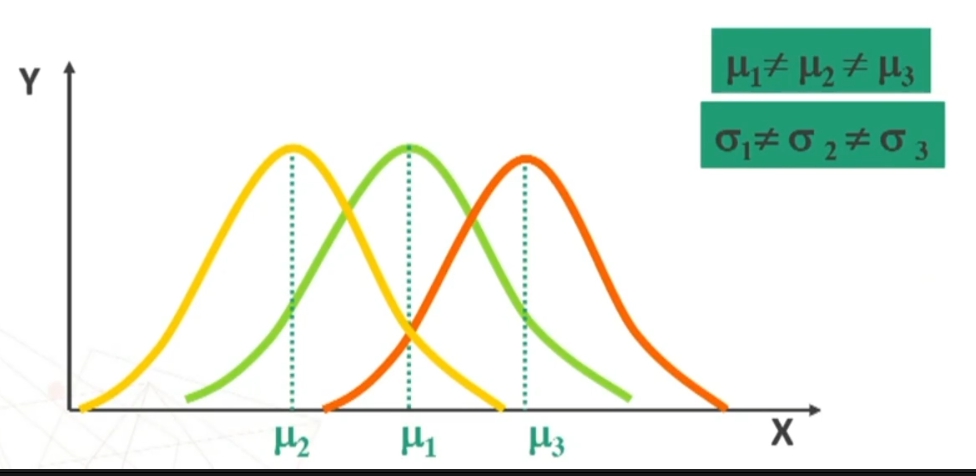
La POPOLAZIONE può avere distribuzione: normale, diversa dalla normale, non nota.
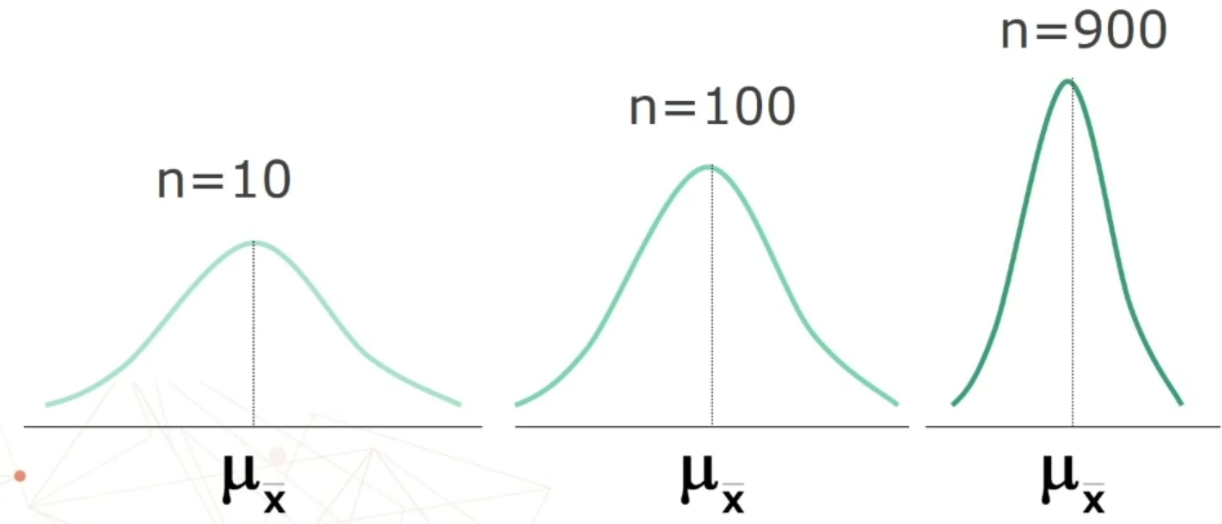
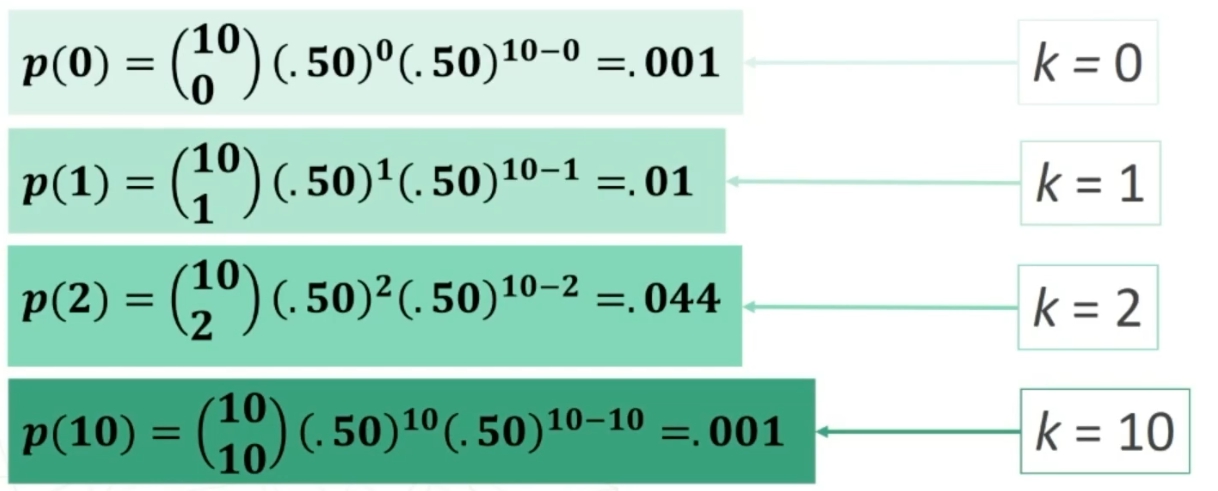
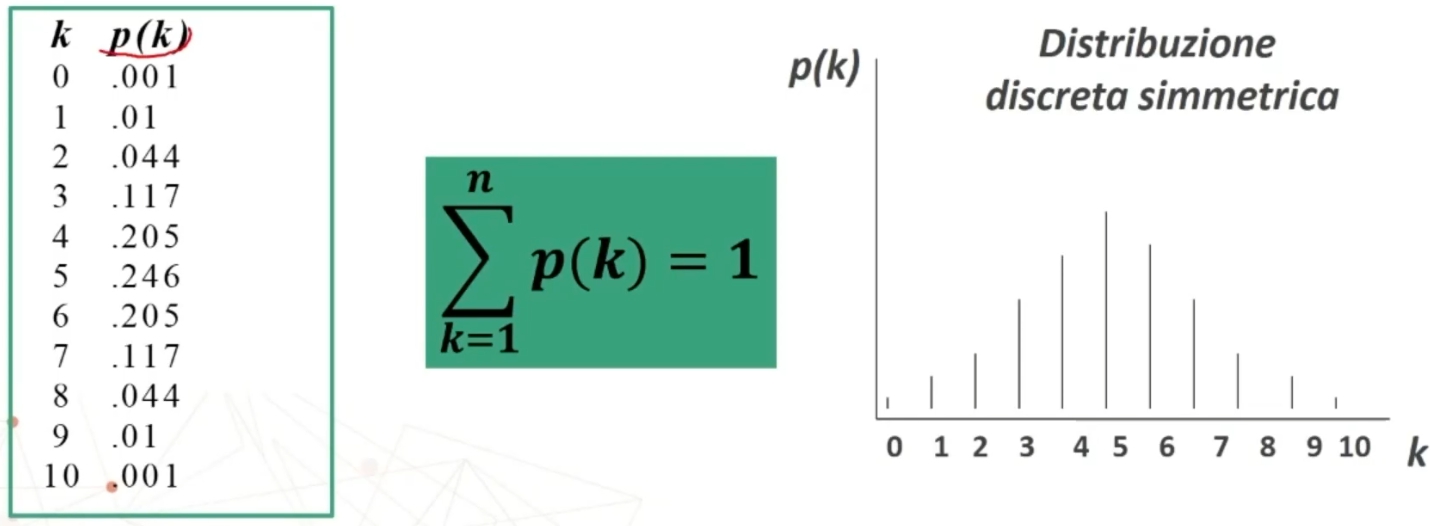
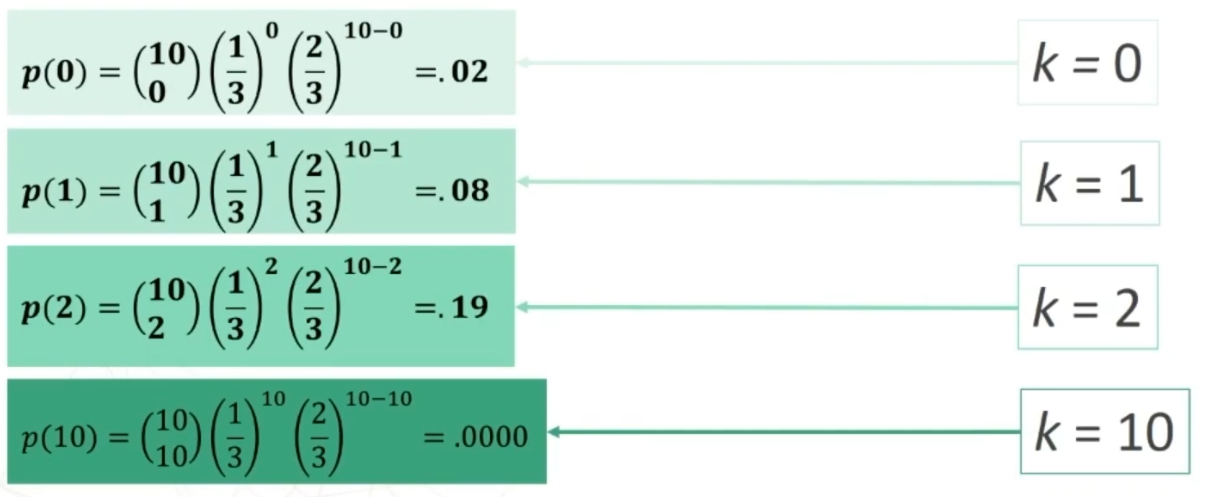
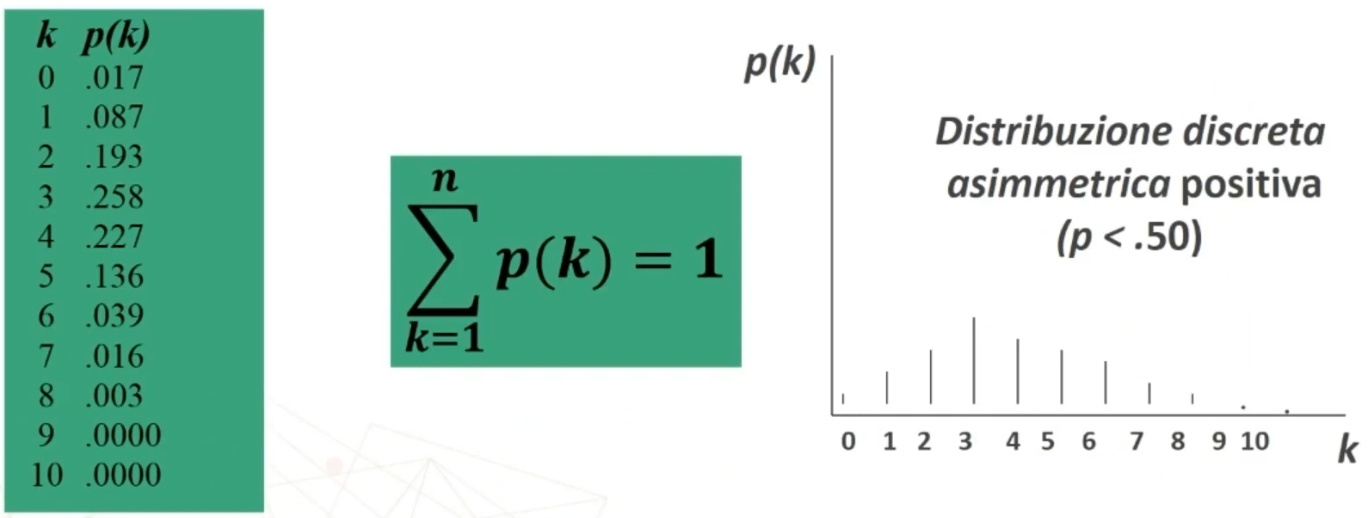
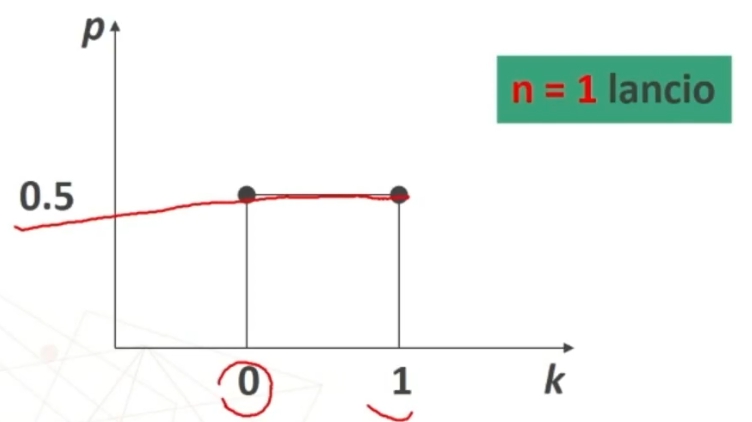
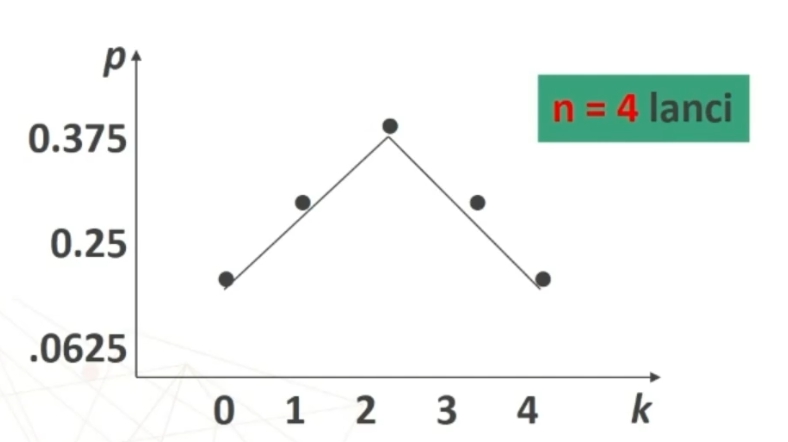
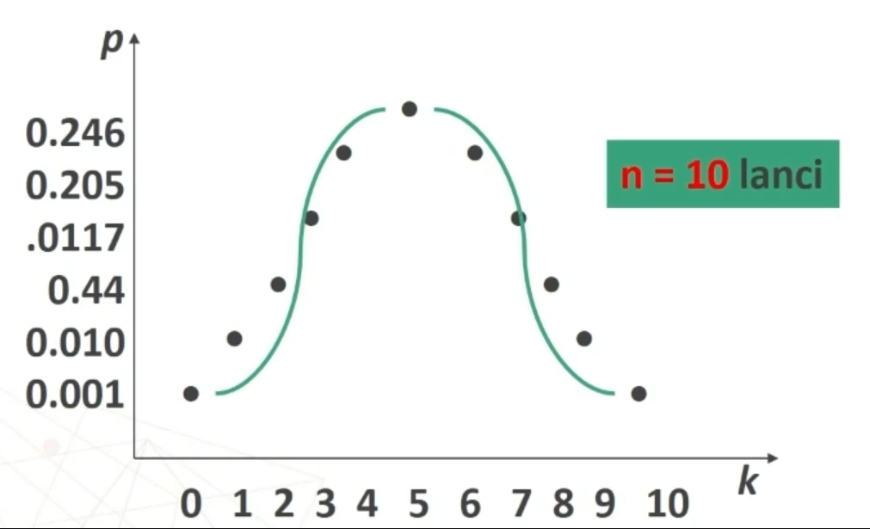
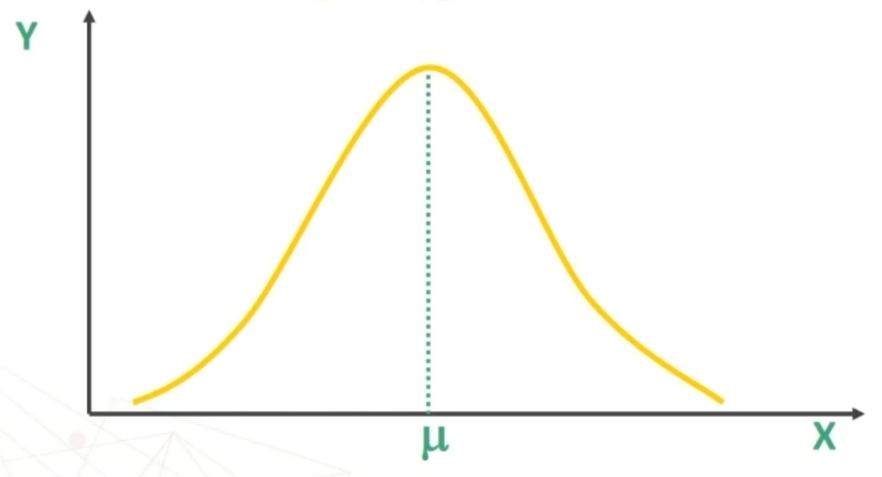
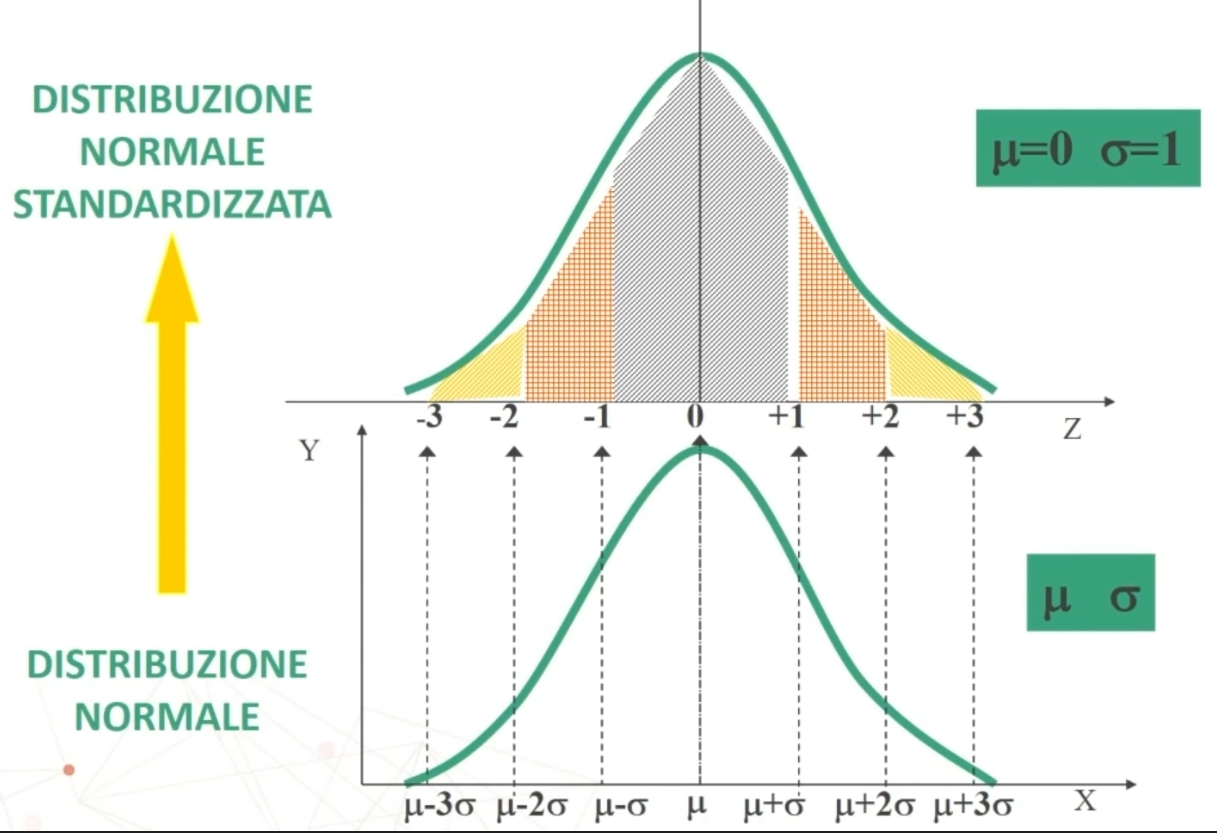
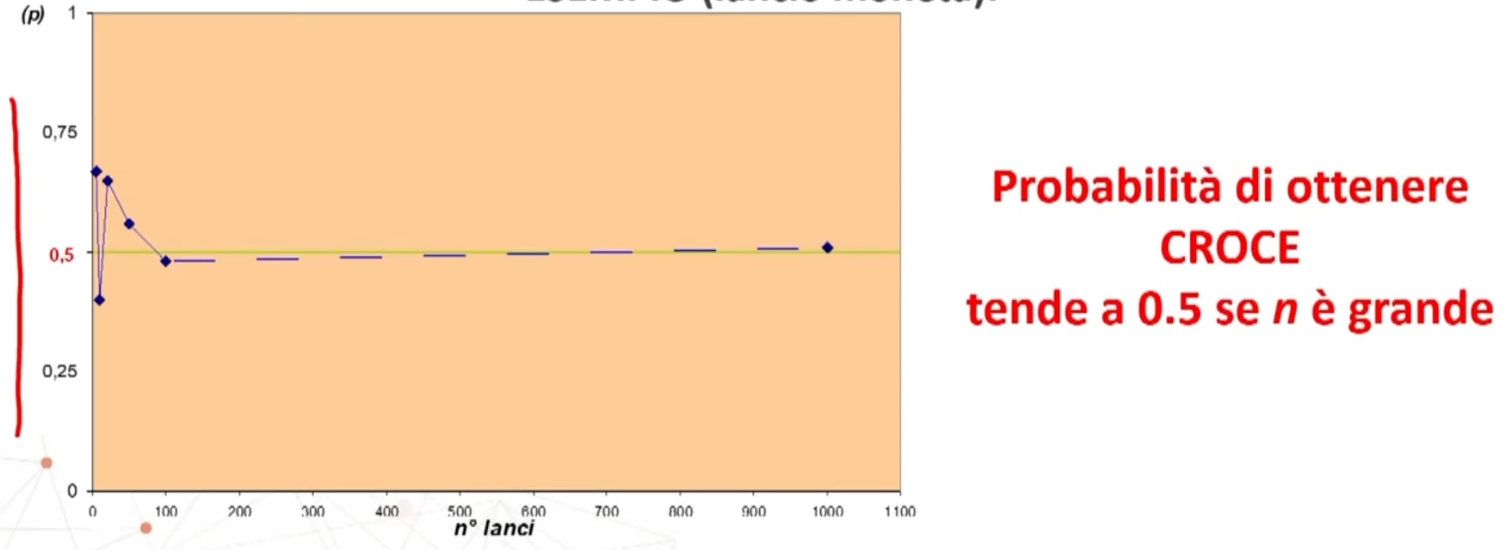
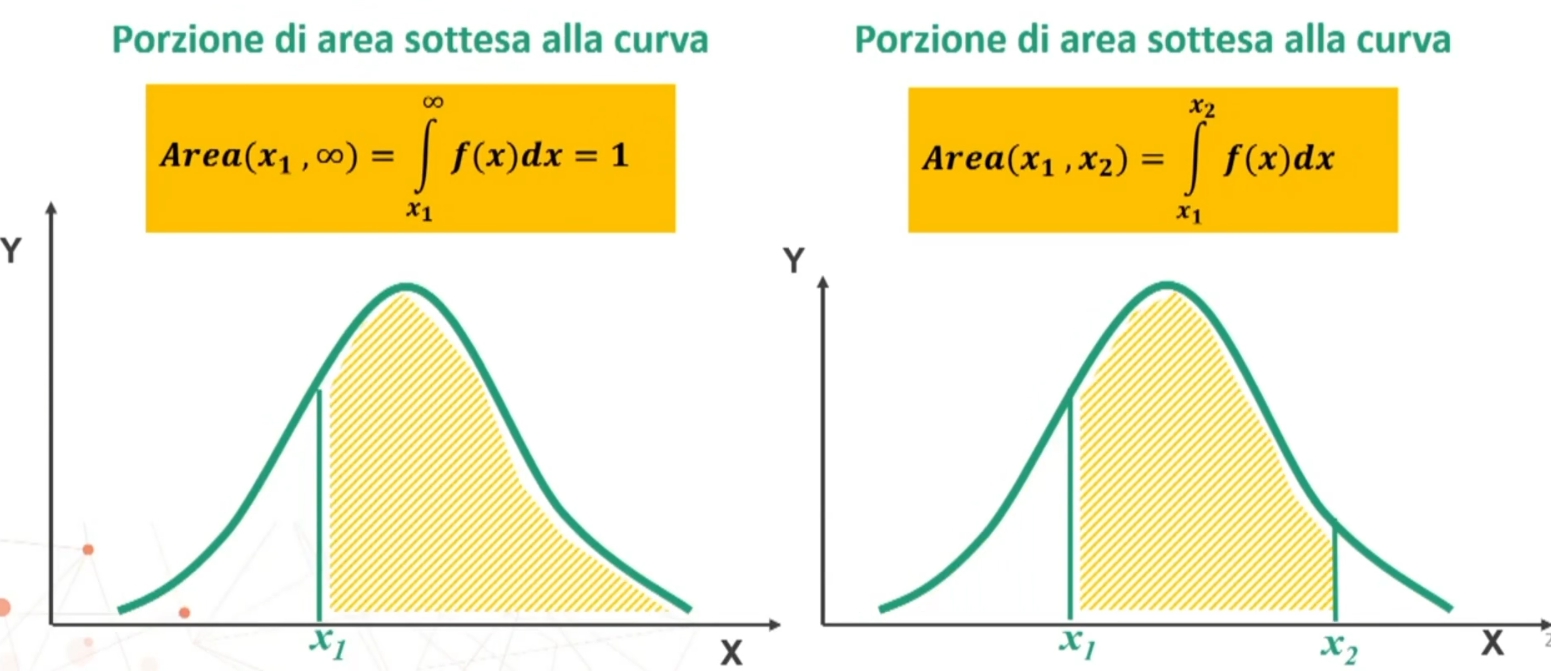
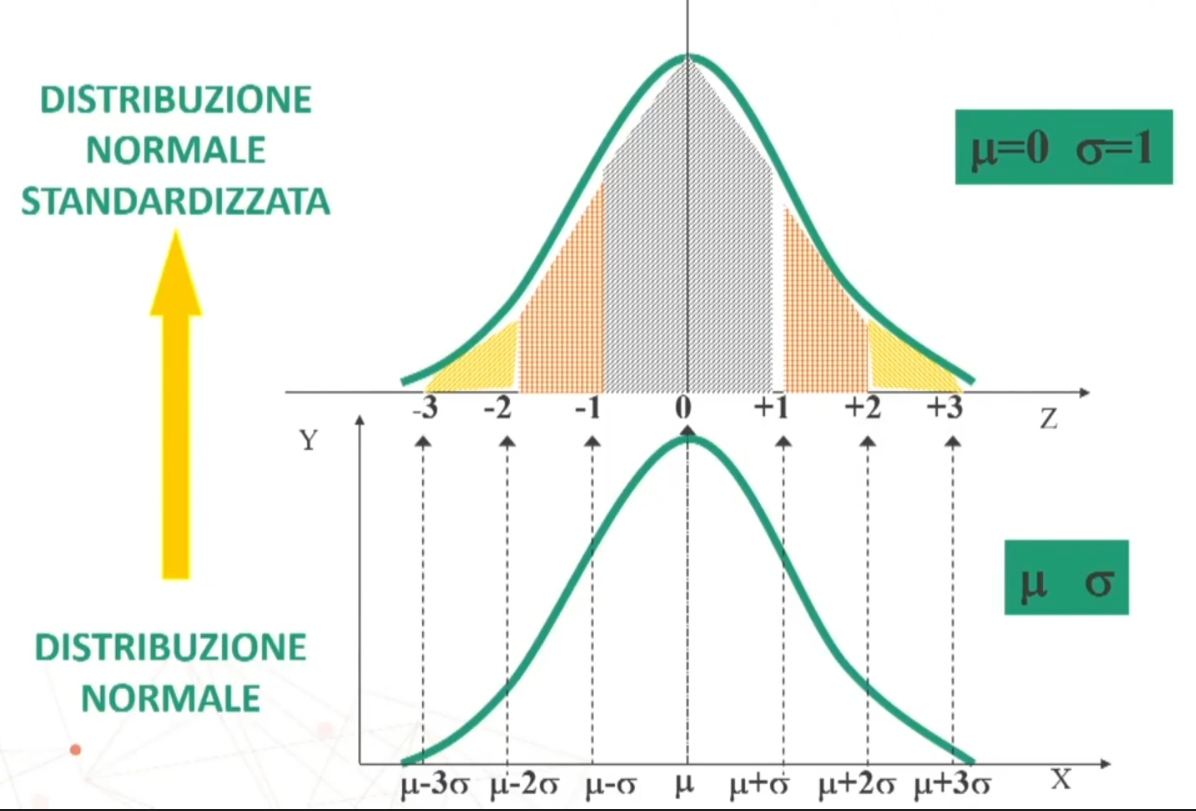
Se n>30 la distribuzione delle medie dei campioni da essa estratti è NORMALE, per qualsiasi distribuzione della variabile. Per fare le nostre inferenze sulla popolazione, partendo dai dati campionari, faremo riferimento alla normale e normale standardizzata, impiegando z. La distribuzione teorica di probabilità della normale definisce la probabilità come pari a 1 sotto la curva.
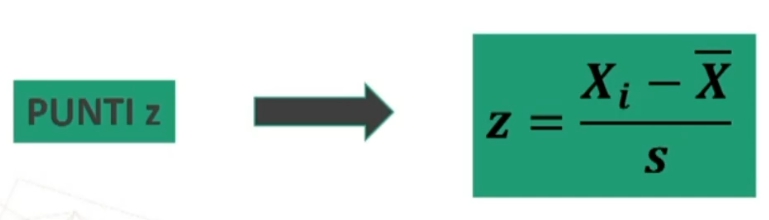
Per esempio poniamo di aver raccolto dei dati su un campione, e di conoscere la media della popolazione infinita o grandissima da cui abbiamo tratto il campione. Se vogliamo sapere se il campione è un rappresentante più o meno probabile o strano della popolazione, possiamo ricorrere alla normale standardizzata. In questo caso, ciò che standardizziamo è la media del nostro campione, per paragonarla alla media della popolazione. L’equivalente della ds (deviazione standard) che serve per la comune standardizzazione è in questo caso il rapporto fra ds della popolazione e radice quadrata di n, vale a dire l’errore standard.
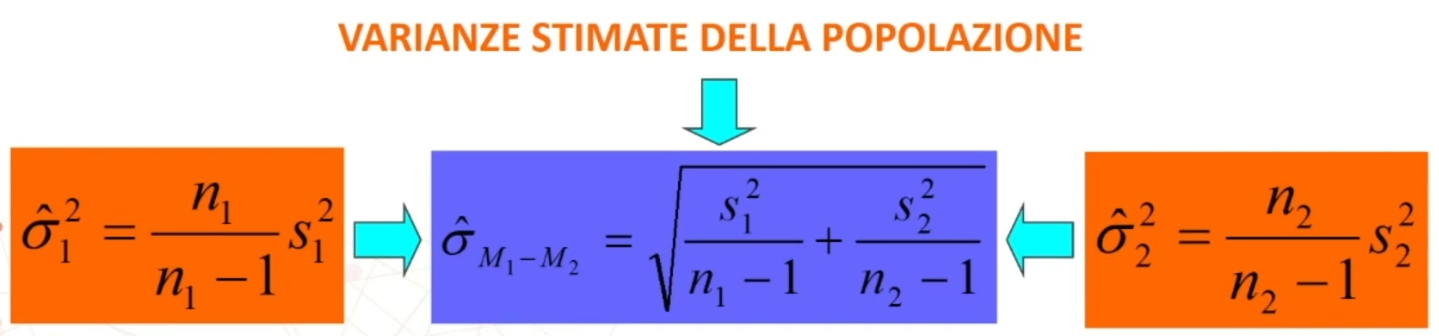
In formule abbiamo
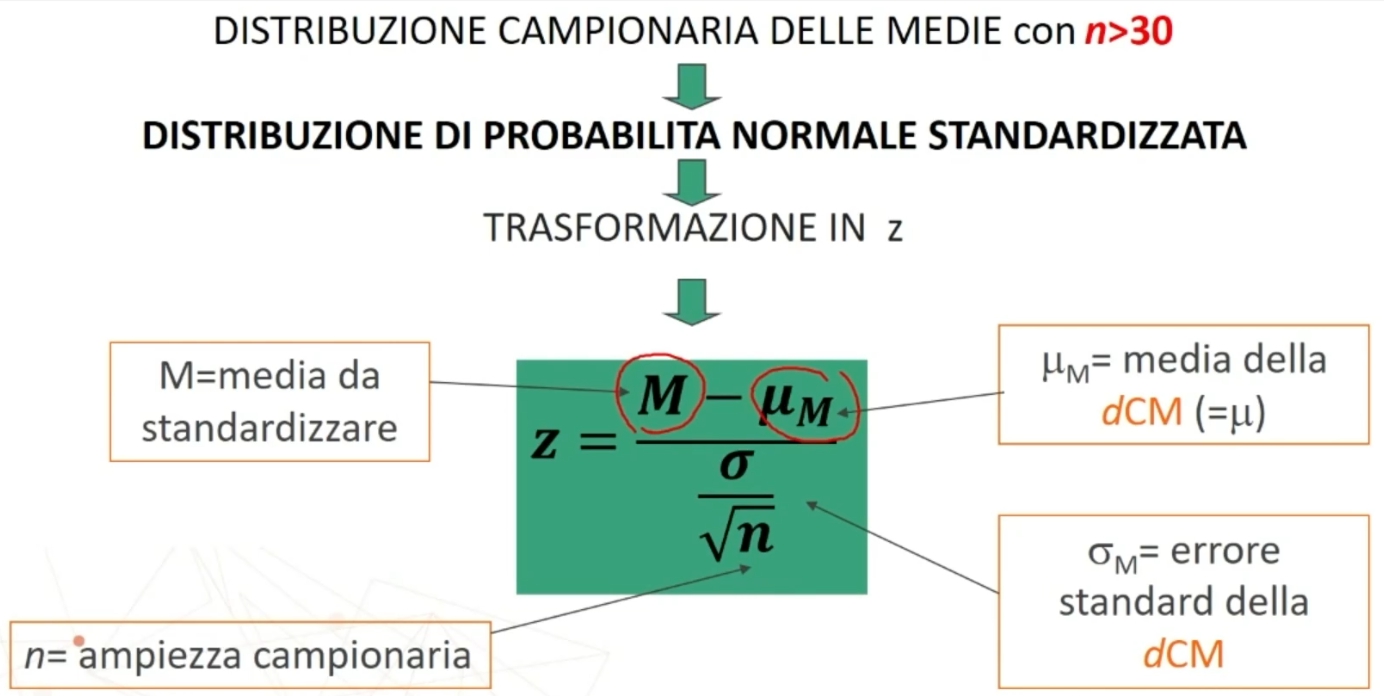
La trasformazione in z, traduce una differenza fra medie dalla metrica originale (es: peso), in una nuova metrica, in cui la nuova unità di misura corrisponde all’errore standard.
Possiamo risalire alla probabilità di osservare una discrepanza dalla media dell’entità espressa da z → Infatti, la z, segue la distribuzione normale di probabilità.
Rispetto alle differenze fra medie nella metrica originale, la z ci aiuta a capire quanto è importante in termini probabilistici la differenza osservata.
- Questo perché l’errore standard è un’unità di misura delle differenze più interessante rispetto alle unità di misura originarie
- L’errore standard rappresenta l’errore medio della stima che effettuiamo calcolando la media campionaria.
- Una differenza grande svariate volte l’errore medio della stima, è un evento poco probabile, e tutto ciò che è poco probabile è in genere molto informativo.
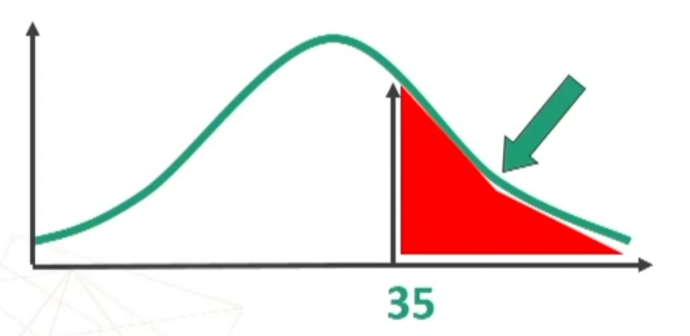
Esempio uso di Z
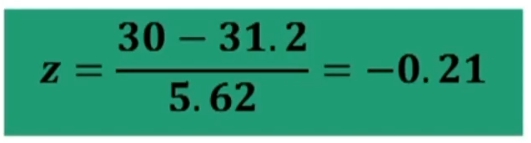
Poniamo di aver ottenuto su un campione di nostri pazienti (n = 19) un punteggio pari a 24.5 in un test di depressione.
Nel campione normativo il test ha una media di 24.1 con ds = 1.7.
Il mio campione è “strano” rispetto a quello normativo?
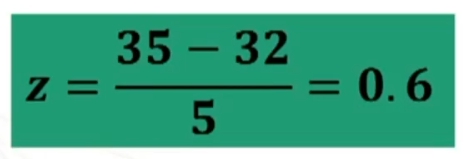
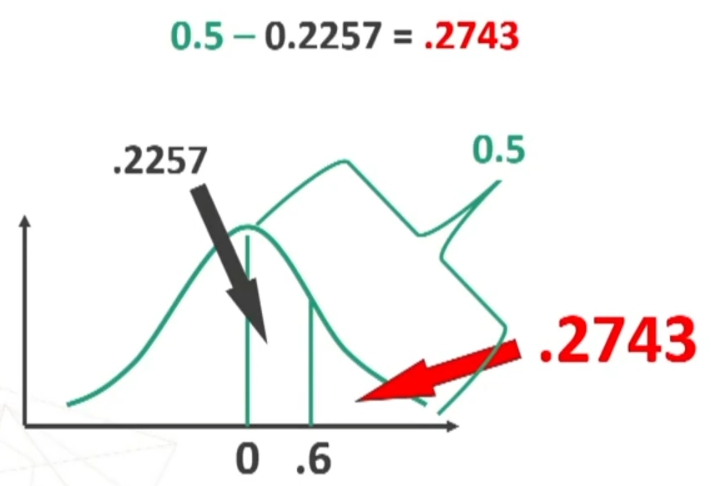
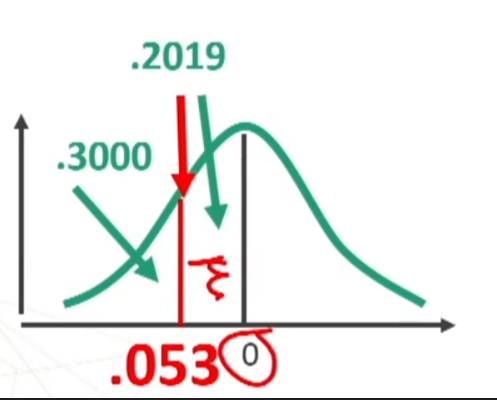
Traformiamo in z la nostra media
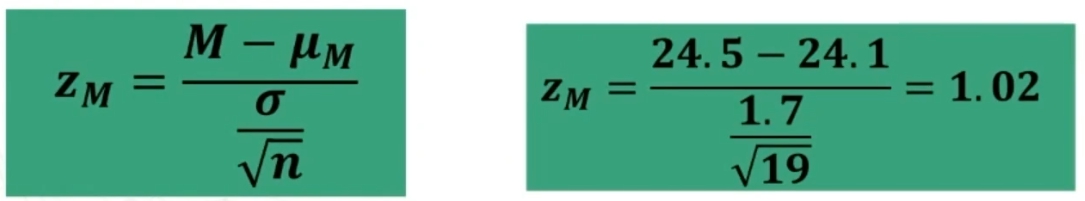
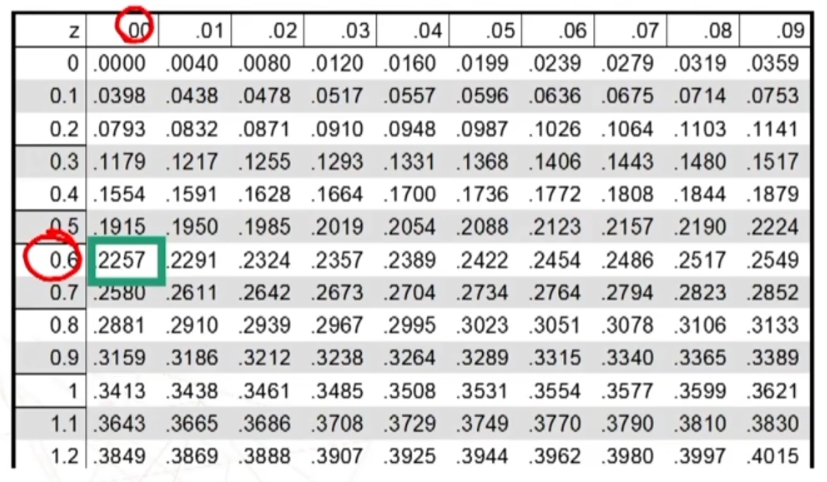
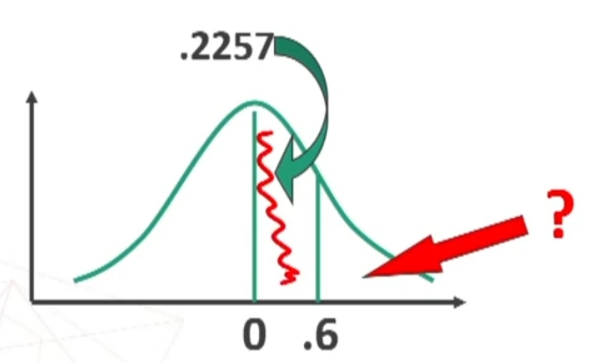
Andiamo i vedere i valori tabulati
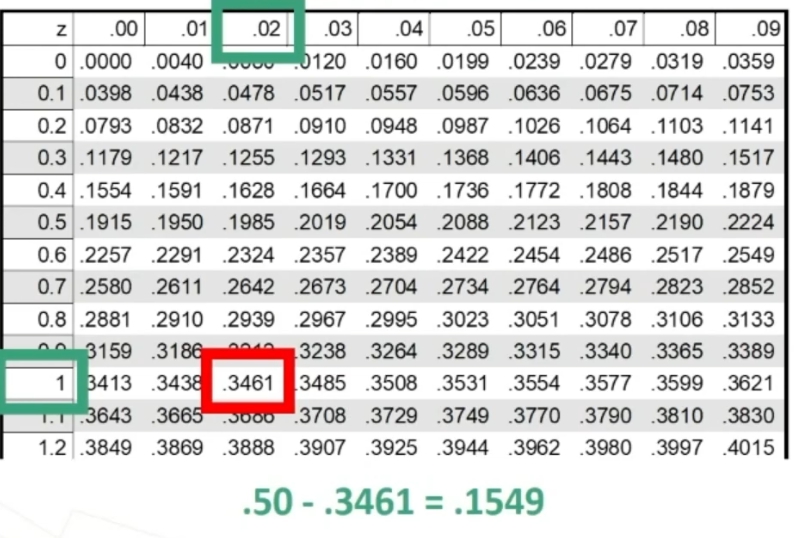
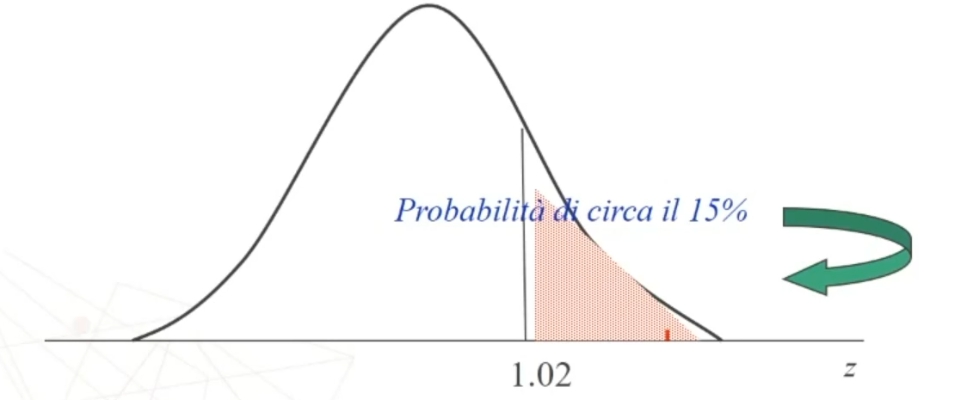
.50 – .3461 perchè dobbiamo togliere metà della curva. Il valore .1549 rappresenta una probabilità.
Ne posso concludere che il mio campione rappresenta un caso relativamente banale e abbastanza rappresentativo della popolazione fotografata dal campione normativo. Detto in modo più tecnico, i dati possono confermare che il mio campione proviene probabilmente dalla medesima popolazione da cui è stato tratto il campione normativo.
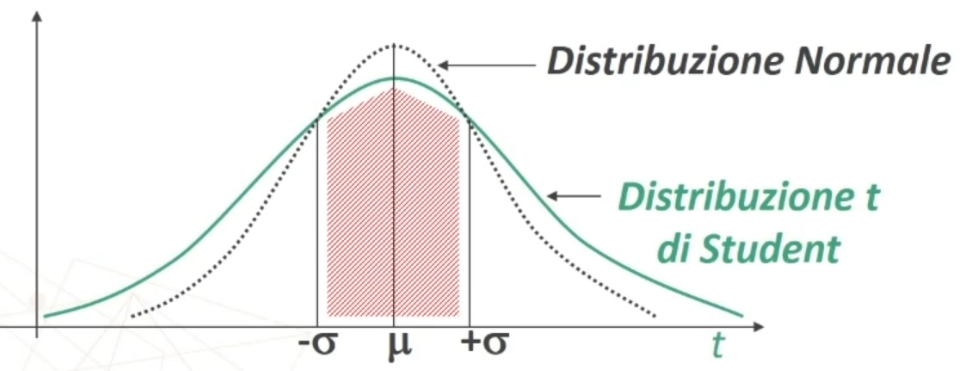
Distribuzione t di Student
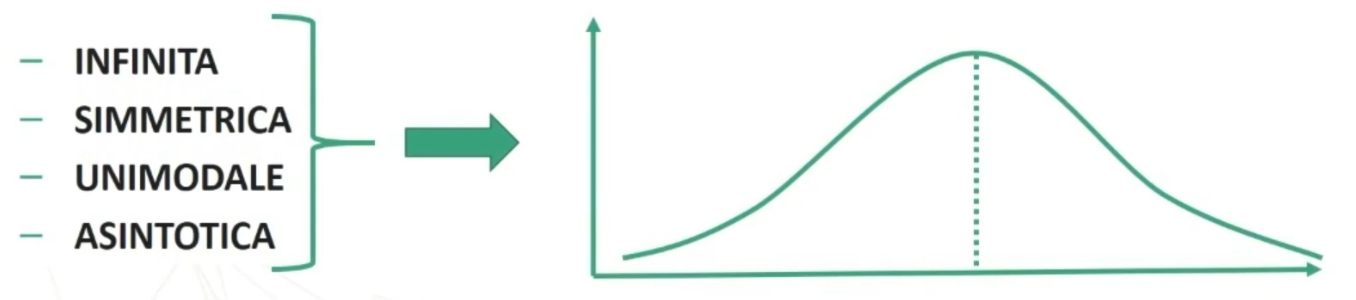
La distribuzione t di Student ha delle caratteristiche simili alla normale. Se n<30 la distribuzione delle medie dei campioni è del tipo t di Student. Ha le seguenti caratteristiche (simili alla normale):
- ASINTOTICA
- INFINITA
- SIMMETRICA
- UNIMODALE
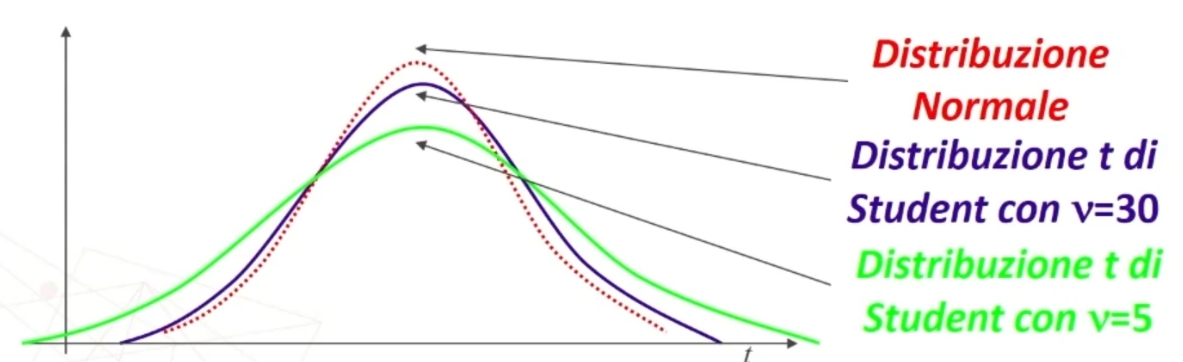
La forma della distribuzione t varia secondo la dimensione n dei campioni.
Ciascuna distribuzione t è definita dai parametri μ, σ e v = gradi di libertà
La t è quindi una Famiglia di distribuzioni legate al numero v = gradi di libertà (all’aumentare di v la distribuzione tende alla normale).
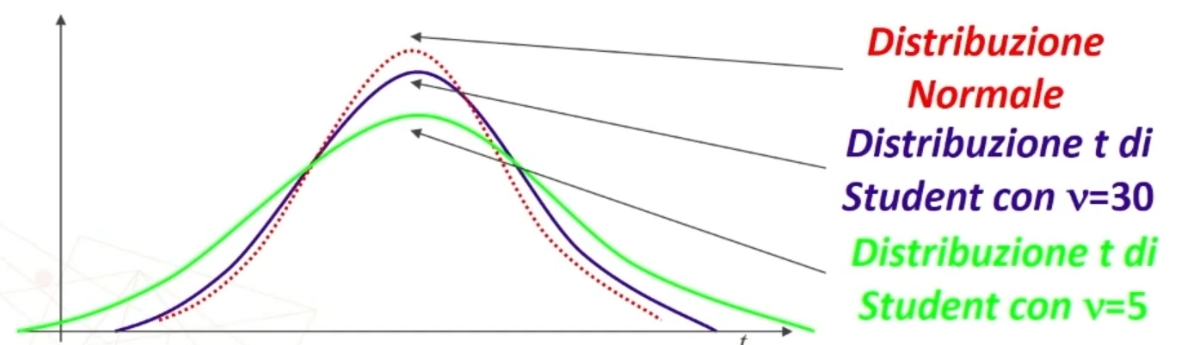
Come la Z, anche la t definisce la probabilità pari a 1 sotto la curva.
La t è una funzione delle medie del campione, della popolazione (media delle medie) e dell’errore standard in cui compaiono i gradi di libertà.
La t è la z sono analoghe: entrambe sono trasformazioni dei punteggi grezzi, o delle medie, in un nuovo tipo di punteggio basato sullo scostamento fra medie (o punteggi).
Come per la normale
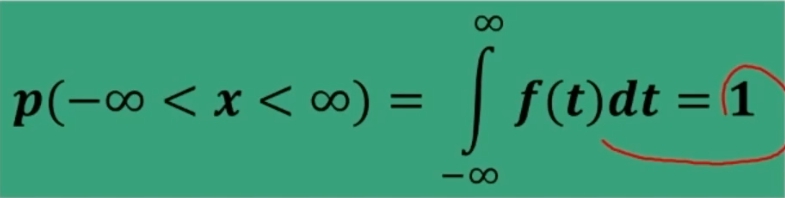
La curva definisce una distribuzione di probabilità ⇒ Distribuzione di probabilità t definita dall’indicatore:

Abbiamo quindi
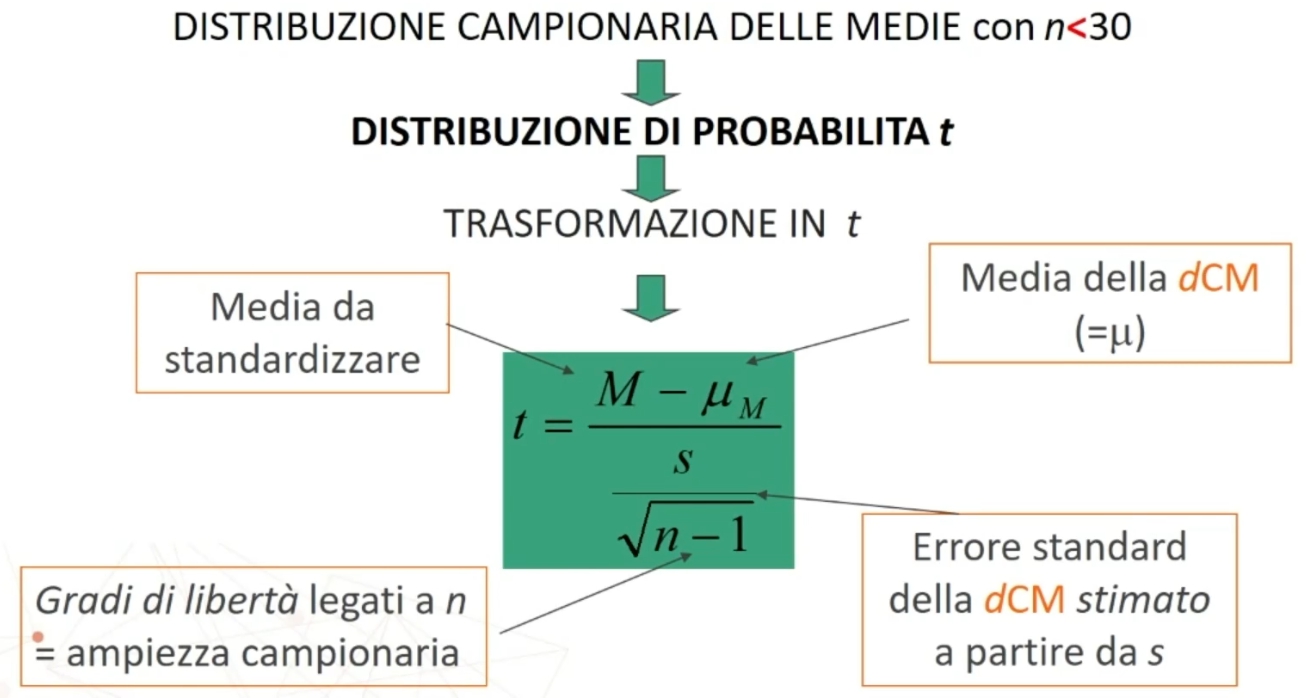
A che serve quindi la t?
Come la trasformazione in z, la trasformazione in t scala le differenze osservate secondo una nuova unità di misura data dall’errore standard. Questa nuova scala segue una distribuzione nota.
Quindi possiamo sapere quanto è probabile osservare una data differenza. Se una differenza supera di svariate volte l’errore standard di misura ci troviamo di fronte ad una differenza improbabile, e quindi interessante e informativa.
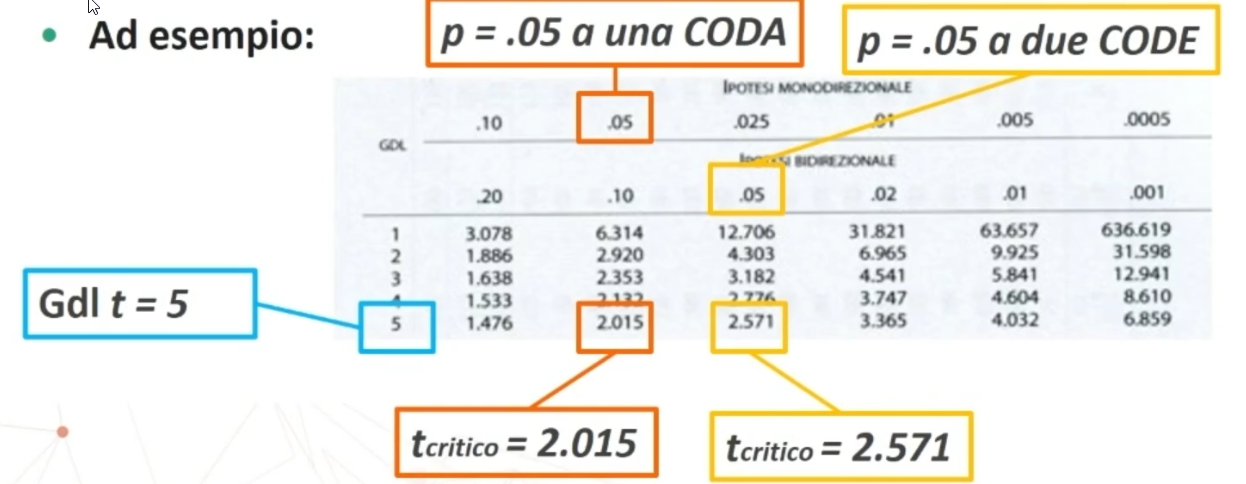
ESEMPIO dell’uso di t
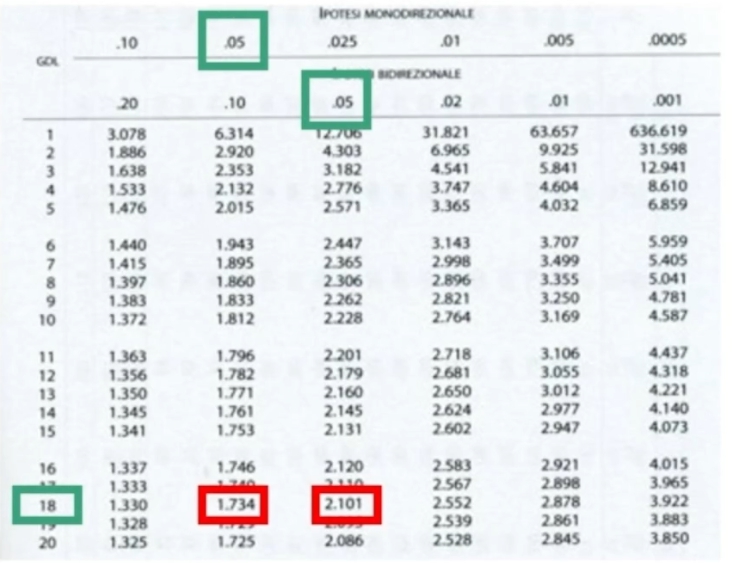
Poniamo di aver ottenuto su un campione di nostri pazienti (n = 19) un punteggio medio pari a 25.3 (d.s. = 1.7) in un test di depressione. Le tabelle del campione normativo suggeriscono che punteggi superiori a 25 sono da considerarsi problematici.
Quanto è problematico il mio campione? Calcoliamo t
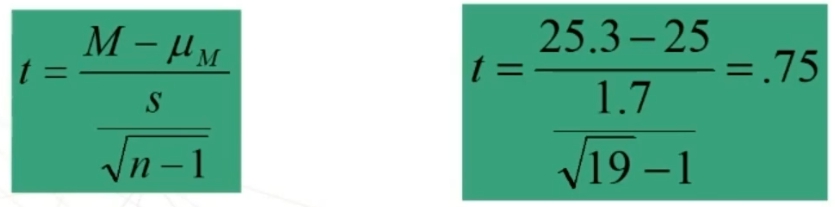
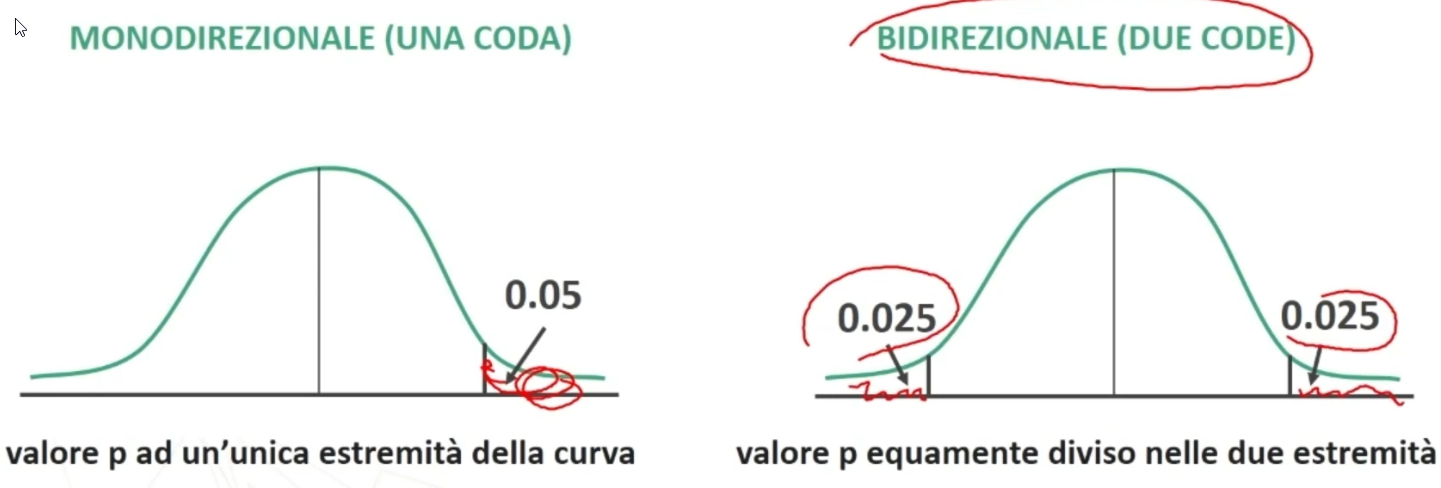
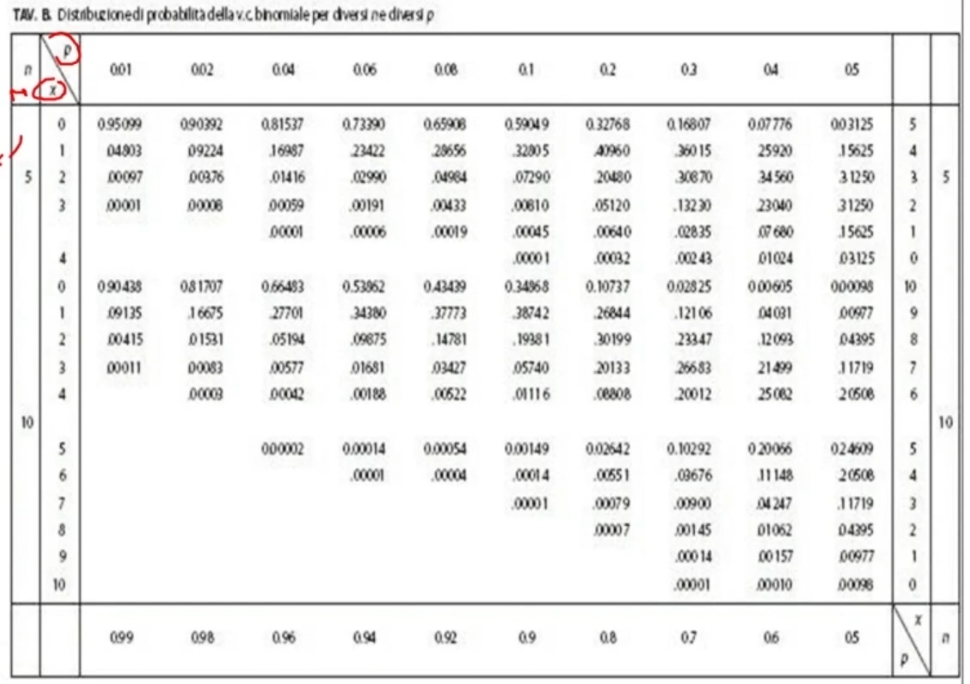
Il punteggio t da noi ottenuto (0.75) è inferiore ai punteggi tcritico fissati ad un livello di probabilità pari allo 0.05 relativi ad un’ipotesi monodirezionale e bidirezionale (valori segnati in rosso nell’immagine).
- 0.75 < 1.734
- 0.75 < 2.101
Dunque, il nostro campione non è così problematico. In altre parole, abbiamo un’alta probabilità (95%) che il valore della nostro campione corrisponda a quello del campione normativo.
Intervallo di fiducia
Nella stima dei parametri ci interessa scoprire in quale intervallo cadrà la media della popolazione dalla quale abbiamo estratto un campione. Tale intervallo, detto di fiducia, valuta la probabilità (“fiducia”) che il parametro della popolazione ha di cadere in una determinata “forchetta” di valori.
Consideriamo un campione di anziani affetti da tre anni da demenza progressiva e osservando una X̄ = 68 al QI, quale sarà la media μ della popolazione dei pazienti sofferenti da tre anni di demenza?
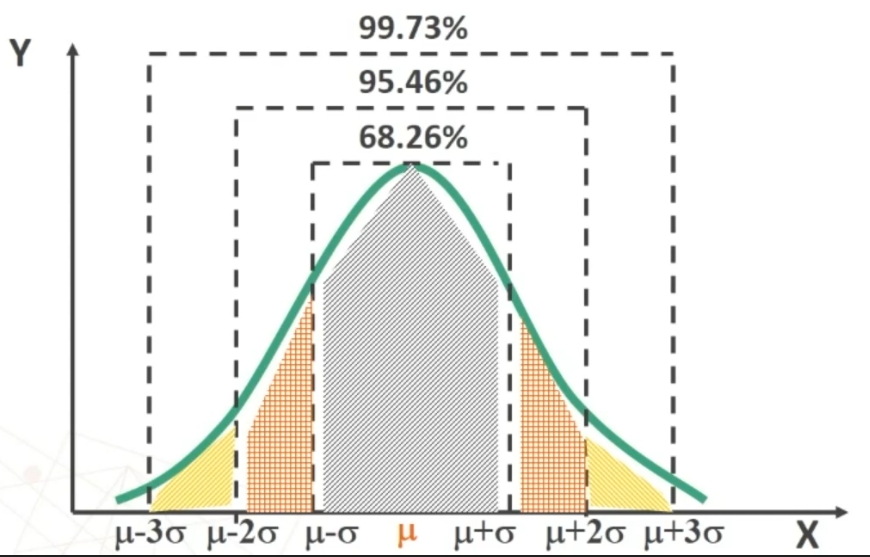
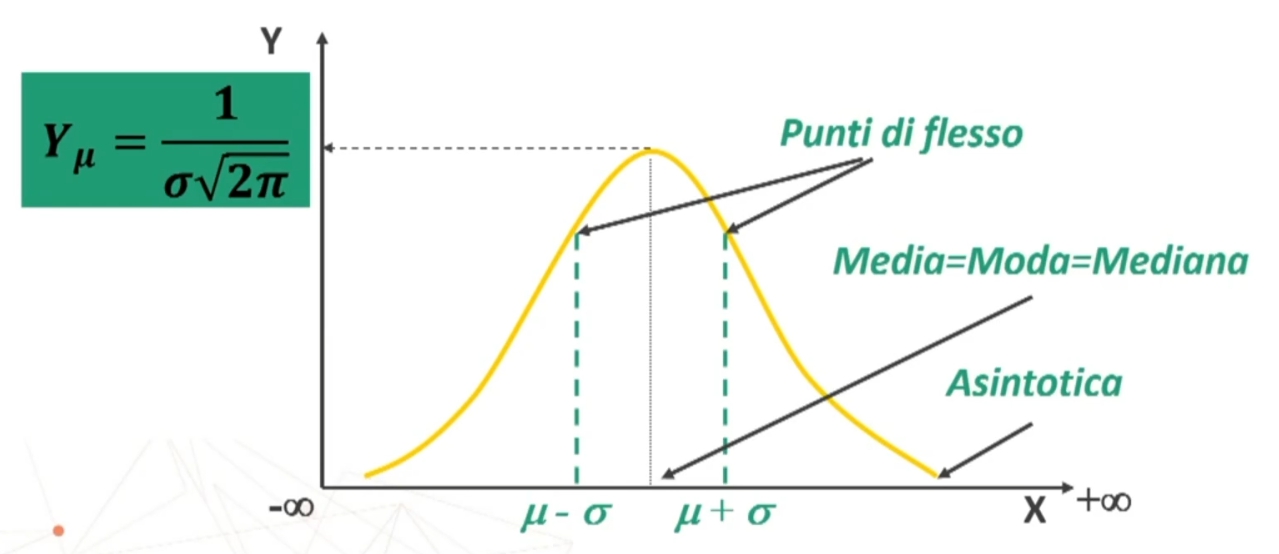
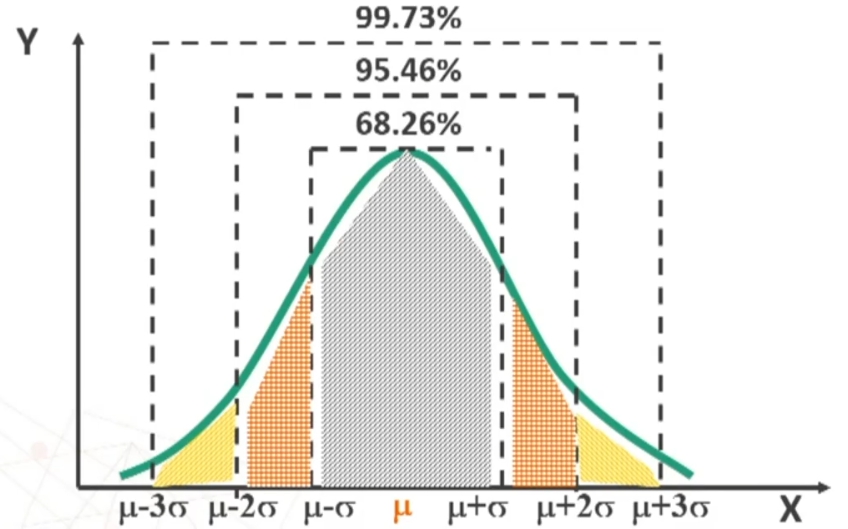
Sappiamo che possiamo fare riferimento alla normale, quindi sfruttando la prorietà della normale possiamo ricavare facilmente alcune sotto la distanza delle ascisse
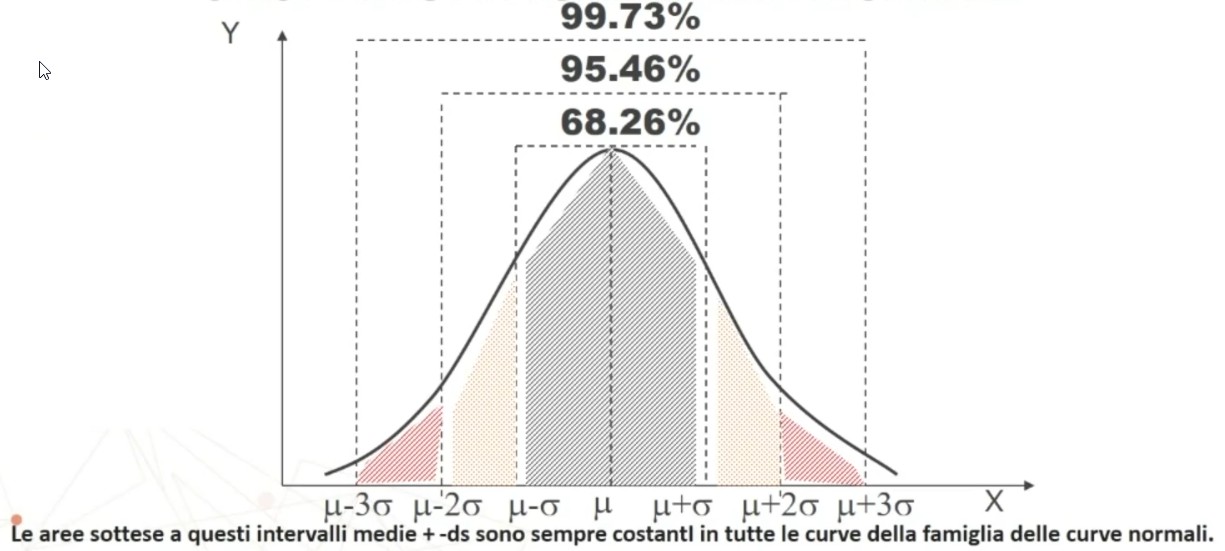
Posso affermare che in un campione casuale di n > 30 soggetti si avrà una probabilità di ottenere X̄ compreso nell’intervallo pari al:
- 68,26% per μ ± σ
- 95,47% per μ ± 2σ
- 99,73% per μ ± 3σ
Oppure posso affermare che avendo estratto un campione casuale di n > 30 soggetti con media X̄, la probabilità che la media della popolazione μ sia compresa nell’intervallo sarà pari al:
- 68,26% per μ ± σ
- 95,47% per μ ± 2σ
- 99,73% per μ ± 3σ
Esempio
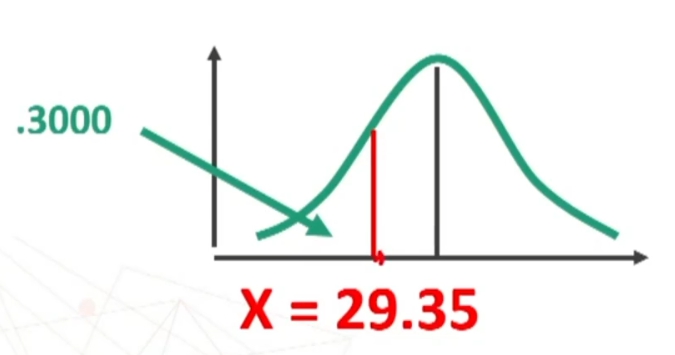
Esempio: Dato un campione di numerosità n = 50 con X̄ = 19 e S = 1.8 (deviazione standard), qual è la media della popolazione da cui il campione è stato estratto?
Primo passo: Stabiliamo il rischio che accettiamo di correre nel dichiarare che il parametro μ ricada nell’intervallo di valori da noi stimato.
Di solito si accetta un rischio del 5% (probabilità pari a 0.05) o, per essere più sicuri dell’1% (probabilità pari a 0.01).
Scegliamo il primo caso (5%), avendo dunque una fiducia al 95% (probabilità 0.95) che l’intervallo contenga μ.
Sappiamo che la distribuzione campionaria della media si avvicina alla forma normale, ed abbiamo a disposizione una distribuzione già tabulata e cioè la distribuzione normale standardizzata (che ha μ = 0 e σ² = 1).
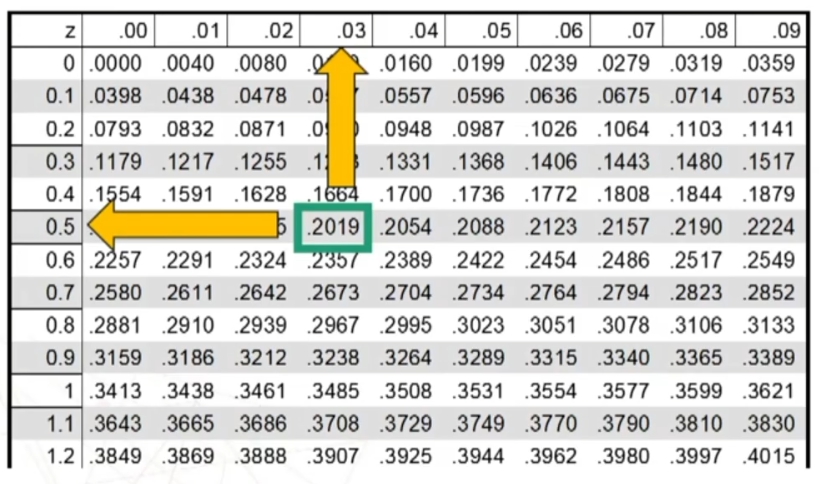
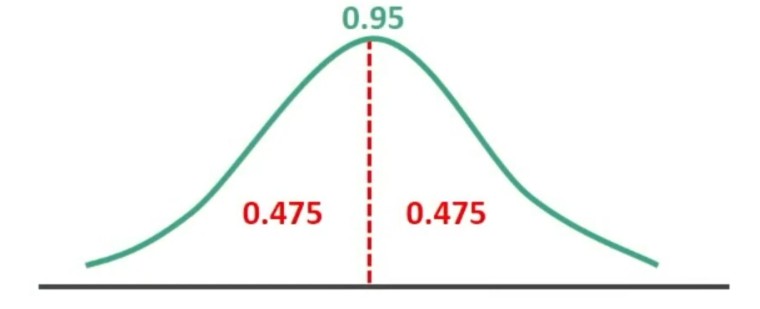
Utilizzando la tavola, possiamo andare a trovare i punti z che corrispondono ad una probabilità pari ad un’area di 0.95.
La tavola fornisce per ogni z l’area compresa tra 0 e z>0.
Ma sappiamo che la distribuzione normale standardizzata è simmetrica, quindi dobbiamo dividere l’area in due parti uguali: 0.95/2 = 0.475.
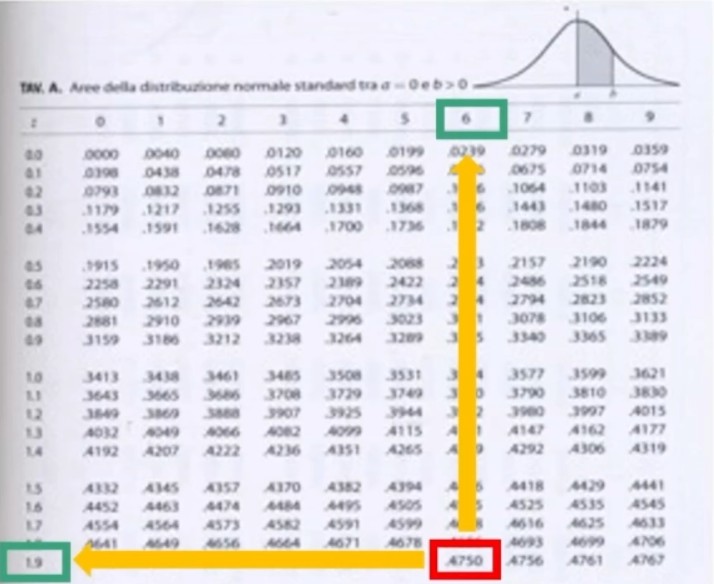
Nella tavola andiamo ad individuare z corrispondente all’area 0.475.
Individuiamo sulla tavola l’area pari a .4750. Andiamo poi ad individuare il valore z corrispondente. Dall’incrocio del valore in riga (primo decimale = 1.9) e il valore in colonna (secondo decimale = .06) otteniamo una z pari a 1.96
Dato il campione di numerosità n = 50 con X̄ = 19 e S = 1.8 andiamo a calcolare l’intervallo di fiducia al 95% per la media della popolazione. Faremo riferimento alla distribuzione normale standardizzata e all’area 95%.

Sostituendo a z₉₅% il valore corrispondente e stimando la deviazione standard col campione (stima non distorta) si ottiene:
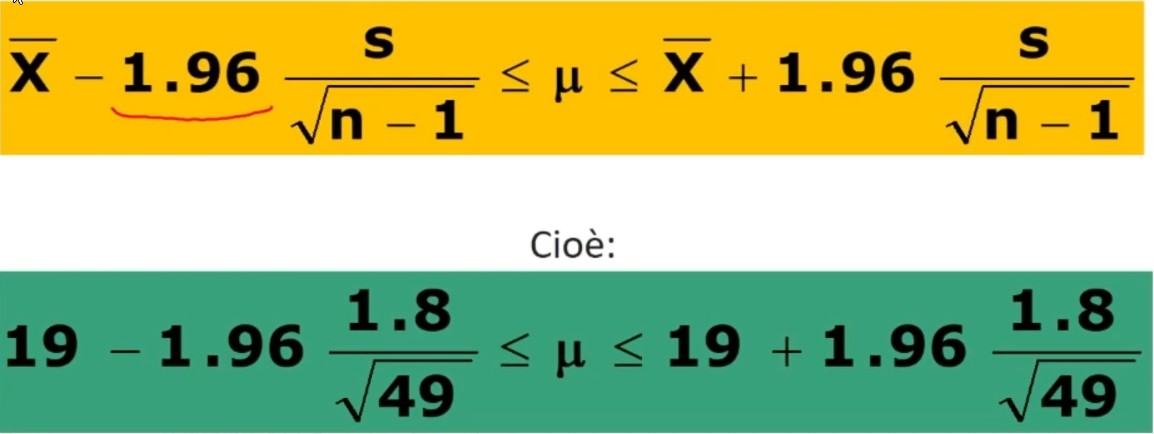
Possiamo concludere che la media della popolazione sarà compresa tra:
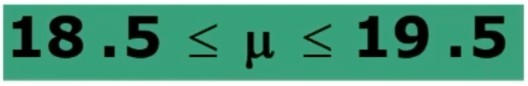
con una probabilità del 95%.