Table of Contents
Distribuzione normale
La curva normale o curva di Gauss è una distribuzione teorica di punteggi in una popolazione.
Teorema del limite centrale: gauss ci dice che la somma di n variabili casuali con media e varianza finite tende a una distribuzione normale al tendere di n all’infinito
Riguarda solo le variabili metriche continue, quindi le misure almeno su scale a intervalli equivalenti.
L’importanza di questa distribuzione è dovuta al fatto che molti dei fenomeni osservati si distribuiscono normalmente o con forme che si approssimano alla curva normale Inoltre, gran parte della statistica inferenziale si basa sulle proprietà di questa distribuzione.
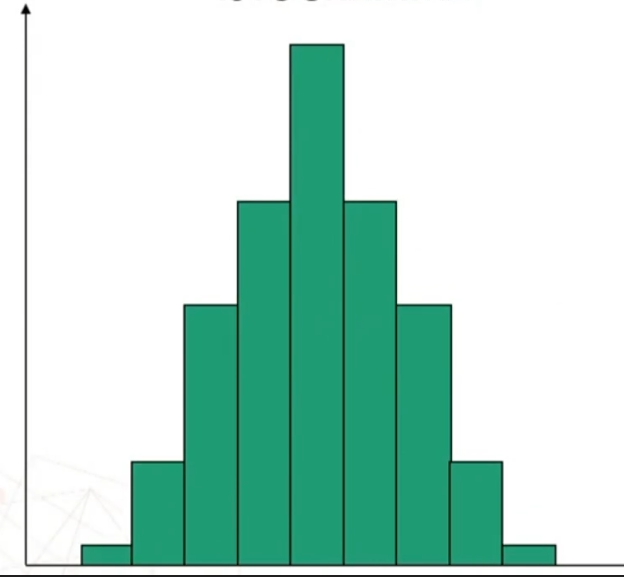
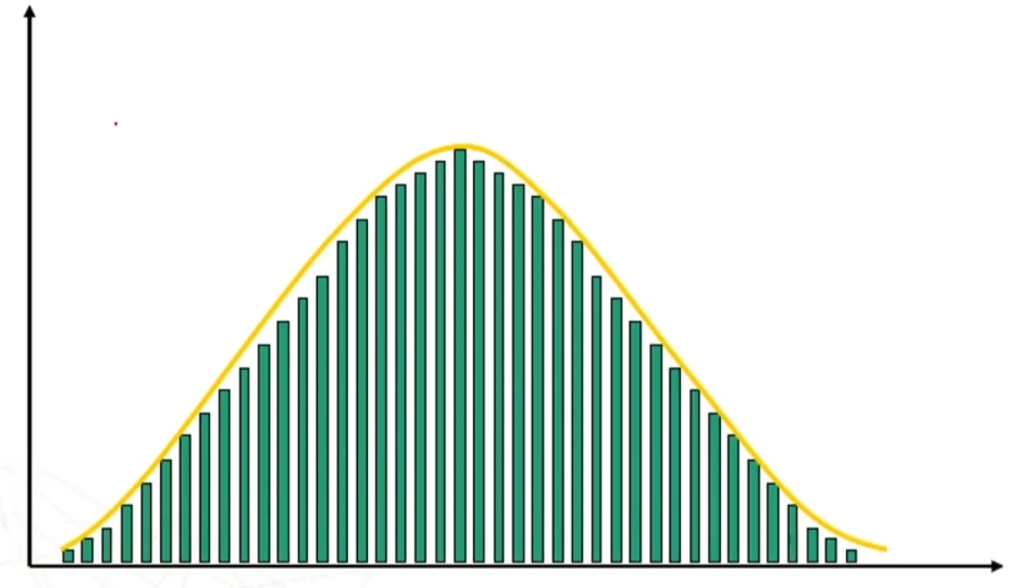
Partendo da una distribuzione di frequenza, riducendo l’ampiezza degli intervalli, otteniamo la distribuzione normale (curva continua a forma di campana – gaussiana).
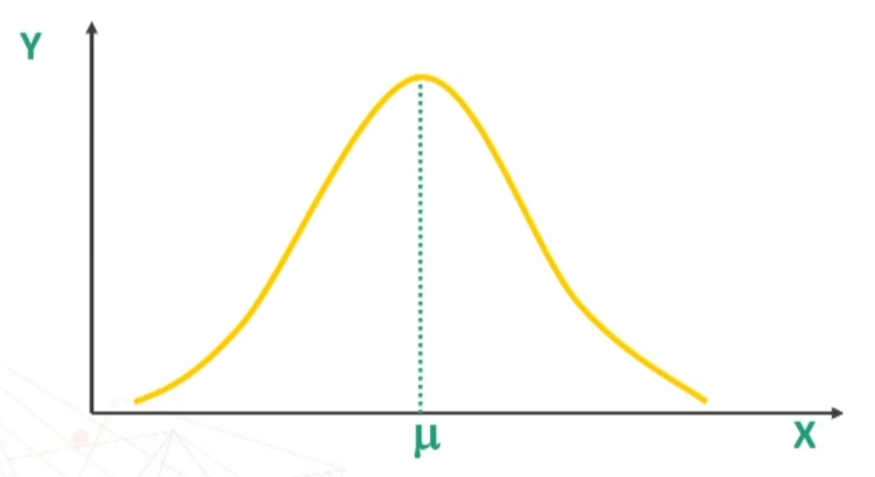
Al centro della curva abbiamo il valore centrale di X. Tale curva è definita dalla seguente equazione.

Caratteristiche e proprietà
Vediamo alcune proprietà di questa curva
- INFINITA: x va da -∞ a +∞
- SIMMETRICA rispetto alla Y massima f(x): punto più alto x = μ
- UNIMODALE: (μ = Mo = Me) (media = moda = mediana)
- ASINTOTICA: si avvicina all’asse delle X senza mai toccarlo, se non ai valori di ascissa -∞ e +∞ che non sono rappresentabili
- DUE PUNTI DI FLESSO: da concava diventa convessa nella metà sinistra e da convessa diventa concava nella metà destra (in corrispondenza di valori di x uguali alla media meno o più una deviazione standard)
- CRESCENTE per -∞ < x < μ e DECRESCENTE per μ < x < +∞ due punti di flesso a ± σ da μ
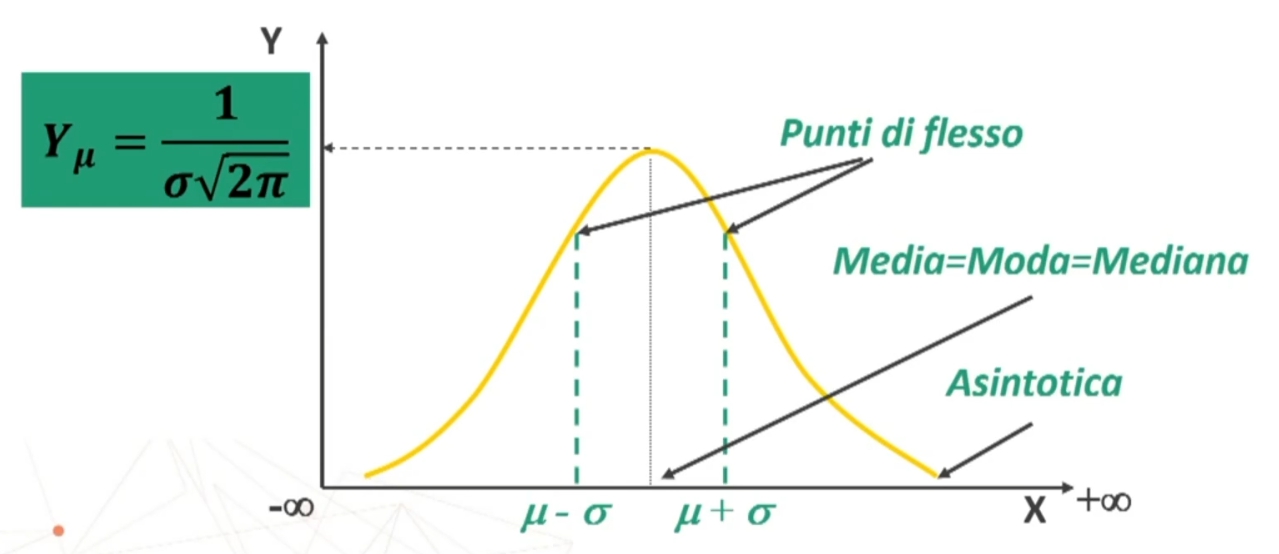
- La curva NORMALE è interamente definita dai parametri μ (la media) e σ (deviazione standard).
- Poiché la distribuzione normale varia al variare di μ e σ si può parlare di famiglia di distribuzioni normali con medie e deviazioni standard diverse. Esempio di seguito famiglia distribuzioni normali con stessa media e deviazione standard diversa, e poi con media e deviazione standard diverse, e infine con media diversa e con deviazione standard uguale
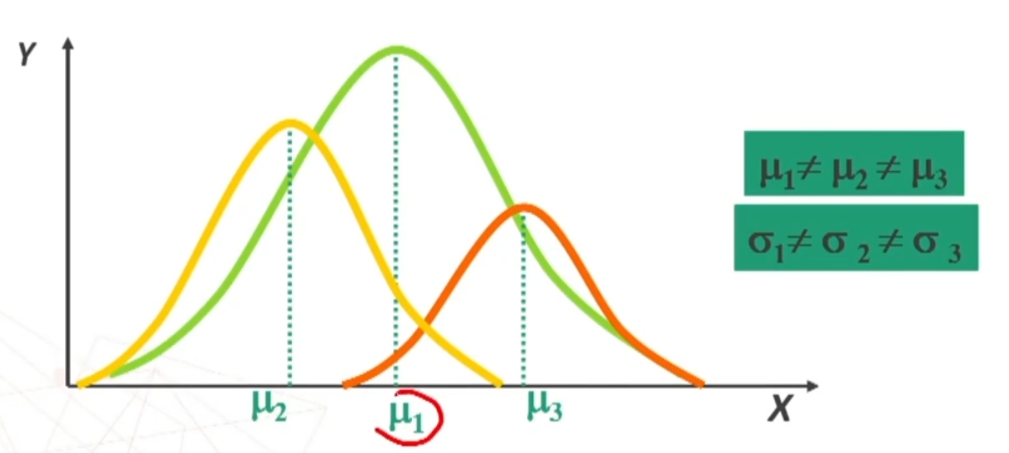
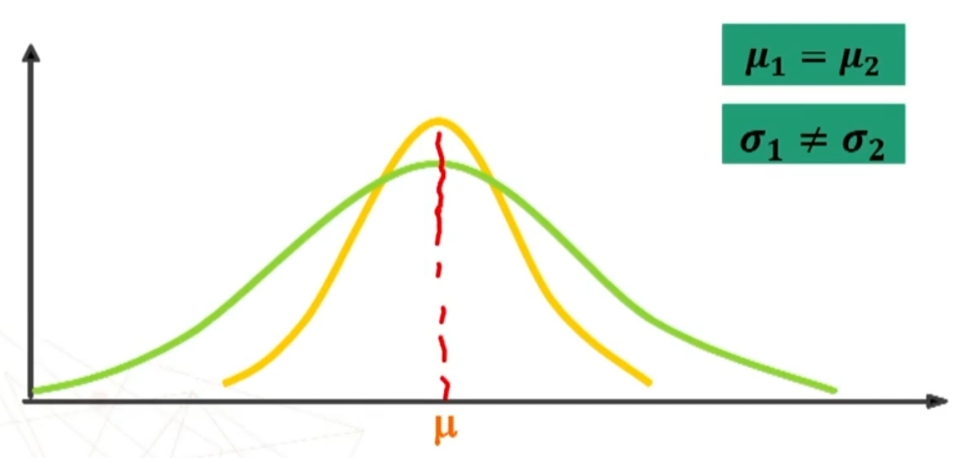
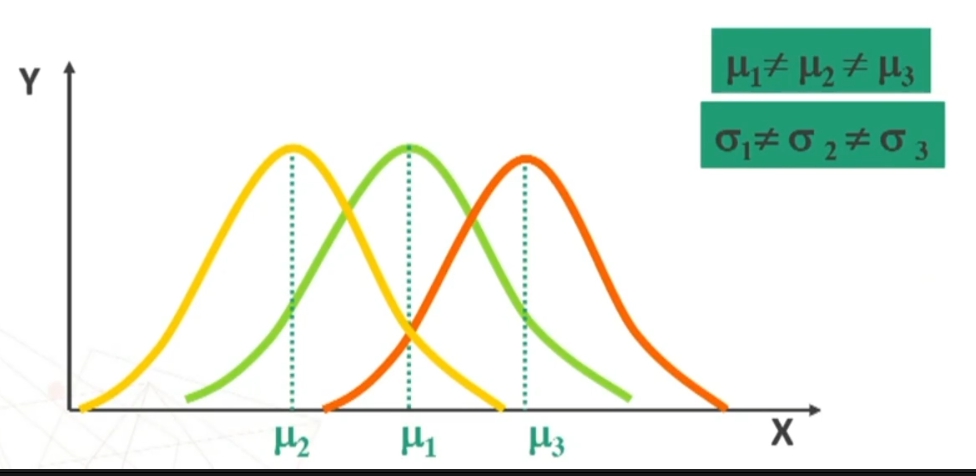
- Qualsiasi siano i parametri μ e σ, l’AREA sottesa dall’intera curva è = 1. Infatti “1” è un simbolo che rappresenta il fatto che sotto la curva si trova il 100% degli individui (frequenze) rappresentati dalla variabile.
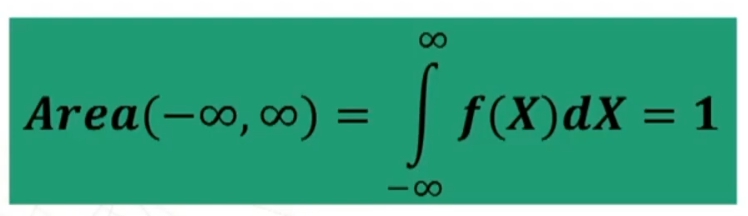
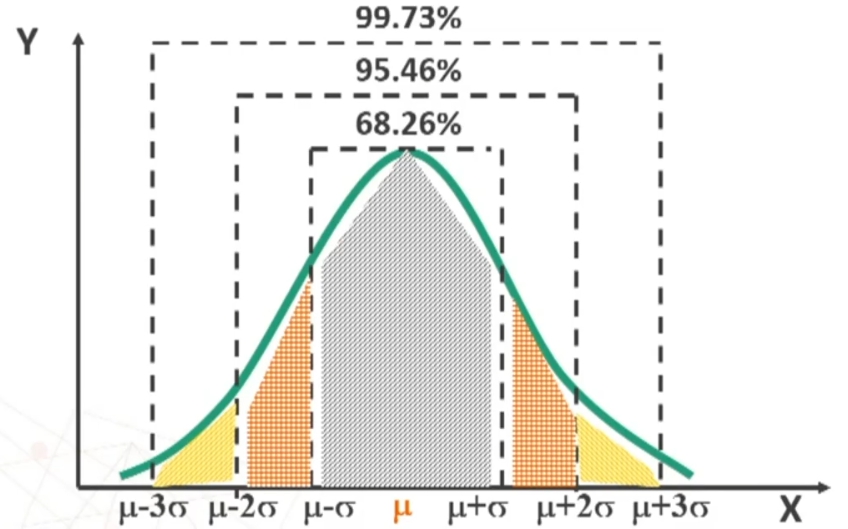
- La porzione di curva delimitata dalla media e un’ordinata espressa in termini di deviazioni standard è costante:
- μ + σ = 34.13% della distribuzione
- μ + 2σ = 47.73% della distribuzione
- μ + 3σ = 49.86% della distribuzione
- Conoscendo μ e σ, possiamo stimare f(x) e l’area compresa tra due qualsiasi valori di x
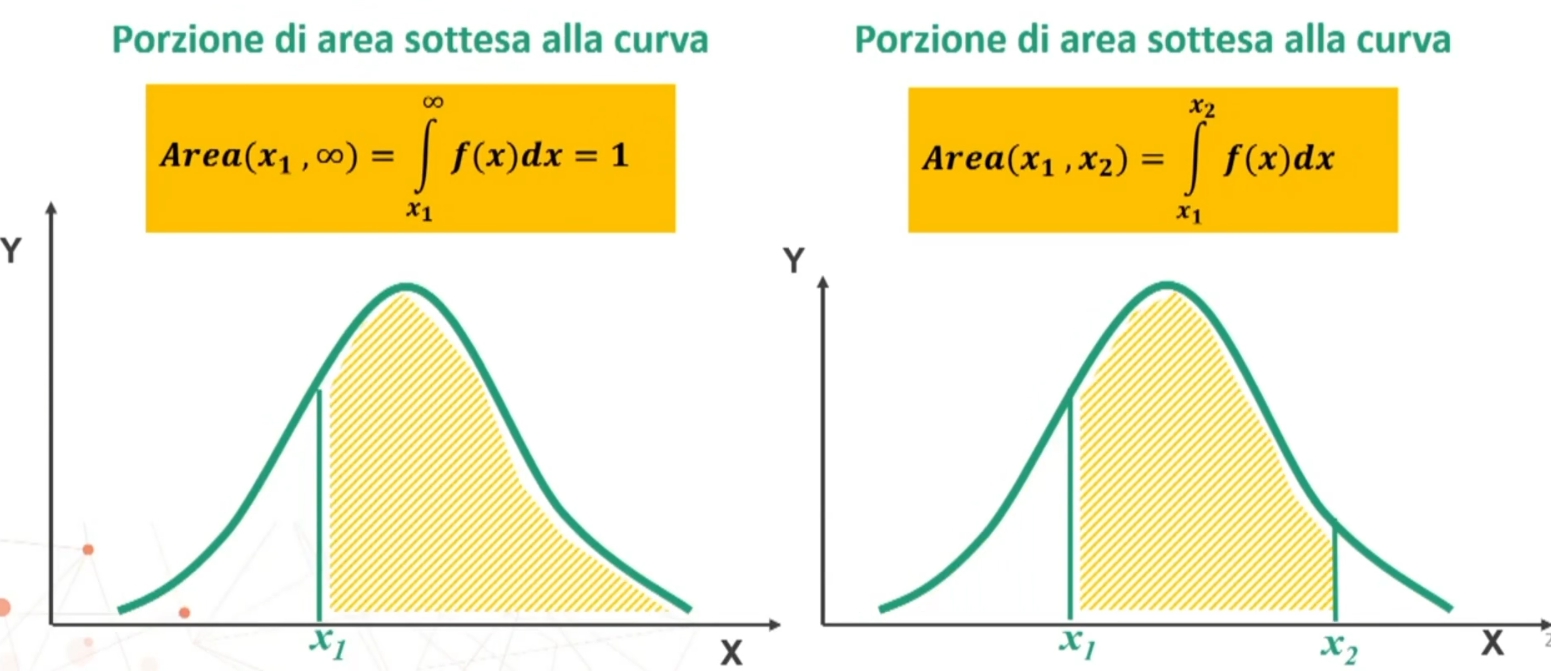
Poiché la curva è simmetrica, l’area compresa tra -∞ e μ è uguale a .50 come quella compresa tra μ e +∞. In altre parole, sopra la media ci sono il 50% dei casi, come sotto la media
Qualunque siano i valori di μ e σ, l’area corrispondente a intervalli definiti è sempre la stessa → Porzioni della distribuzione compresse tra ± 1, 2, 3 σ da μ (in %)
Distribuzione normale standardizzata
Per gli usi pratici della distribuzione normale si ricorre alla CURVA NORMALE STANDARDIZZATA. L’equazione della curva dipende da un solo parametro, zeta; pertanto:
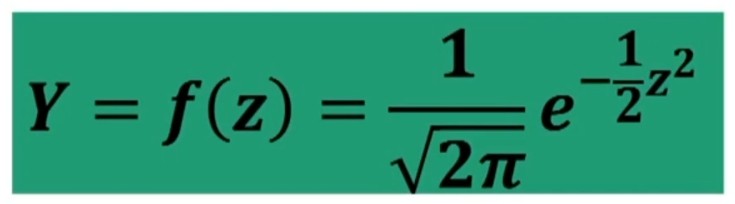
I parametri di z sono noti → μ = 0; σ = 1. Di conseguenza anche i valori nella distribuzione, che pertanto possono essere tabulati (essere anch’essi noti).
In un’unica tavola sono riportate le aree della curva in corrispondenza dei diversi valori di z. La tavola prende in considerazione la metà destra della curva, quindi le aree comprese tra la media (z=0) e qualunque valore positivo di z > 0
Poiché la curva normale standardizzata è simmetrica, si considera solo il valore assoluto di z, ovvero n.
- nel caso di z positivo l’area relativa sarà a destra (superiore) della media
- nel caso di z negativo l’area relativa sarà a sinistra (inferiore) della media
Quindi, per ogni valore x della variabile originaria esiste sulla curva normale un corrispondente valore di z.
L’area al di là del valore di z sulla curva normale corrisponde all’area che si trova al di là del punteggio x nella distribuzione originaria.
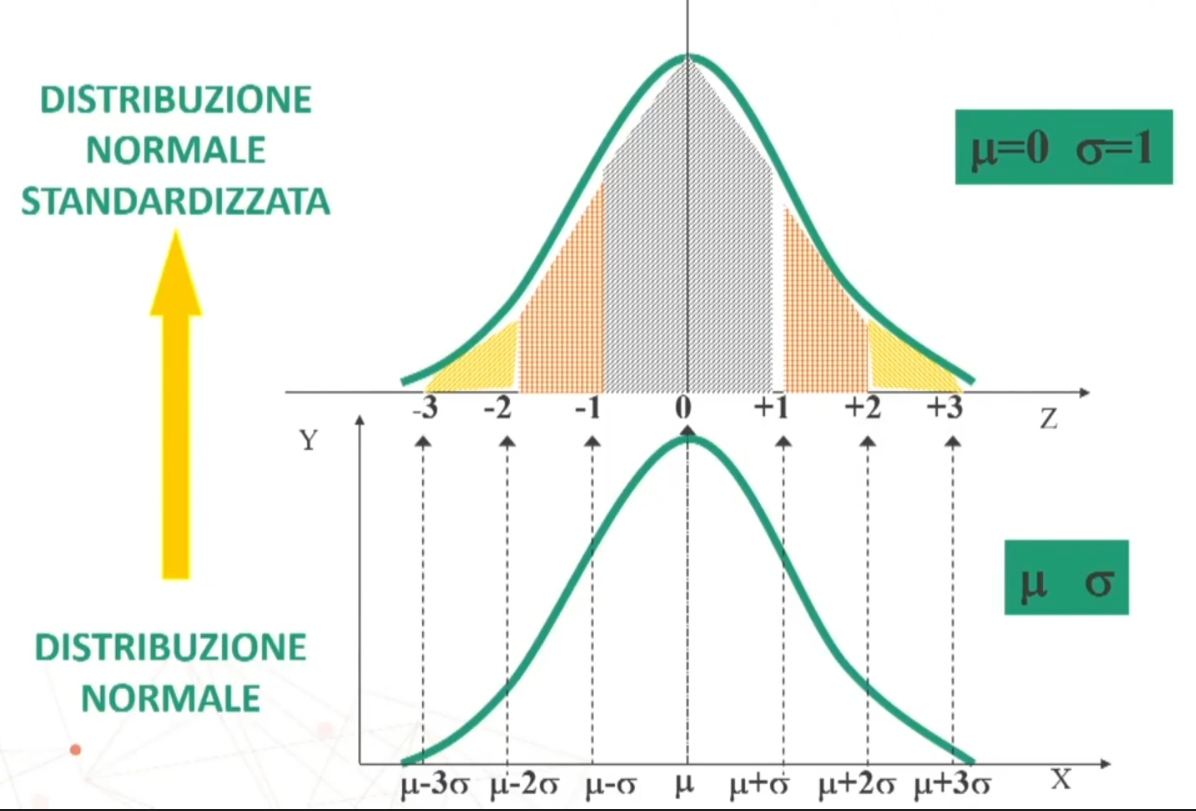
Tavola di Z ed esempio uso tavole
Le tavole Z riportano le aree comprese tra μ = 0 e un dato valore di z

La prima colonna riporta z con la prima cifra decimale, la prima riga invece riporta la seconda cifra decimale di z Incrociando i valori ottengo l’area sotto la curva.
Esempio
Esempio: Sapendo che la variabile “dominanza” si distribuisce normalmente con media = 32 e deviazione standard = 5, trovare, in un gruppo di 80 soggetti, la proporzione di casi con punteggio superiore a 35.
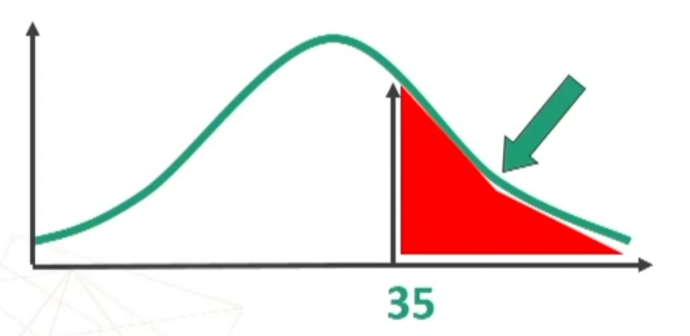
Per prima cosa devo standardizzare il punteggio 35.
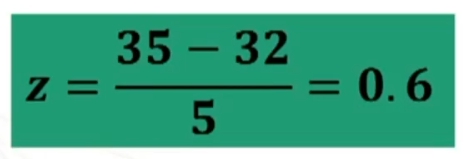
Ora trovo sulla tavola l’area compresa tra μ = 0 (i.e., media) e z = 0.6
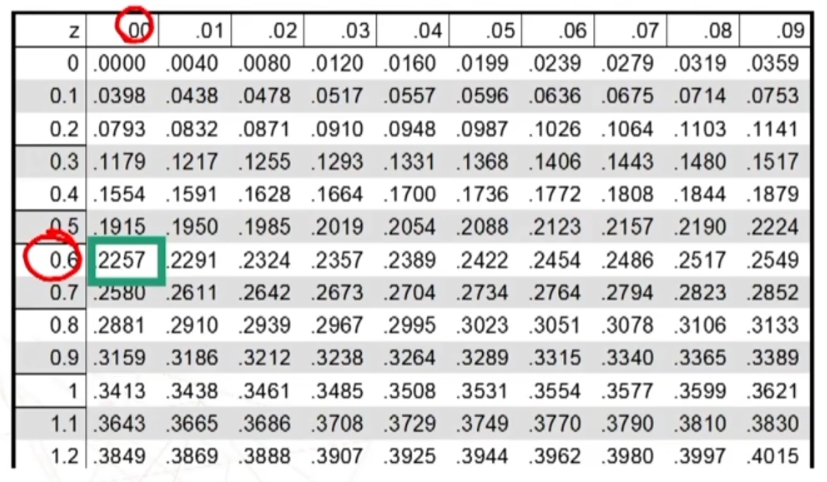
Quindi la’rea compresa tra 0 e 0.6 è quella rappresentata in figura.
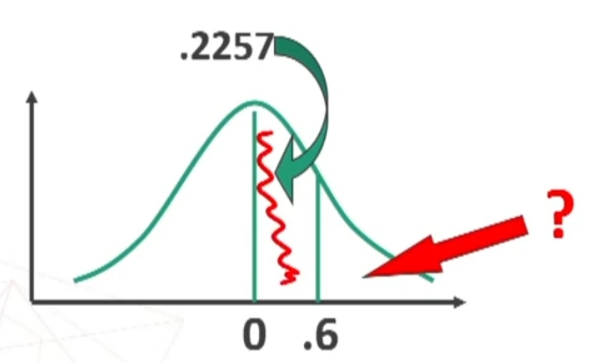
Sapendo che l’area di mezzo curva è = 0.5, ottengo l’area cercata per differenza:
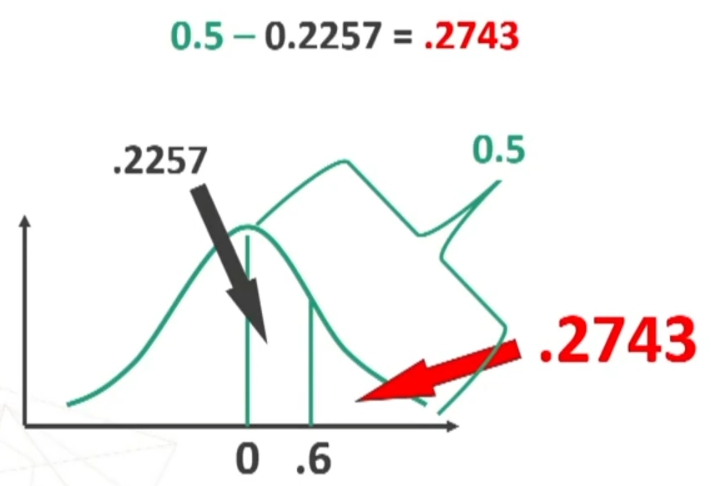
L’area trovata corrisponde al 27.43% dell’intera area. Poiché i miei soggetti sono 80, potrò prevedere che il 27.43% di 80, cioè circa 22 soggetti avranno un punteggio superiore a 35.
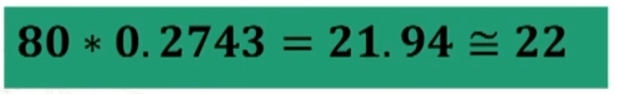
Esempio inverso
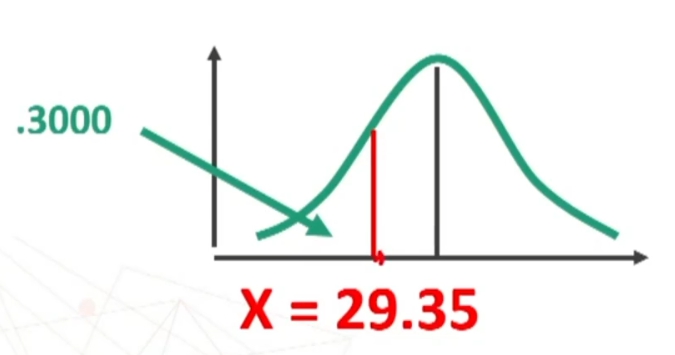
Si può anche porre il problema inverso: trovare il punteggio minimo che un soggetto deve ottenere per non essere incluso nel 30% dei peggiori, in una distribuzione con:
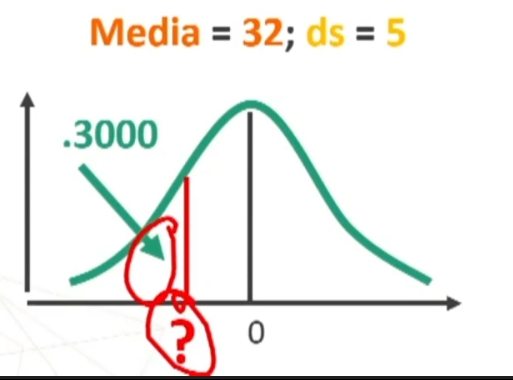
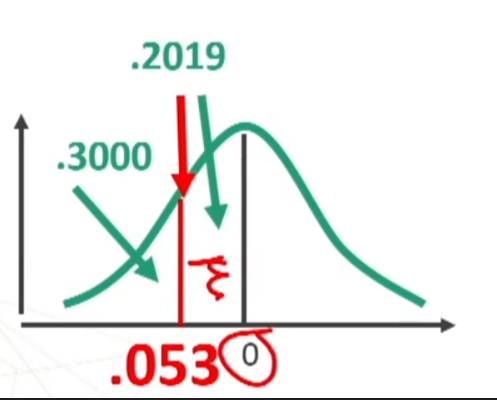
Per prima cosa trovo sulle tavole il valore di z corrispondente ad un’area di .2000 (i.e., 0.50 – 0.30). Z è .2019
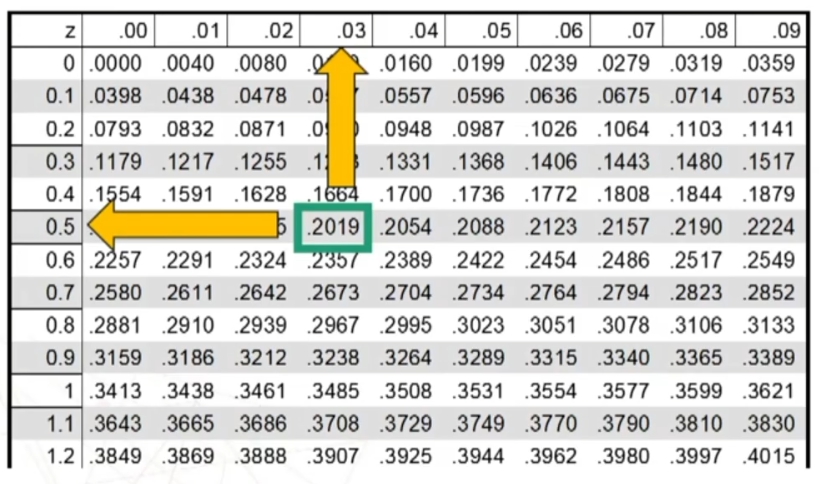
Il 20% dei soggetti è incluso fra 0 e 0.53 (devo ricordare che mi interessa il versante negativo)
Ora trasformo il valore z in punteggio X conoscendo media e deviazione standard della distribuzione:

N.B. Il valore di z è negativo (-.53) perché si trova nella parte sinistra della distribuzione.
Otteniamo che Per non essere considerati nel 30% dei peggiori bisogna avere un punteggio di almeno 30