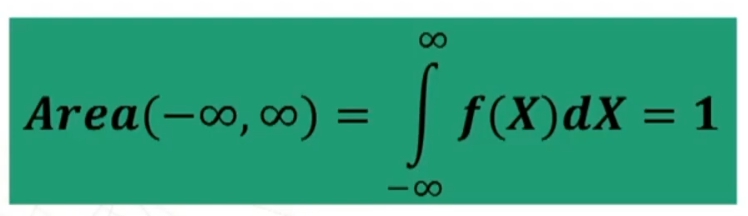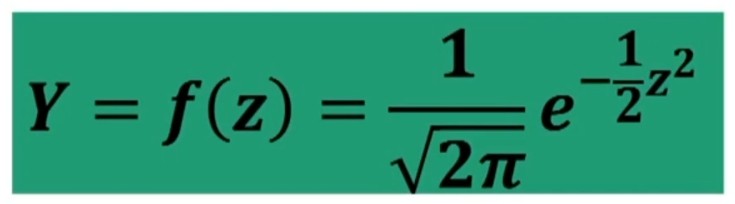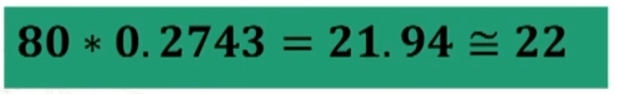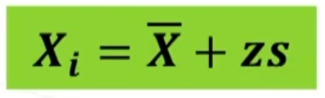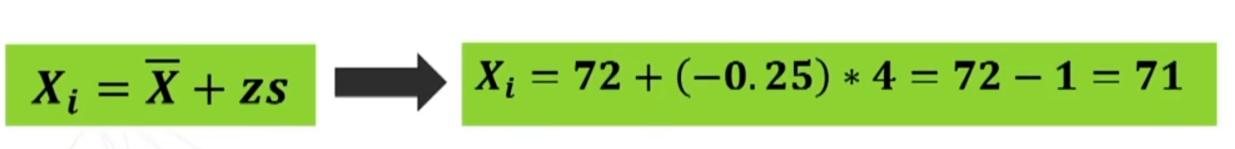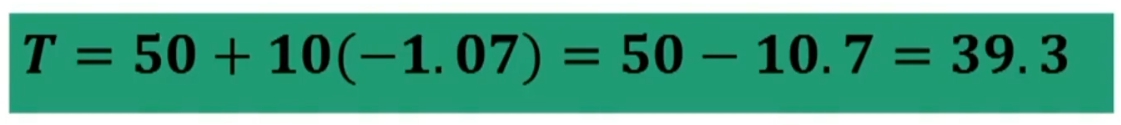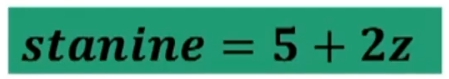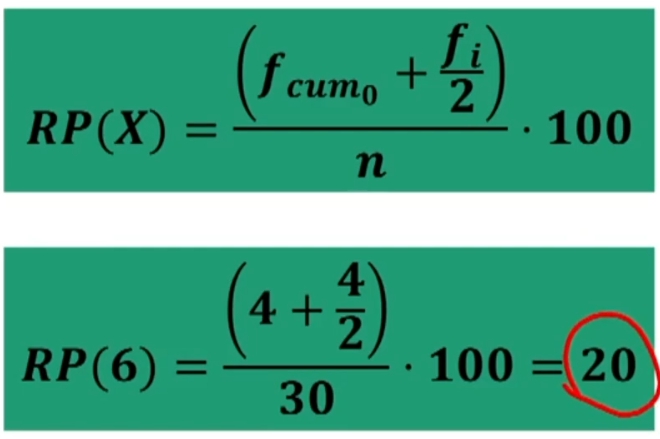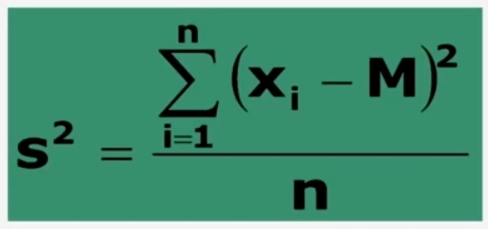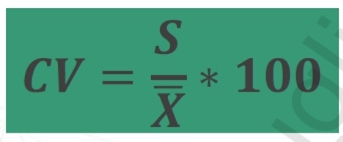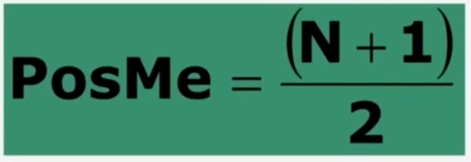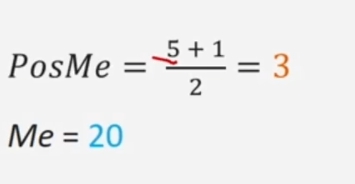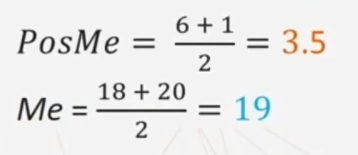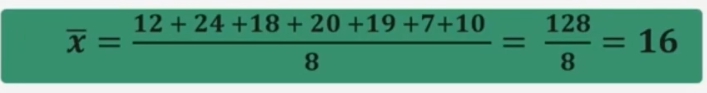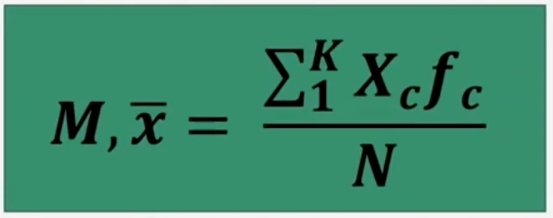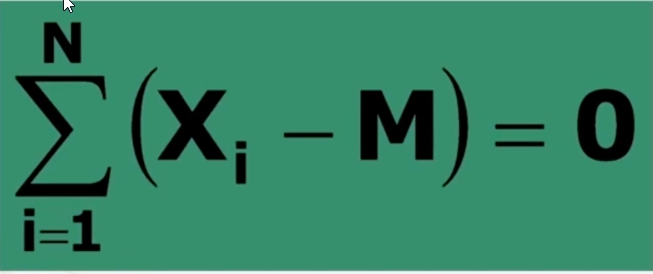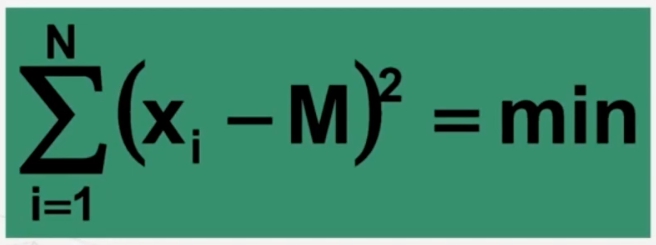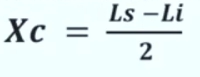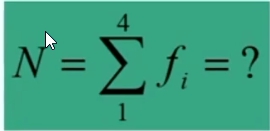La curva normale o curva di Gauss è una distribuzione teorica di punteggi in una popolazione.
Teorema del limite centrale: gauss ci dice che la somma di n variabili casuali con media e varianza finite tende a una distribuzione normale al tendere di n all’infinito
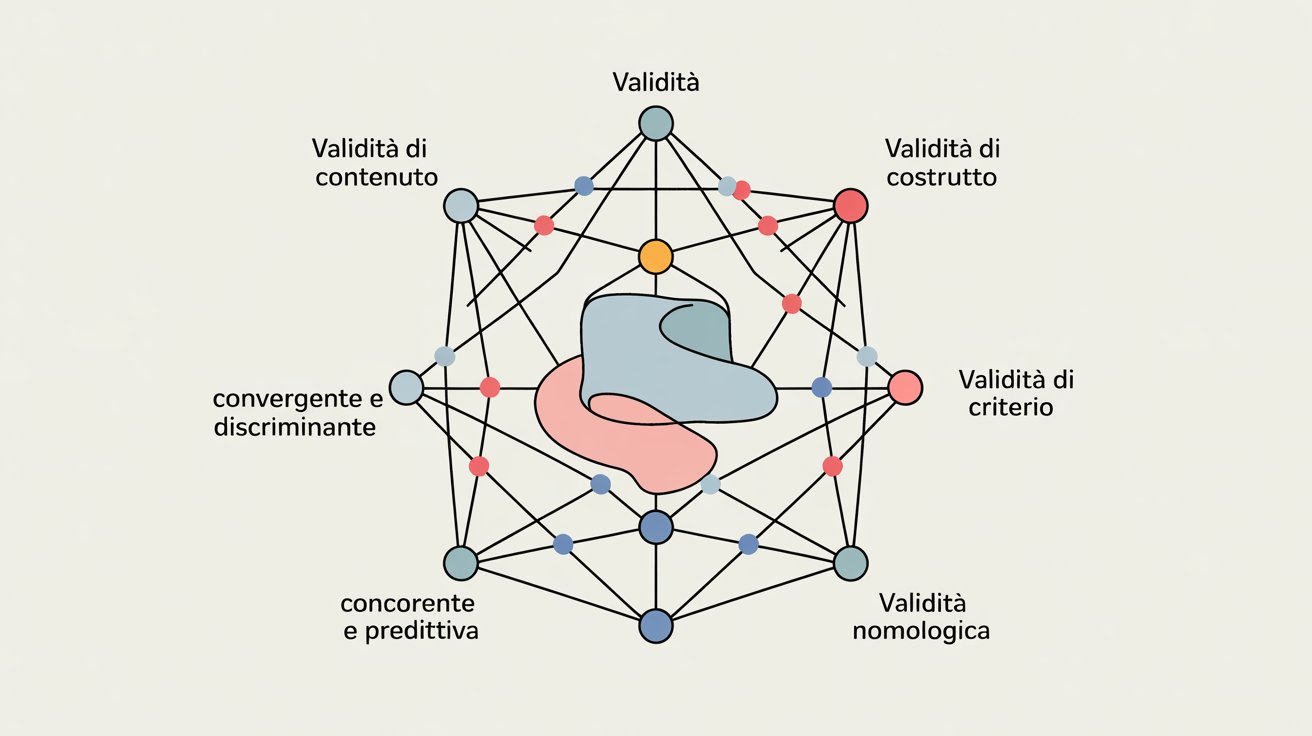
Riguarda solo le variabili metriche continue, quindi le misure almeno su scale a intervalli equivalenti.
L’importanza di questa distribuzione è dovuta al fatto che molti dei fenomeni osservati si distribuiscono normalmente o con forme che si approssimano alla curva normale Inoltre, gran parte della statistica inferenziale si basa sulle proprietà di questa distribuzione.
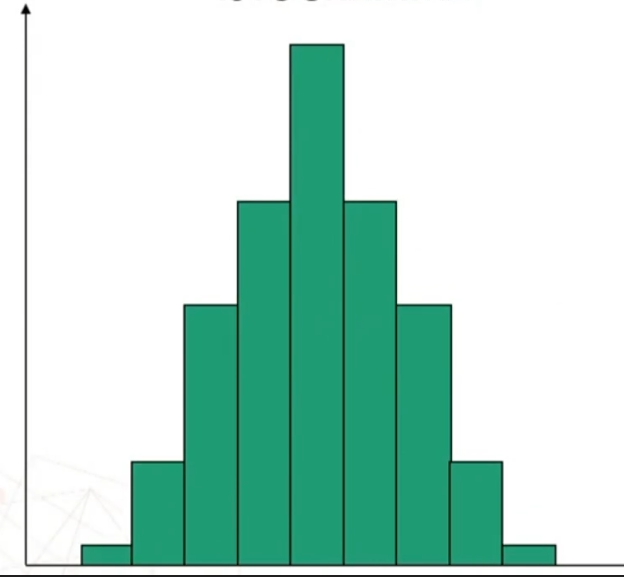
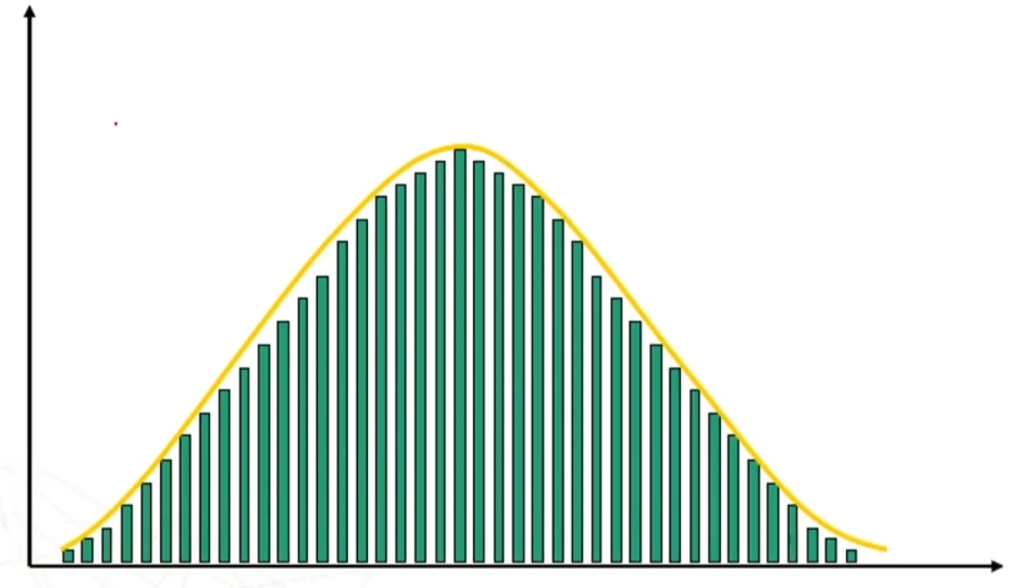
Partendo da una distribuzione di frequenza, riducendo l’ampiezza degli intervalli, otteniamo la distribuzione normale (curva continua a forma di campana – gaussiana).
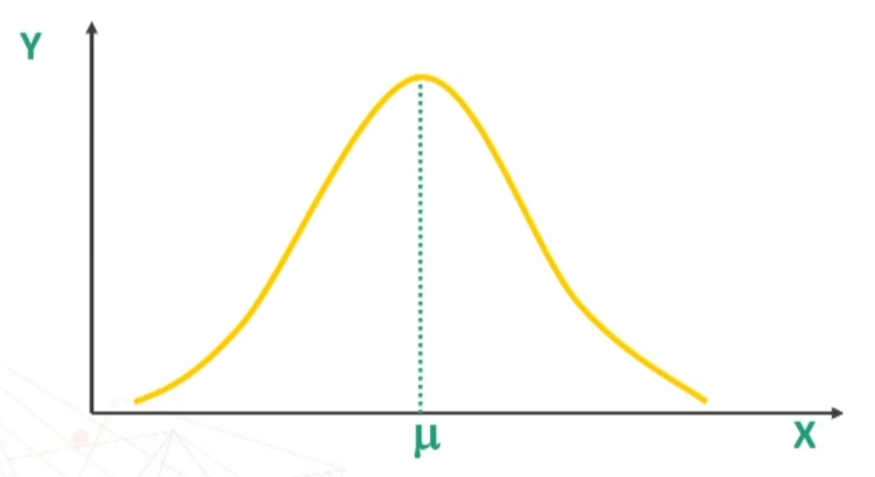
Al centro della curva abbiamo il valore centrale di X. Tale curva è definita dalla seguente equazione.
Caratteristiche e proprietà
Vediamo alcune proprietà di questa curva
INFINITA: x va da -∞ a +∞
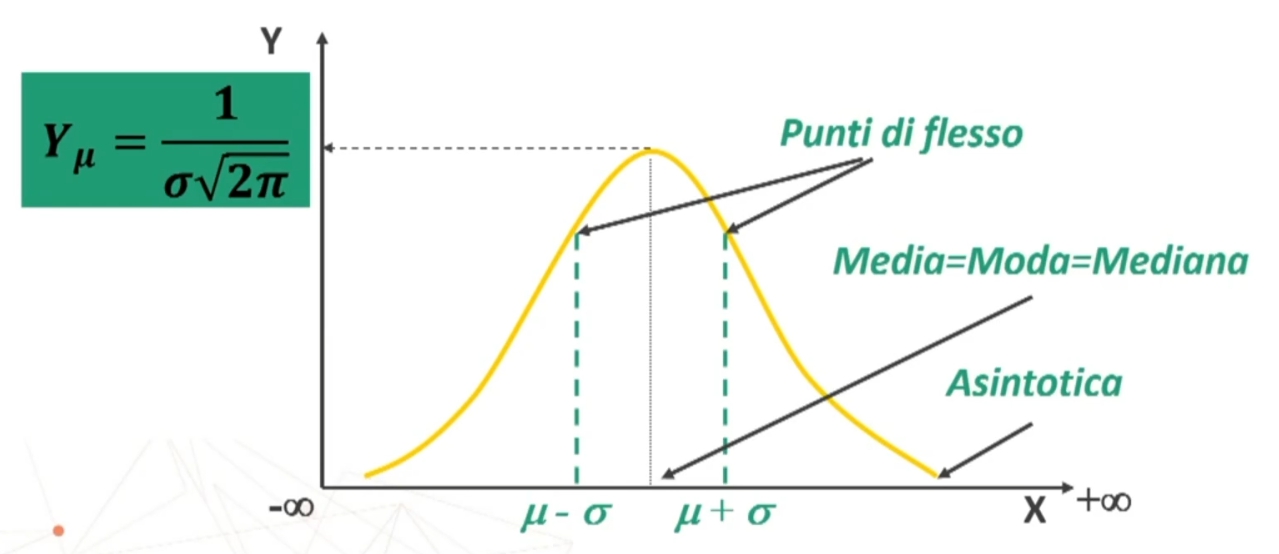
SIMMETRICA rispetto alla Y massima f(x): punto più alto x = μ
UNIMODALE: (μ = Mo = Me) (media = moda = mediana)
ASINTOTICA: si avvicina all’asse delle X senza mai toccarlo, se non ai valori di ascissa -∞ e +∞ che non sono rappresentabili
DUE PUNTI DI FLESSO: da concava diventa convessa nella metà sinistra e da convessa diventa concava nella metà destra (in corrispondenza di valori di x uguali alla media meno o più una deviazione standard)
CRESCENTE per -∞ < x < μ e DECRESCENTE per μ < x < +∞ due punti di flesso a ± σ da μ
La curva NORMALE è interamente definita dai parametri μ (la media) e σ (deviazione standard).
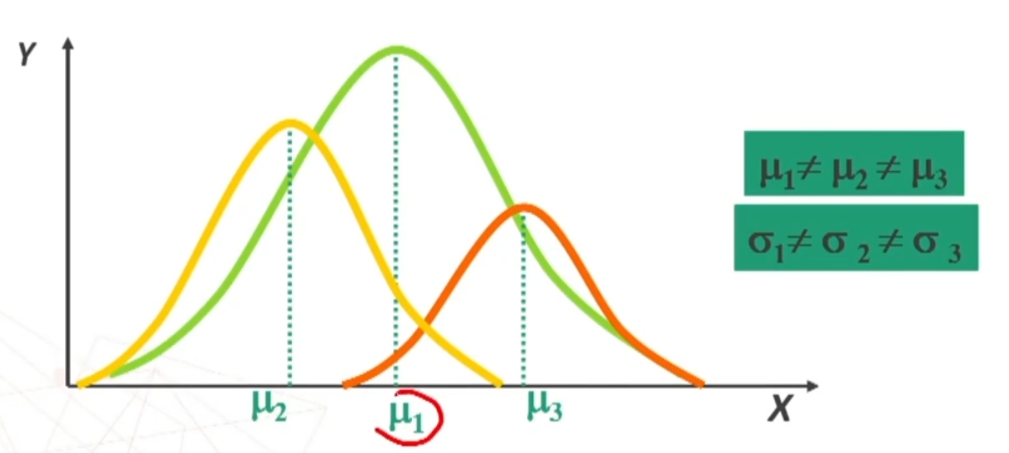
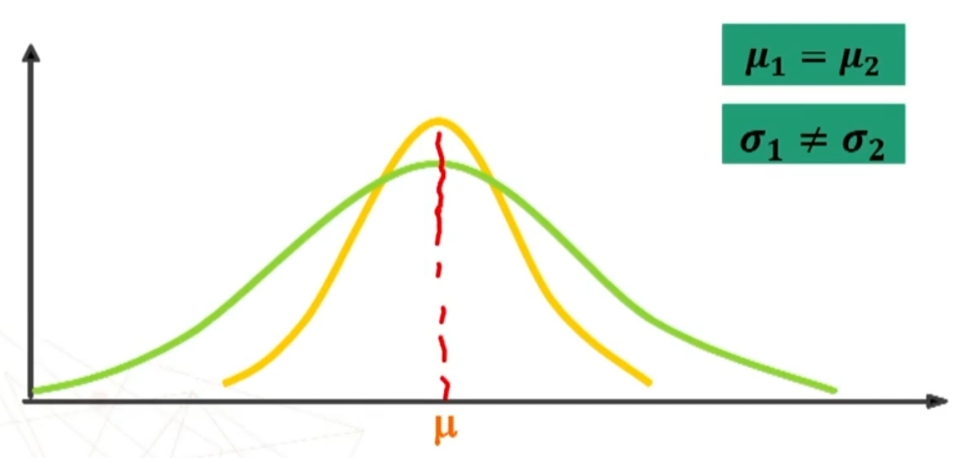
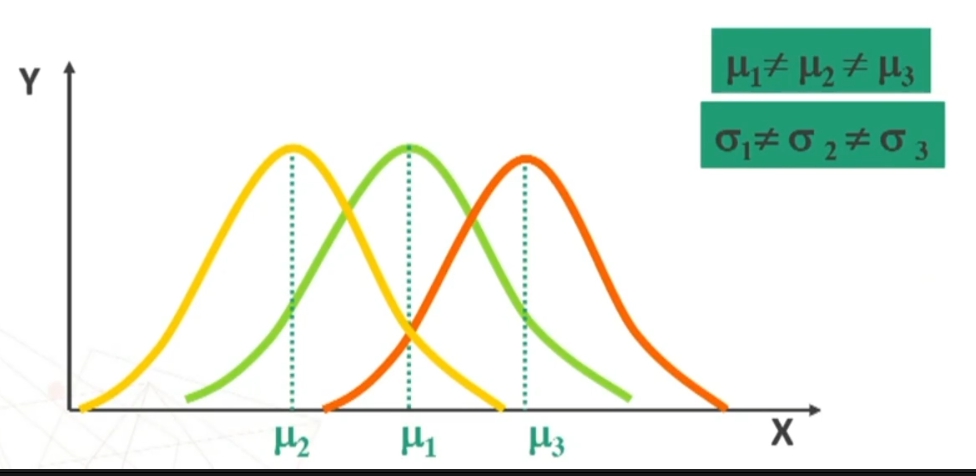
Poiché la distribuzione normale varia al variare di μ e σ si può parlare di famiglia di distribuzioni normali con medie e deviazioni standard diverse. Esempio di seguito famiglia distribuzioni normali con stessa media e deviazione standard diversa, e poi con media e deviazione standard diverse, e infine con media diversa e con deviazione standard uguale
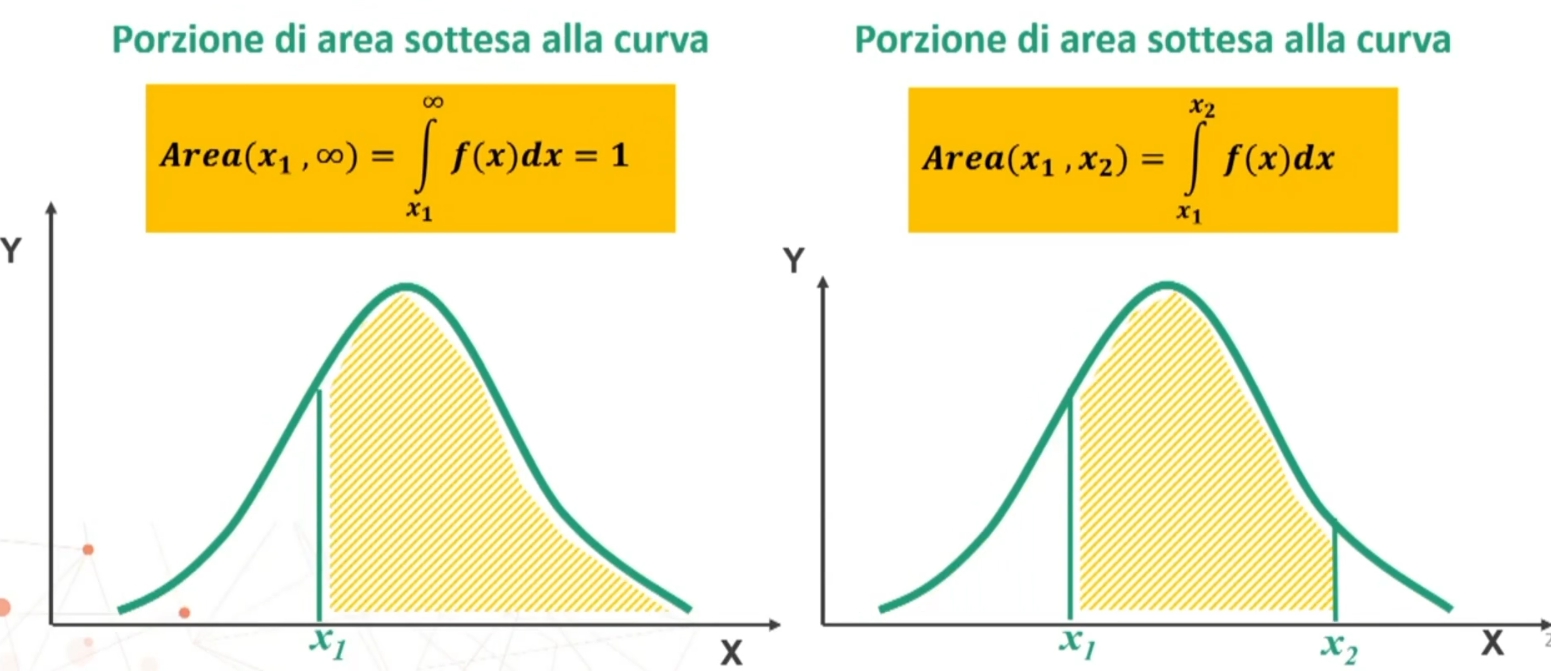
Qualsiasi siano i parametri μ e σ, l’AREA sottesa dall’intera curva è = 1. Infatti “1” è un simbolo che rappresenta il fatto che sotto la curva si trova il 100% degli individui (frequenze) rappresentati dalla variabile.
La porzione di curva delimitata dalla media e un’ordinata espressa in termini di deviazioni standard è costante:
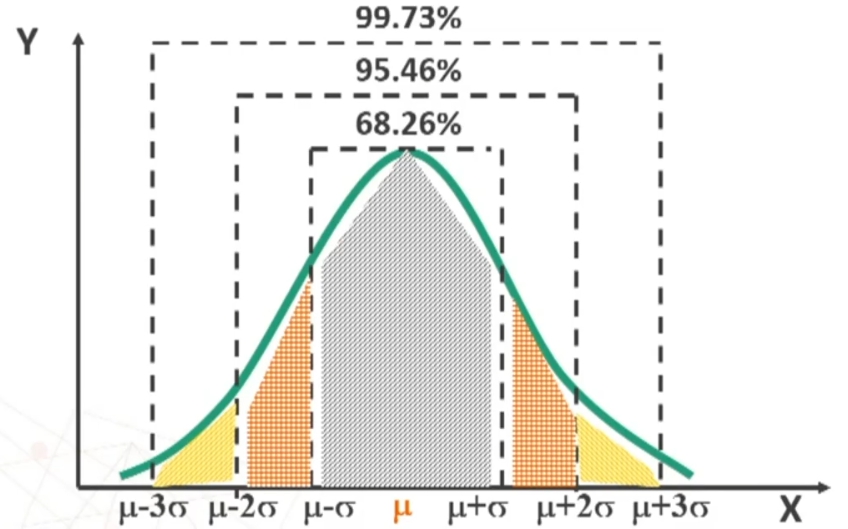
μ + σ = 34.13% della distribuzione
μ + 2σ = 47.73% della distribuzione
μ + 3σ = 49.86% della distribuzione
Conoscendo μ e σ, possiamo stimare f(x) e l’area compresa tra due qualsiasi valori di x
Poiché la curva è simmetrica, l’area compresa tra -∞ e μ è uguale a .50 come quella compresa tra μ e +∞. In altre parole, sopra la media ci sono il 50% dei casi, come sotto la media
Qualunque siano i valori di μ e σ, l’area corrispondente a intervalli definiti è sempre la stessa → Porzioni della distribuzione compresse tra ± 1, 2, 3 σ da μ (in %)
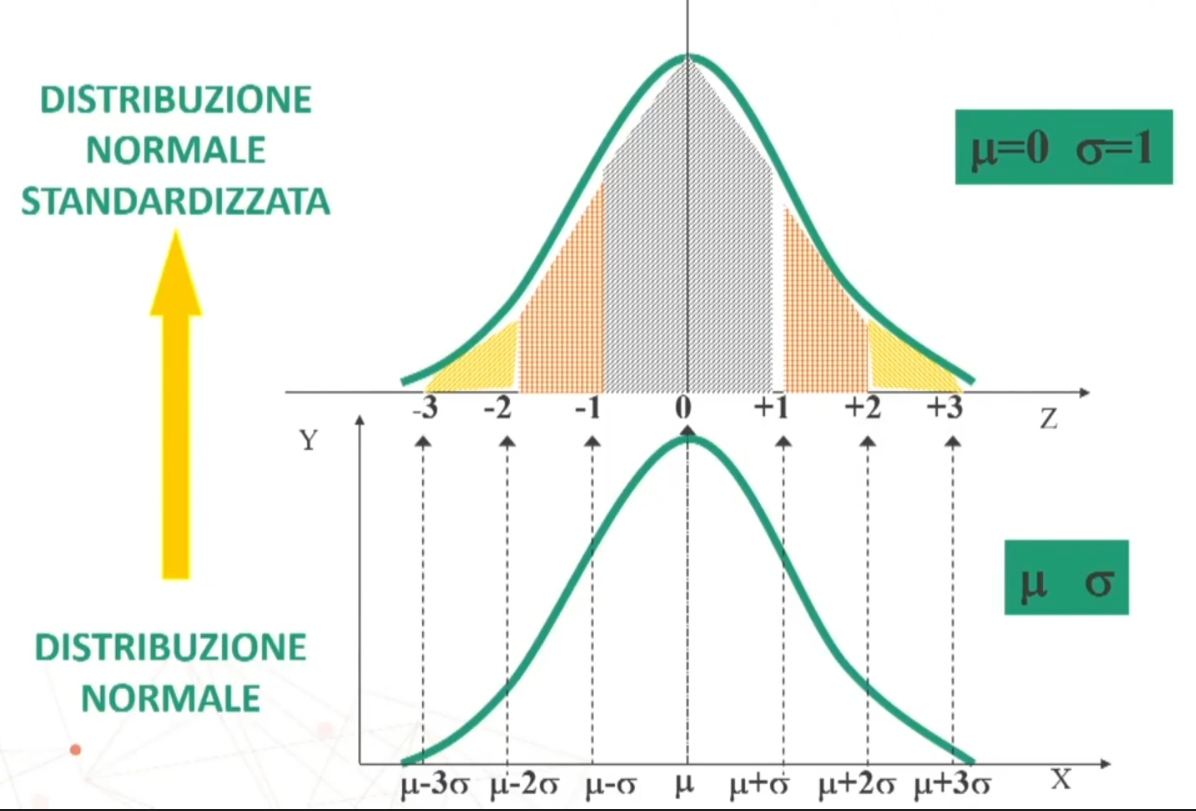
Distribuzione normale standardizzata
Per gli usi pratici della distribuzione normale si ricorre alla CURVA NORMALE STANDARDIZZATA. L’equazione della curva dipende da un solo parametro, zeta; pertanto:
I parametri di z sono noti → μ = 0; σ = 1. Di conseguenza anche i valori nella distribuzione, che pertanto possono essere tabulati (essere anch’essi noti).
In un’unica tavola sono riportate le aree della curva in corrispondenza dei diversi valori di z. La tavola prende in considerazione la metà destra della curva, quindi le aree comprese tra la media (z=0) e qualunque valore positivo di z > 0
Poiché la curva normale standardizzata è simmetrica, si considera solo il valore assoluto di z, ovvero n.
nel caso di z positivo l’area relativa sarà a destra (superiore) della media
nel caso di z negativo l’area relativa sarà a sinistra (inferiore) della media
Quindi, per ogni valore x della variabile originaria esiste sulla curva normale un corrispondente valore di z.
L’area al di là del valore di z sulla curva normale corrisponde all’area che si trova al di là del punteggio x nella distribuzione originaria.
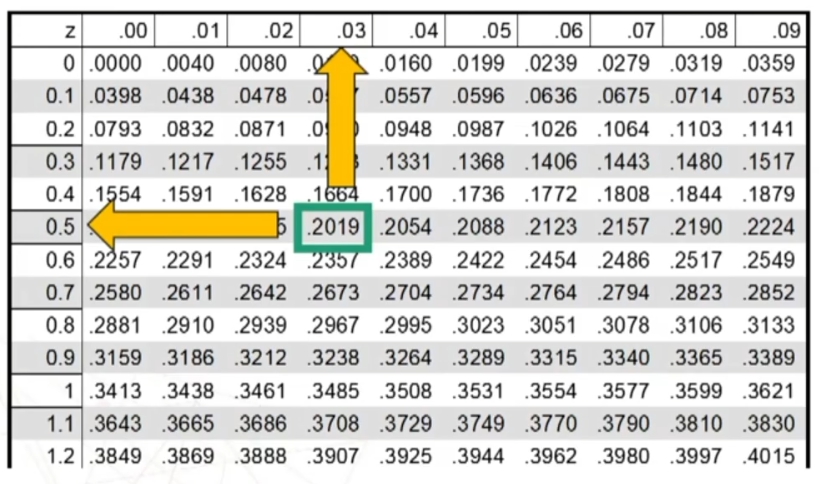
Tavola di Z ed esempio uso tavole
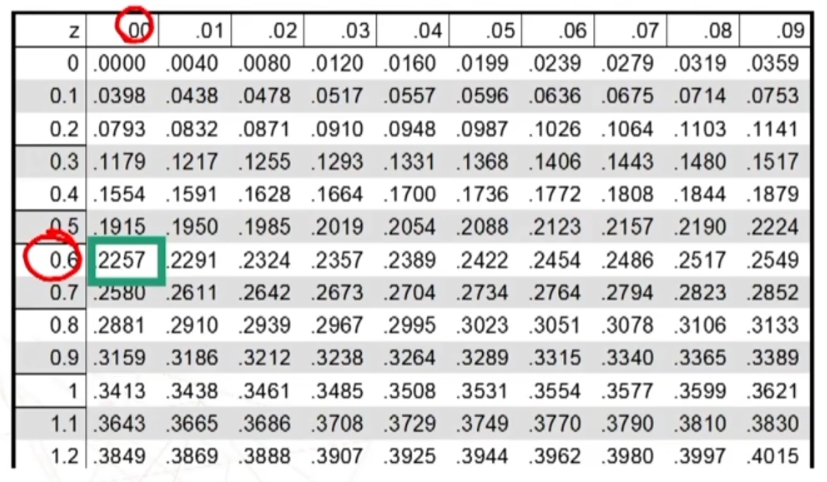
Le tavole Z riportano le aree comprese tra μ = 0 e un dato valore di z
La prima colonna riporta z con la prima cifra decimale, la prima riga invece riporta la seconda cifra decimale di z Incrociando i valori ottengo l’area sotto la curva.
Esempio
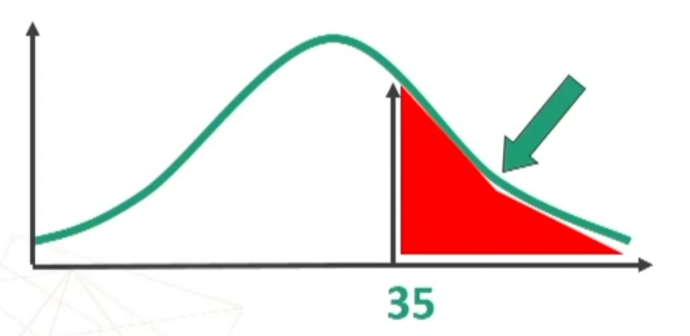
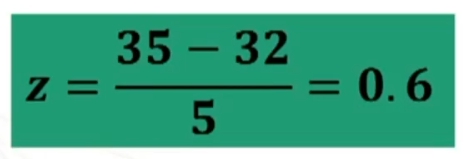
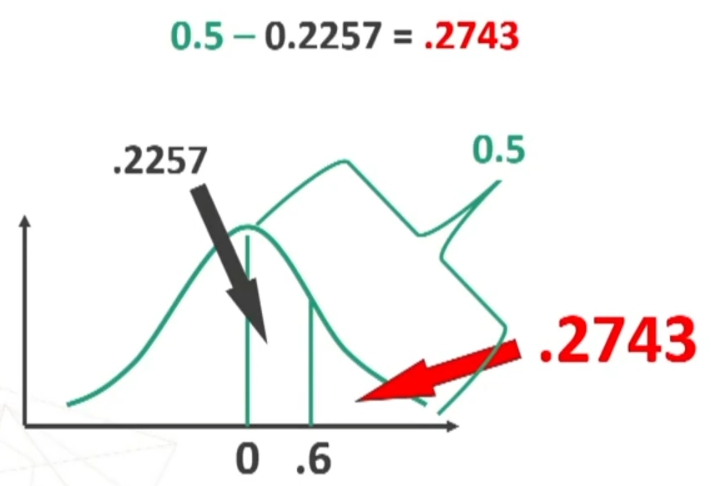
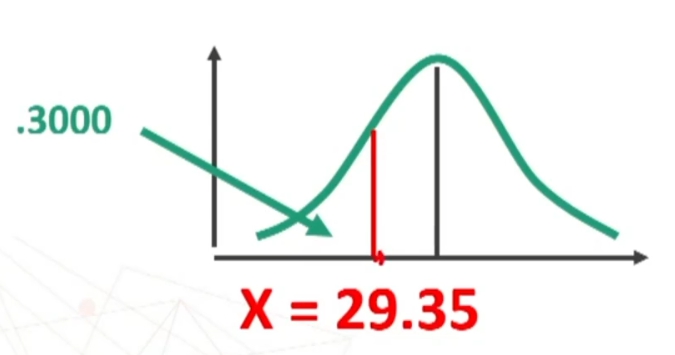
Esempio: Sapendo che la variabile “dominanza” si distribuisce normalmente con media = 32 e deviazione standard = 5, trovare, in un gruppo di 80 soggetti, la proporzione di casi con punteggio superiore a 35.
Per prima cosa devo standardizzare il punteggio 35.
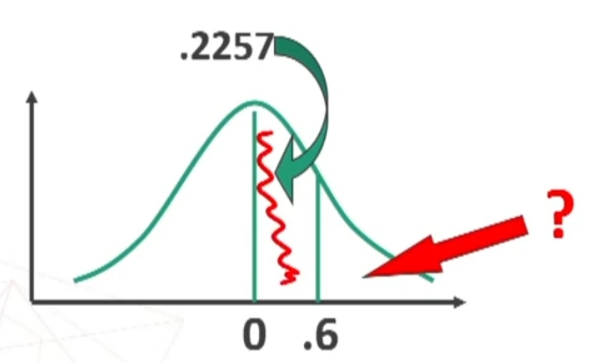
Ora trovo sulla tavola l’area compresa tra μ = 0 (i.e., media) e z = 0.6
Quindi la’rea compresa tra 0 e 0.6 è quella rappresentata in figura.
Sapendo che l’area di mezzo curva è = 0.5, ottengo l’area cercata per differenza:
L’area trovata corrisponde al 27.43% dell’intera area. Poiché i miei soggetti sono 80, potrò prevedere che il 27.43% di 80, cioè circa 22 soggetti avranno un punteggio superiore a 35.
Esempio inverso
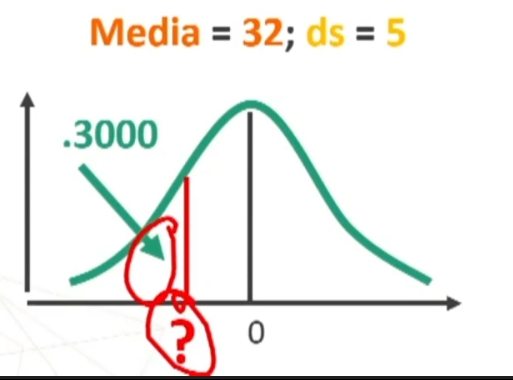
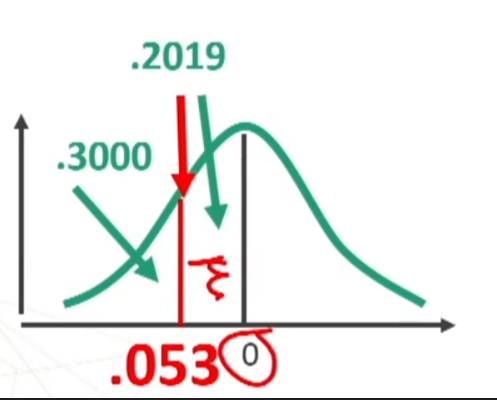
Si può anche porre il problema inverso: trovare il punteggio minimo che un soggetto deve ottenere per non essere incluso nel 30% dei peggiori, in una distribuzione con:
Per prima cosa trovo sulle tavole il valore di z corrispondente ad un’area di .2000 (i.e., 0.50 – 0.30). Z è .2019
Il 20% dei soggetti è incluso fra 0 e 0.53 (devo ricordare che mi interessa il versante negativo)
Ora trasformo il valore z in punteggio X conoscendo media e deviazione standard della distribuzione:
N.B. Il valore di z è negativo (-.53) perché si trova nella parte sinistra della distribuzione.
Otteniamo che Per non essere considerati nel 30% dei peggiori bisogna avere un punteggio di almeno 30
Un punteggio all’interno di una distribuzione è in realtà privo di significato se preso da solo.
Per esempio se si sa che un soggetto è alto 1.80m, questa informazione assume un significato ben diverso se il soggetto è un pigmeo o uno svedese. Nel primo caso sarebbe “molto alto” mentre nel secondo sarebbe “nella media”
La standardizzare consente di definire la posizione di un soggetto all’interno di una distribuzione di frequenza e, dunque, di:
confrontare due prestazioni dello stesso soggetto entro due diverse distribuzioni
confrontare le prestazioni di soggetti diversi in differenti distribuzioni
Standardizzare significa riferire la misura ad una scala standard di cui sono noti i parametri (media e varianza)
Per ottenere la standardizzazione delle misure possiamo essere utilizzati gli indicatori di tendenza centrale e di dispersione (media e devianza standard, rispettivamente) della misura non standardizzata.
La scala standard o input z
Una delle scale più comunemente utilizzate è detta «standard» o «z». Questa ha
media = 0 e varianza = 1
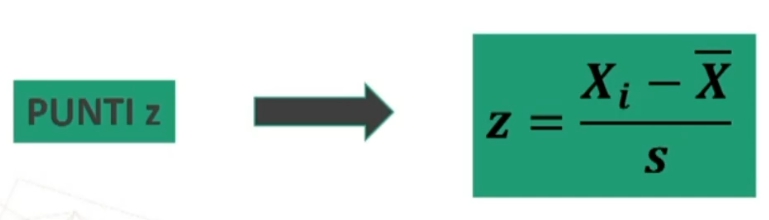
Questa scala si ottiene trasformando i punteggi Xi di una distribuzione in punteggi zi tramite la formula:
s è la deviazione standard.
I punti z
I punti z consento di riferire una misura ad una scala standard con media uguale a zero e devianza standard uguale a 1.
Esempio (confronto tra diversi soggetti)
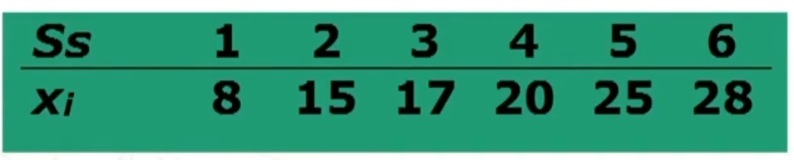
In un test di percezione visiva la media è 21.25 e deviazione standard 6.74. Trasformare in punti z i seguenti punteggi ottenuti da 6 soggetti dislessici.
utilizzando la formula vista in rpecedenza abbiamo che
otteniamo quindi la seguente scala
Faciamo alcune considerazioni sui punteggi ottenuti
Il soggetto n°2 con 14 è una devianza standard sotto la media (21.25 – 6.74 = pressapoco 14).
Il soggetto n°6 con 28 è una devianza standard sopra la media (21.25 + 6.74 = 28).
Il soggetto n°5 con 25 è circa mezza devianza standard sopra la media, ad esempio, dista dalla media la metà rispetto al soggetto n°6.
Il soggetto n°1 con 8 è due deviazioni standard sotto la media e, ad esempio, dista dalla media il doppio rispetto al soggetto n°2.
Esempio
Facciamo un altro esempio (stesso soggetto test diversi). Un soggetto ha ottenuto il punteggio di 30 in un test che misura l’ansia e 30 in un test che misura l’introversione; come è possibile sapere se in entrambe le situazioni il soggetto si è dimostrato più introverso o più ansioso? È necessario utilizzare una scala comune sulla quale “leggere” i punteggi dei due test.
Andiamo quindi a standardizare i punteggi ottenuti.
Sapendo che la media di punteggi al test di ansia è 36.6 e la devianza standard 5.97 il punteggio 30 del nostro soggetto potrà essere trasformato in:
Sapere che ha ottenuto un punteggio z di -1.05 significa che si trova al di sotto della media (segno negativo) di circa 1 devianza standard.
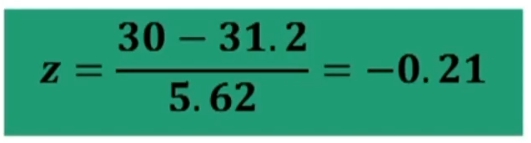
La media dei punteggi al test di introversione è 31.2 e la devianza standard 5.62; di conseguenza il punteggio di 30 diviene:
Quindi z ansia = -1.05 e z introversione = -0.21.
Su questa base si può affermare che il nostro soggetto è molto meno ansioso che introverso
Naturalmente può essere effettuata anche l’operazione inversa nel caso in cui si voglia conoscere il valore di X a partire dal valore di z corrispondente. Basta trasformare la formula nota e otteniamo l’equazione seguente
Esempio
Esempio: In un test attitudinale la media dei punteggi è 72 con s = 4. Per trovare il punteggio Xi di un partecipante di cui si sa che z = -0.25:
Altre scale standardizzate
Oltre alla scala in punti z, nei manuali dei test psicologici si incontrano altre scale che sono trasformazioni lineari della scala z (cioè, non modificano la relazione d’ordine esistente):
Scala in punti T
Scala stanine (standard nine)
Scala sten (standard ten)
Scala in punti T
Si trata di una scala con Media (M) = 50 e deviazione standard (s) = 10
La formula è la seguente
varia tra 0 e 100 e non prevede valori negativi
Esempio
Esempio: Dai dati precedenti con media dei punteggi al test di ansia 36,6 e deviazione standard 5.97, il punteggio 30 equivaleva a z = -1.07
Fate attenzione al segno! Se la z è negativa il valore di T deve essere inferiore a 50
Scala stanine (standard nine)
La scala ha M = 5 e s = 2. Si ottiene applicando la formula:
Divide la distribuzione in 9 categorie.
Scala Sten (standard ten)
La scala ha M = 5.5 e s = 2. Si ottiene applicando la formula:
Divide la distribuzione in 10 categorie.
Rango percentile
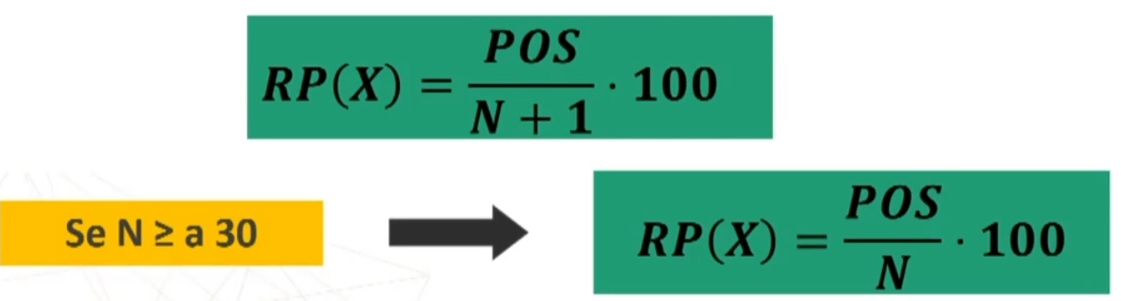
Il rango percentile RP(X) di un punteggio X può essere definito come la percentuale di dati che assumono valore minore o uguale a X.
Se un soggetto ha un punteggio Xi, dire che RP(Xi) = 35 significa che nella distribuzione ordinata dei dati il punteggio Xi lascia alla sua sinistra il 35% dei dati della distribuzione.
Per il calcolo possiamo procedere nel modo seguente
Si dispongono i dati in ordine crescente;
Si individua la posizione (POS) del punteggio che interessa;
Si applica la formula: (primo caso solo se minore 30 partecipanti, altrimenti si applicala seconda)
Esempio
Esempio: Supponiamo di aver ottenuto i seguenti punteggi (dati non raggruppati): 25, 34, 34, 58, 48, 38, 54. Vogliamo conoscere il RP del punteggio 38.
Prima ordino i dati: 25, 34, 34, 38, 48, 54, 58.
Abbiamo che 38 occupa la terza posizione.
Un caso un pò più complicato riguarda la stima del rango percentile di una distribuzione di frequenza con dati raggruppati in classi.
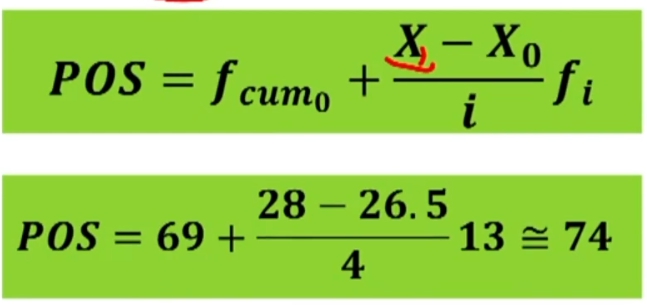
La prima cosa da fare è disporre le classi in ordine crescente. Poi si individua la posizione (POS) del punteggio Xi che interessa, con la formula
Esempio
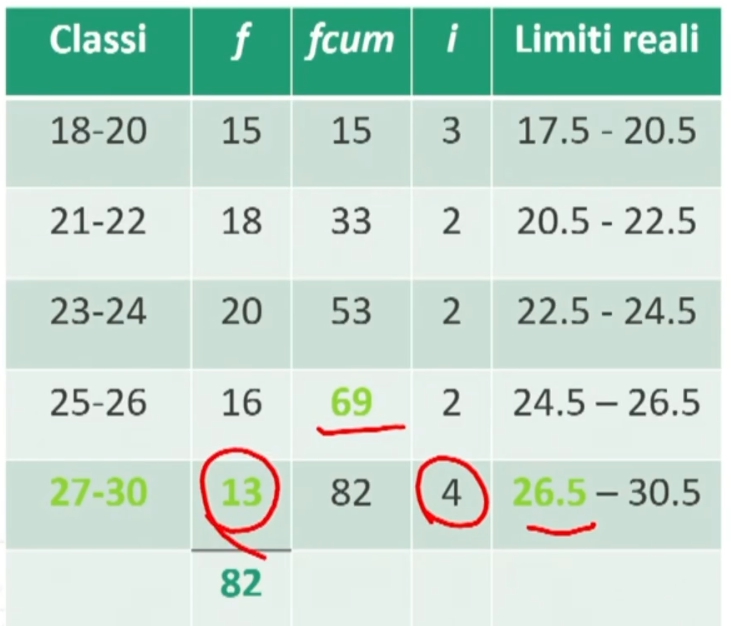
Esempio consideriamo la seguente tabella
Ora si individua la posizione POS del punteggio 28 con la formula.
Calcoliamo il RP del punteggio 28
Esempio
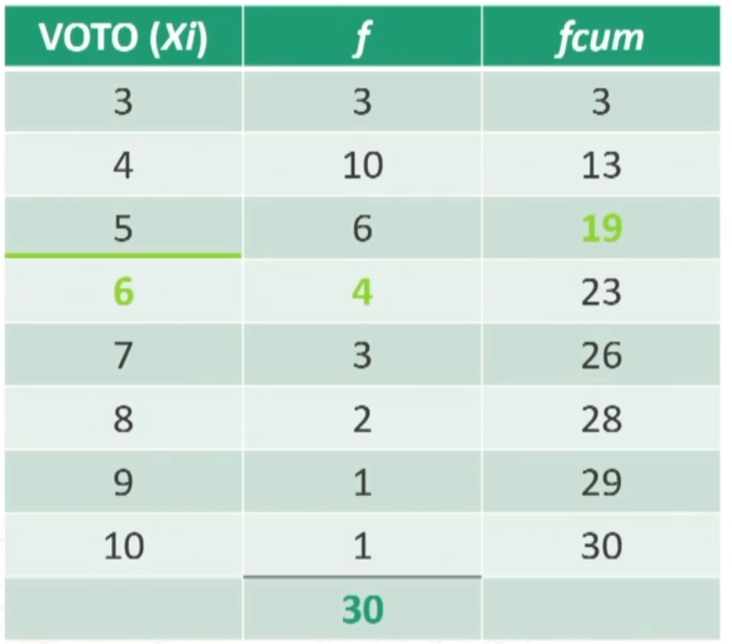
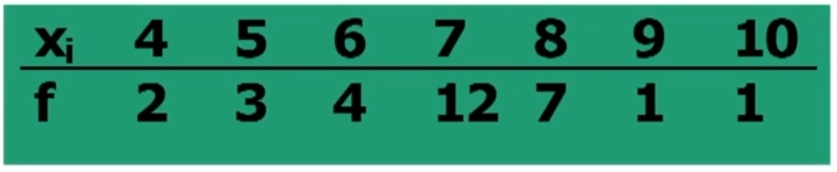
Esercitazione: Nella classe di Giulio i voti all’ultimo compito di Matematica sono stati i seguenti:
Giulio ha preso 6 al compito di matematica. Come valuto la sua prova?
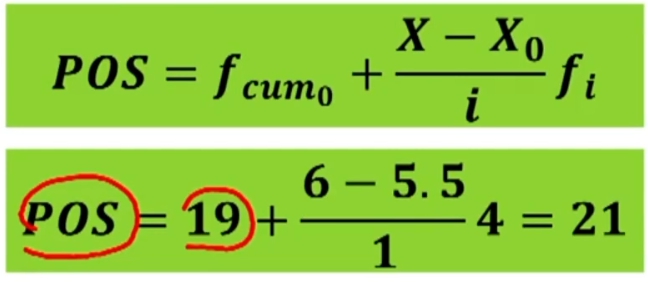
Si individua la posizione (POS) del voto 6:
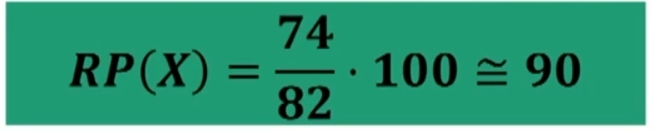
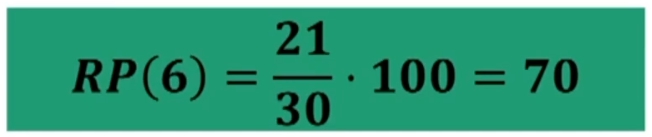
Calcoliamo il RP del voto 6
Se le classi hanno ampiezza unitaria si può usare la formula abbreviata
Esercizio
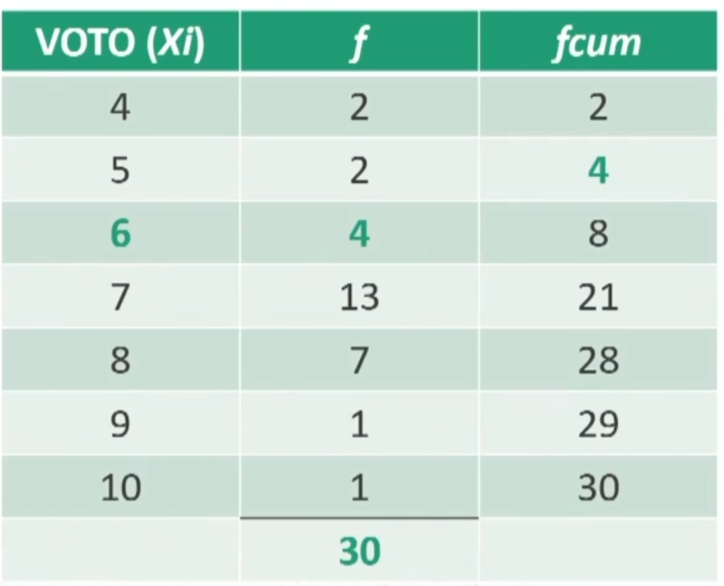
Esercizio: Giulio ha preso 6 anche al compito di Italiano. I voti della classe sono i seguenti:
Come valuti la sua prova? Avendo preso sia a Matematica che a Italiano 6, posso dire che Giulio è ugualmente bravo nelle due materie rispetto alla sua classe?
Calcoliamo il RP del voto 6 con la formula abbreviata:
Il voto 6 in Italiano corrisponde al 20° percentile → Giulio lascia dietro di sé solo il 20% dei compagni. Sebbene il voto sia lo stesso, la sua prova è peggiore rispetto a quella di matematica relativamente alla classe.
Ergo Giulio non è particolarmente bravo in Italiano, mentre è abbastanza bravo in Matematica (RP = 70).
Esercizio
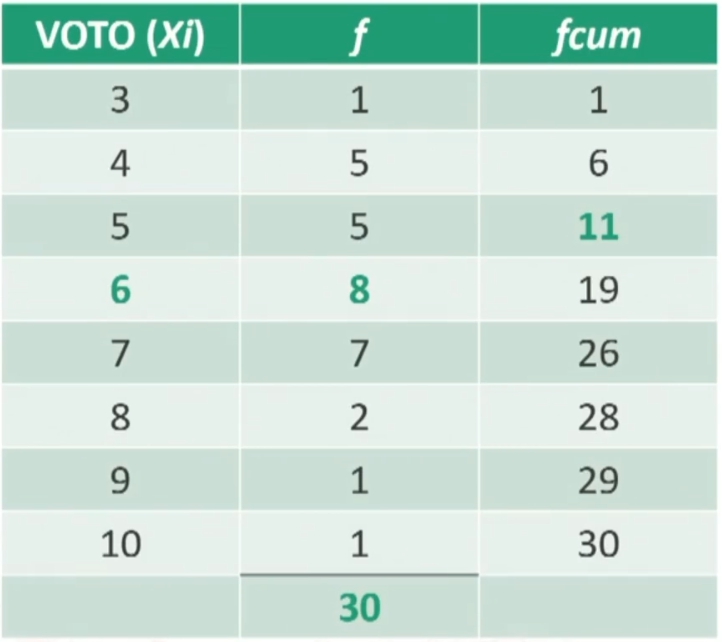
Esercizio: Marta ha preso 6 al compito di Matematica. I voti della sua classe sono i seguenti:
Come valuti la sua prova? Posso dire che Giulio e Marta sono ugualmente bravi in Matematica, tenendo conto dei risultati delle rispettive classi di appartenenza?
Calcoliamo il RP del voto 6 di Marta
Il voto 6 in matematica corrisponde al 50° percentile → Marta lascia dietro di sé il 50% dei compagni. Sebbene il voto sia lo stesso, relativamente alle classi di appartenenza, la sua prestazione è peggiore rispetto a quella di Giulio (RP = 70).
I due parametri fondamentali che consentono di sintetizzare i dati sono:
INDICATORE DI TENDENZA CENTRALE
INDICATORE DI DISPERSIONE
Oltre all’indicatore di tendenza centrale (valore che riassume i dati), è utile disporre di un valore o parametro capace di rappresentare la variabilità dei dati (cioè, la loro dispersione).
Tale valore o parametro è definito INDICATORE DI DISPERSIONE. Può essere ottenuto SOLAMENTE su scale di misura a INTERVALLI EQUIVALENTI e a RAPPORTI EQUIVALENTI.
Nel caso di dati qualitativi rilevati su scala nominale o ordinale, non si ha possibilità di quantificare la dispersione perché i dati non variano. Infatti i numeri sono semplici etichette per identificare categorie e per ordinarle.
Abbiamo una vasta scelta intermini di indicatori di variabilità dei dati, ciascuno con i propri vantaggi e svantaggi
Campo di variazione
differenza interquartilica
scarto semplice medio
varianza
Scarto quadritico medio o deviazione standard
coefficiente i variazione
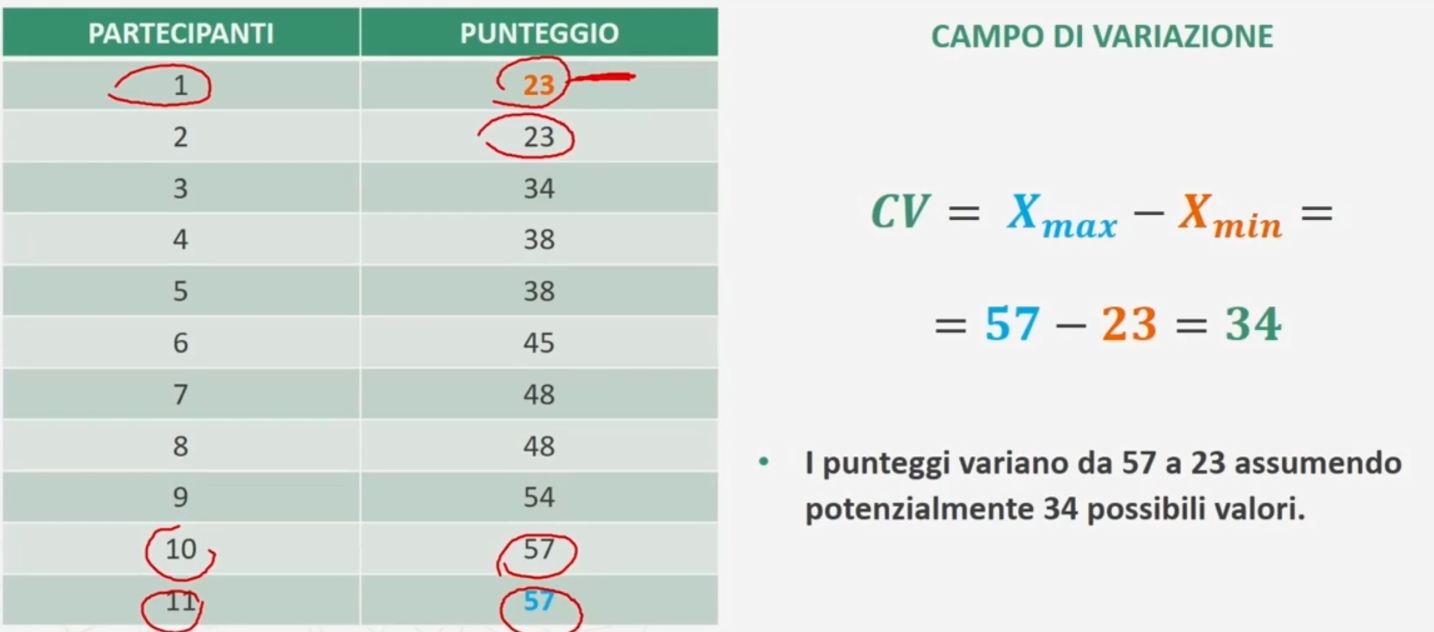
Campo di variazione
Questo è dato dalla differenza tra il valore maggiore e quello minore della distribuzione di frequenza osservata.
Esempio: 11 ragazzi di 8 anni hanno ottenuto ad un test la seguente serie di punteggi: 23 45 34 57 23 57 48 38 38 54 48
I punteggi variano da 57 a 23 assumendo potenzialmente 34 possibili valori.
LIMITI:
Troppo sensibile ai valori aberranti (cioè, estremi)
Poco informativo
Viene usato solo in modo generico
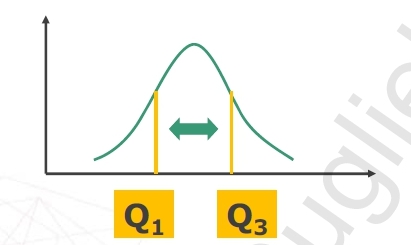
Differenza interquartilica
La differenza interquartile è data dalla differenza tra il terzo e il primo quartile
Questo indice richiede una scala di misura metrica
In pratica la differenza interquartilica è analoga al campo di variazione ma tiene conto soltanto dei valori che cadono tra il 1° e il 3° quartile (cioè del 50% della distribuzione)
Riprendendo l’esempioprecedente degli 11 ragazzi di 8 anni abbiamo
Il 50% dei punteggi si distribuisce tra 54 e 34 assumendo potenzialmente 20 possibili valori.
Il limite di questo indicatore è chè è un indice che non tiene conto di cosa accade al centro della distribuzione (casi centrali) e agli estremi della distribuzione.
Indicatori di dispersione
Per ottenere un indice unico e sintetico di dispersione dei dati è necessario che i dati siano misurati su scale metriche, quindi a intervalli equivalenti o a rapporti equivalenti.
I più importanti indicatori di dispersione per questo genere di misure sono quelli che tengono conto della distanza di ciascun valore dalla media della distribuzione.
Per ottenere un indice di dispersione che tenga conto del contributo dei singoli casi:
Si calcolano gli scarti dei valori osservati dalla media
Si fa una media di questi scarti
Abbiamo infatti visto che la somma degli scarti dei singoli valori che compongono la media è sempre uguale a 0.
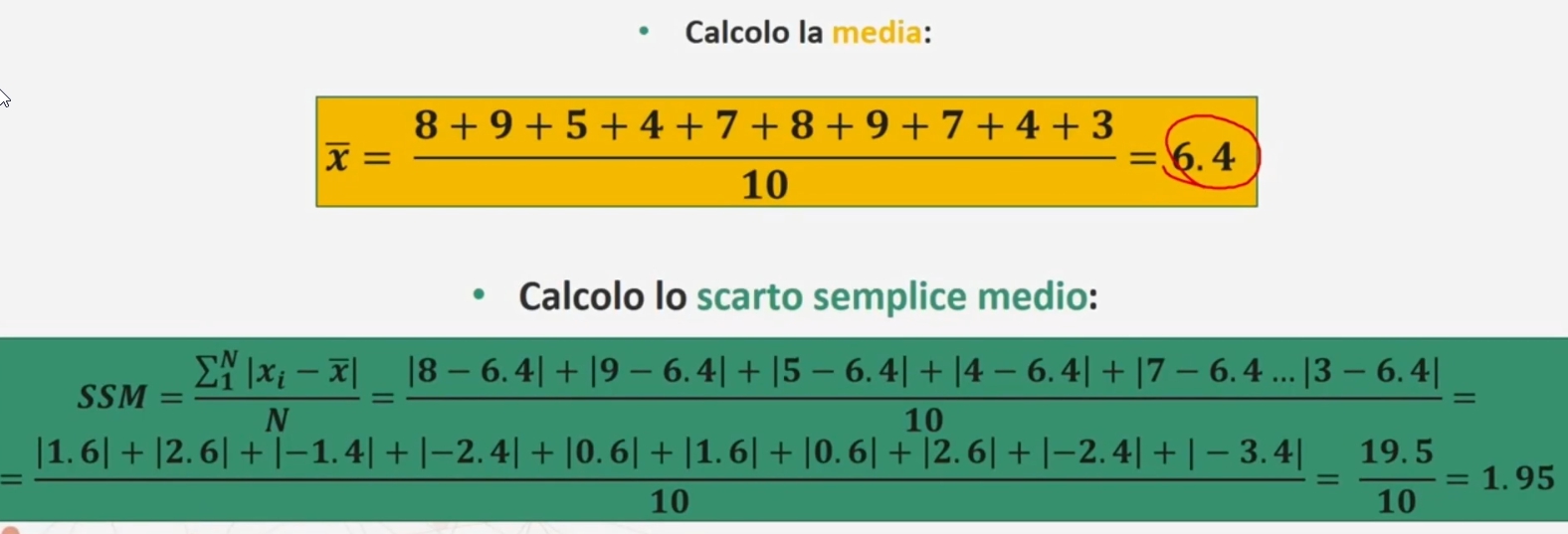
Scarto (scostamento) semplice medio
La formula per questo indicatore è
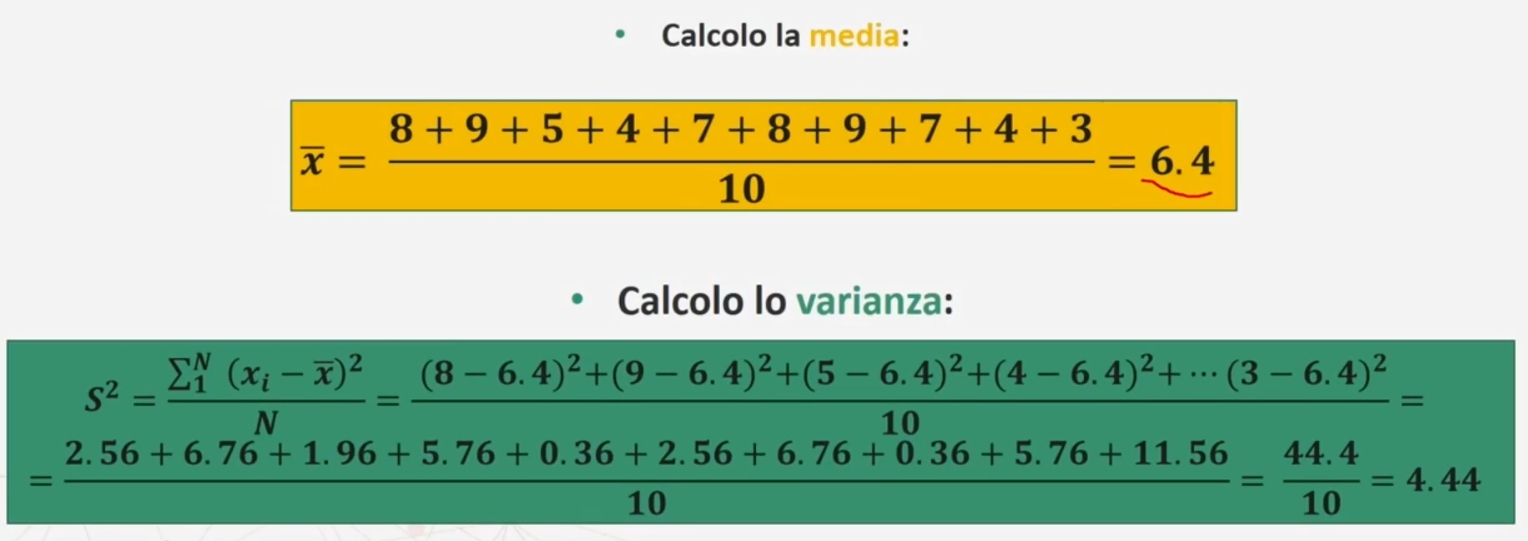
Ad esempio. Ad un test di personalità, 10 adolescenti hanno ottenuto i seguenti punteggi: 8 9 5 4 7 8 9 7 4 3. Andiamo a calcolare lo scostamento semplice medio, seguendo questi passaggi
Facciamo due considerazione sui vantaggi e limiti di questo indicatore.
VANTAGGI: Consente di avere un indicatore diverso da zero che considera gli scostamenti dei punteggi dalla media
LIMITI: Poco utilizzato rispetto al più noto e studiato indicatore di variabilità: LA VARIANZA
Varianza
La varianza si definisce come media al quadrato degli scostamenti dalla media. Poiché la somma degli scarti dalla media è zero, sommo gli scarti al quadrato:
ESEMPIO. Ad un test di personalità, 10 adolescenti hanno ottenuto i seguenti punteggi: 8 9 5 4 7 8 9 7 4 3. Andiamo a calcolare la varianza
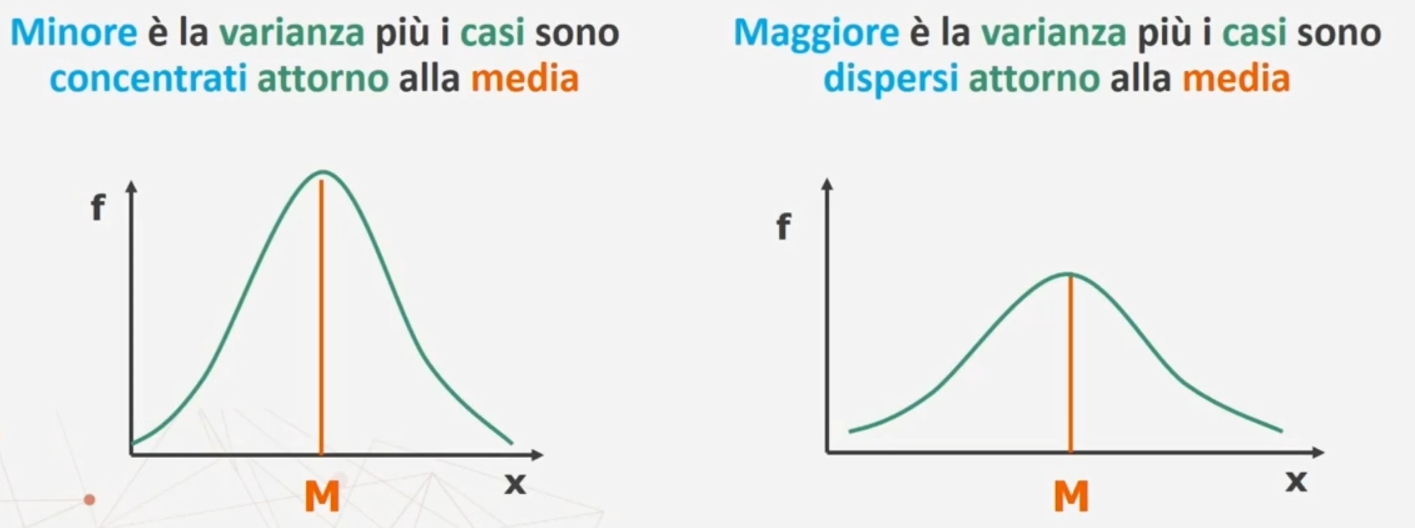
La varianza non è mai negativa. Minore è la varianza più i casi sono concentrati attorno alla media. Maggiore è la varianza più i casi sono dispersi attorno alla media.
VANTAGGI: Indicatore di variabilità molto utile per elaborazioni sofisticate.
LIMITI: Non utilizza la stessa unità di misura della media: es., altezza media di un gruppo = 170cm; s² = 169. Abbiamo difficoltà a capire cosa significhi tale valore rispetto alla misura d’interesse. Tale difficoltà è data dal fatto che la varianza è un indice quadratico. Per superare questo limite usiamo l’indicatore deviazione standard
Scarto quadrico medio (deviazione standard)
La deviazione standard è la Radice quadrata della Varianza. Inoltre è un indice di dispersione con unità di misura uguale alla media, ed indica di quanto mediamente i dati osservati si discostano dalla loro media.
es., altezza media di un gruppo = 170cm; s² = 169 → s = 13cm
ESEMPIO: Ad un test di personalità, 10 adolescenti hanno ottenuto i seguenti punteggi: 8 9 5 4 7 8 9 7 4 3. Andiamo a calcolare la deviazione standard.
VANTAGGI della deviazione standard:
Indicare con un unico valore lo scostamento medio dei dati dalla loro media.
Stessa unità di misura della media.
Indicatore di dispersione più usato per valutare la variabilità dei dati, insieme alla media (che sintetizza l’insieme di dati).
La media e la deviazione standard vengono usualmente riportati insieme come statistiche descrittive → x̄ ± s.
Esempio si può dire che i 10 adolescenti al test di personalità ottengono una media di 6.4 ± 2.11 (6.4 valore medio, 2.11 deviazione standard)
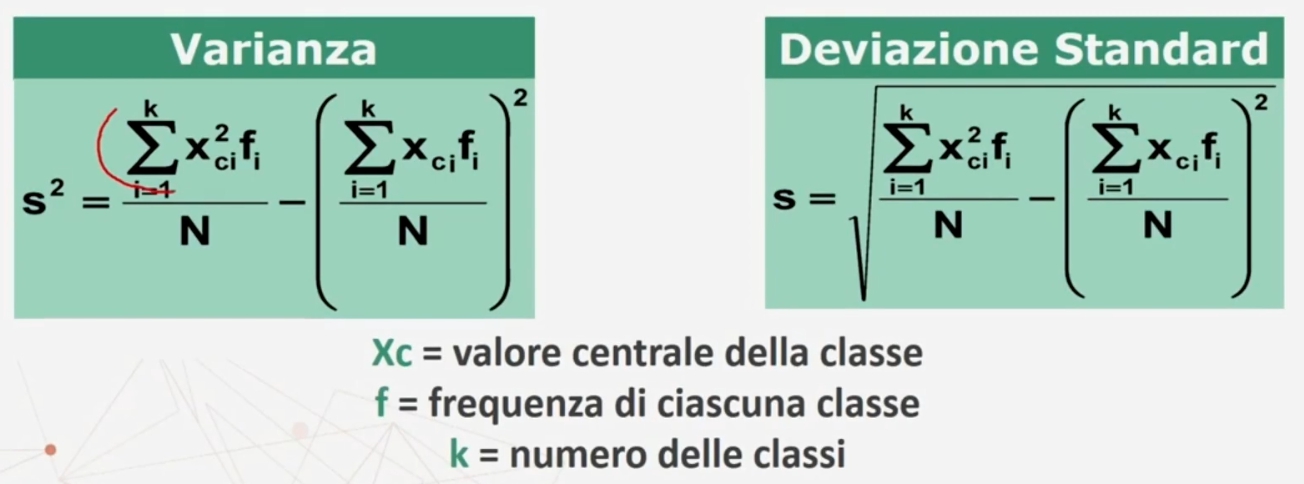
Varianza e deviazione standard
Esistono formule abbreviate che consentono il calcolo direttamente dai dati grezzi (cioè senza il calcolo separato della media e dei singoli scarti)
Notare che la seconda parte delle formule non è altro che la media.
Facciamo un esempio: solito test personalità con i seguenti punteggi 8 9 5 4 7 8 9 7 4 3. Andiamo a calcolare varianza e deviazione standard con formule abbreviate
Ulteriori varianti delle formule per il calcolo di varianza e deviazione standard sono quelle relative ai dati raggruppati in classi.
Coefficiente di variazione
Questo coefficiente sintetizza il rapporto tra Media e Deviazione Standard.
E’un indicatore di variabilità relativa (al contrario della deviazione standard che è assoluta).
Permette di valutare la dispersione dei valori attorno alla media indipendentemente dall’unità di misura della variabile (usa la media stessa come unità di misura).
ESEMPIO: Supponiamo di avere un reddito medio in lire e euro con relative deviazioni standard
Reddito medio in Lire: x̄ = 30.000.000, s₁ = ± 2.000.000
Reddito medio in Euro: x̄ = 15.493,71; s₂ = ± 1.032,91
Le due deviazioni standard hanno unità di misura diversa e questo non ci permette di confrontarle.
Confrontando i due valori abbiamo s₁ = ± 2.000.000 > s₂ = ± 1.032,91 ovvero il reddito espresso in lire ha una maggiore variabilità assoluta.
Però calcolando i due coefficienti di variazione abiamo che
ovvero il reddito espresso in lire o euro hanno la stessa variabilità relativa
Il ricercatore è interessato allo studio di fenomeni che variano. Proprio questa variabilità consente di stabilire dei nessi e di formulare ipotesi.
A tal fine, è necessario identificare i parametri che sono capaci di riassumere la variabilità dei dati grezzi e descrivere l’oggetto di ricerca.
I due parametri fondamentali che consentono di sintetizzare i dati sono:
INDICATORE DI TENDENZA CENTRALE -> valore che rappresenta un insieme di dati grezzi.
INDICATORE DI DISPERSIONE -> valore che specifica la variabilità di un insieme di dati grezzi.
Nel caso di dati qualitativi misurati su scala nominale o ordinale si ha la possibilità di stimare solamente l’indicatore di tendenza centrale (i.e., MODA e MEDIANA).
NON vi è la possibilità di ottenere un indicatore capace di riassumere efficacemente la variabilità dei dati.
Per i dati qualitativi rilevati su scala NOMINALE, il cui unico indice di tendenza centrale è la MODA, non si ha possibilità di quantificare la dispersione perché i dati non variano. Infatti i numeri sono semplici etichette per identificare una categoria, non rappresentano valori in senso stretto.
Anche nel caso di dati qualitativi misurati su scala ORDINALE non si può parlare di valori nel senso proprio del termine. Anche in questo caso i numeri sono etichette che identificano delle categorie ordinate (NON indicano una quantità).
Per quanto riguarda la dispersione si può, nel caso di dati su scala ORDINALE, usare un parametro solamente descrittivo, capace di indicare la posizione che un «valore» occupa all’interno di una distribuzione di frequenza.
Tale parametro è definito INDICATORE DI POSIZIONE.
L’indicatore di tendenza centrale più efficace per riassumere dati su scala ORDINALE è la MEDIANA.
La MEDIANA altro non è che l’indicatore di posizione più rappresentativo dei dati su scala ORDINALE, poiché permette di dividere in due parti uguali la distribuzione.
Accanto alla Me, esistono altri indicatori di posizione, calcolati in maniera analoga, che possono fornire un’idea della variabilità dei dati, ma NON possono rappresentarla sinteticamente.
Per conoscere la posizione che un valore di una variabile occupa all’interno di una distribuzione di frequenza si utilizzano i QUANTILI che si dividono in
Quartili
Decili
Percentili
Questi indici richiedono che la variabile sia misurata ALMENO su una scala ordinale (può essere superiore) poiché necessitano di una distribuzione ordinata di frequenza.
Quartili
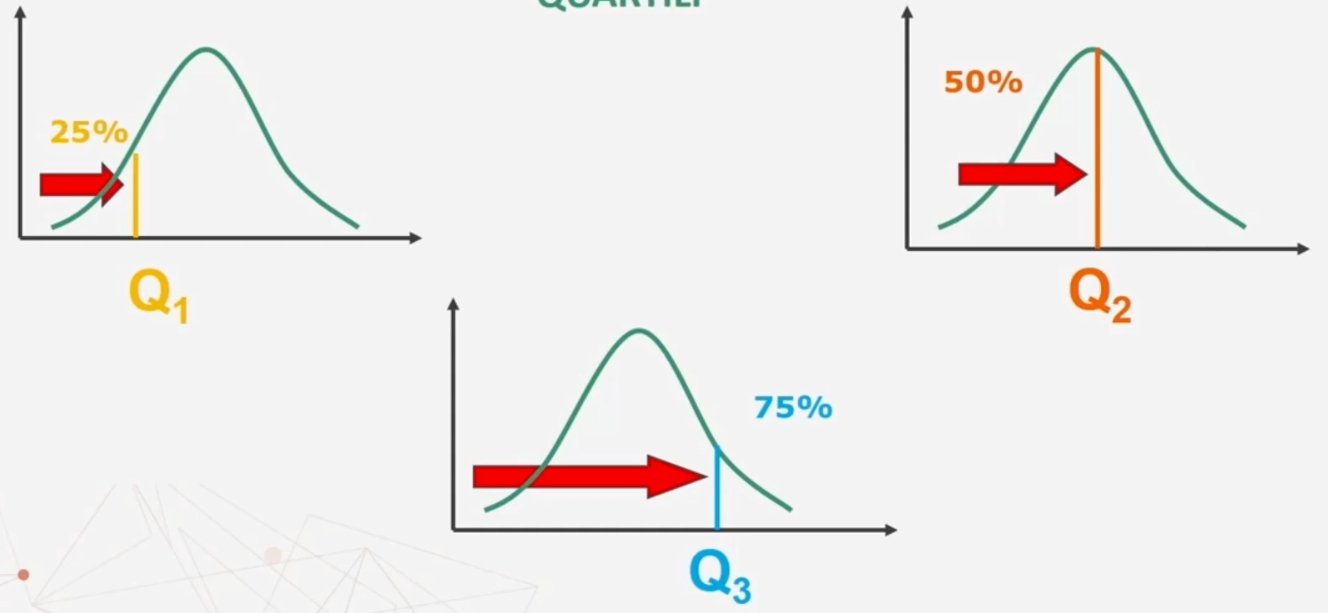
I quartili sono i valori in corrispondenza dei quali la distribuzione viene suddivisa in quattro parti uguali. I quartili sono tre:
1° quartile Q1 (o inferiore): valore al di sotto del quale ricade il 25% dei casi.
2° quartile Q2 (o mediano): valore al di sotto del quale ricade il 50% dei casi.
3° quartile Q3 (o superiore): valore al di sotto del quale ricade il 75% dei casi.
Come si rintracciano?
Si ordinano in senso crescente le modalità o i valori della variabile.
Si calcolano le frequenze cumulate.
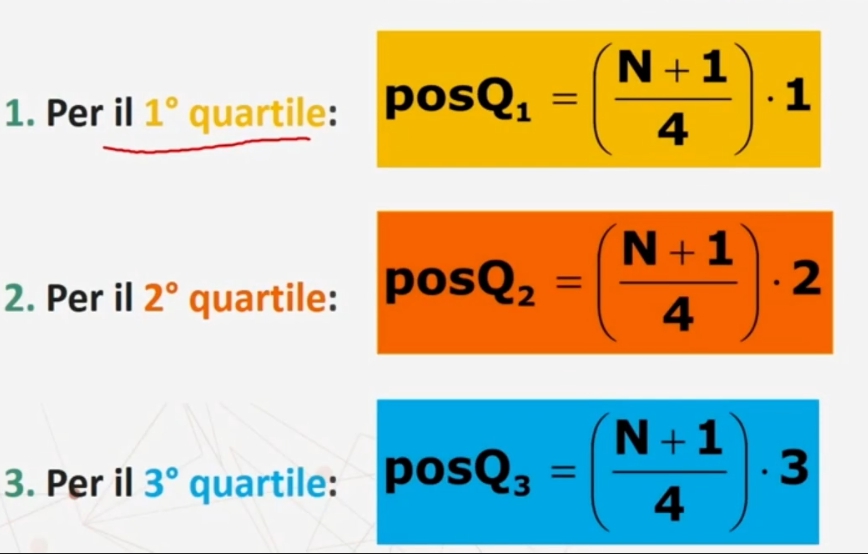
Si calcola la posizione del quartile con le apposite formule.
Si cerca nella distribuzione il valore corrispondente alla posizione trovata.
Le formule per il calcolo della posizione sono le seguenti
Nota bene: Il secondo quartile Q2 corrisponde alla Mediana. La Mediana è un indice di tendenza centrale e di posizione.
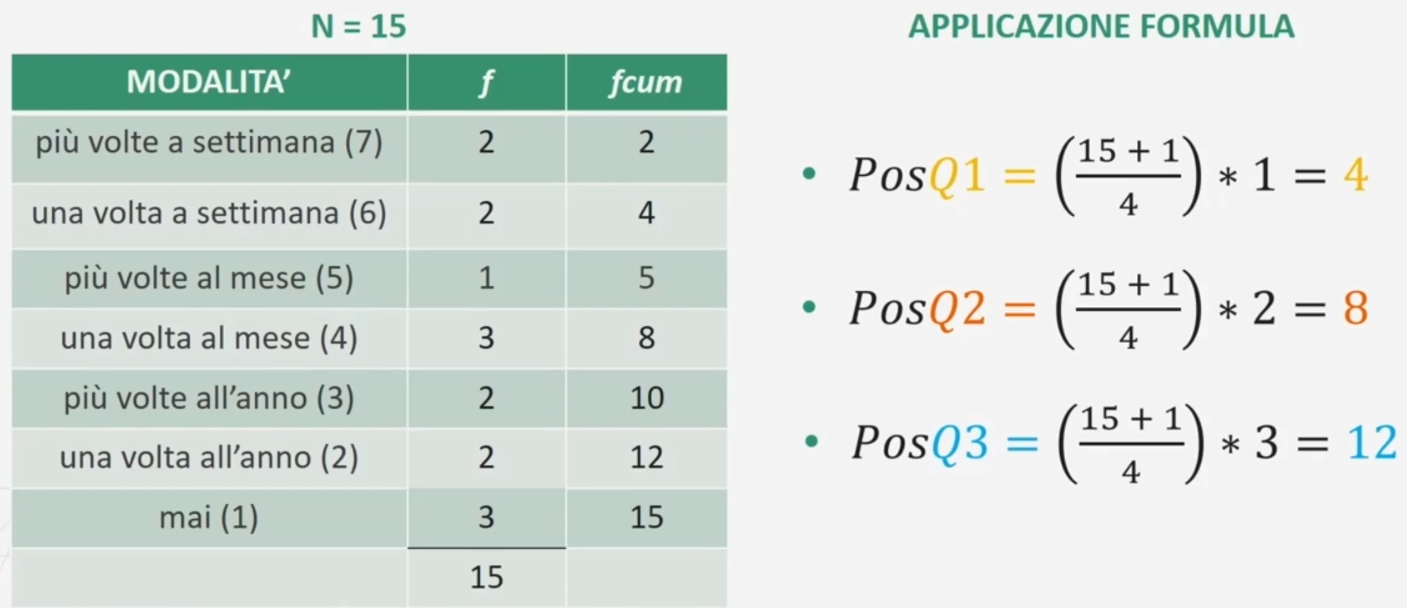
Proviamo a fare un esempio. Supponiamo di avere le risposte di N = 15 (numero di casi dispari) partecipanti ad una domanda riguardante quanto spesso vai al cinema (ordinate rispecchiando una scala di risposta a 7 punti):
7 = più volte a settimana
1 = mai
2 = una volta all’anno
3 = più volte all’anno
4 = una volta al mese
5 = più volte al mese
6 = una volta a settimana
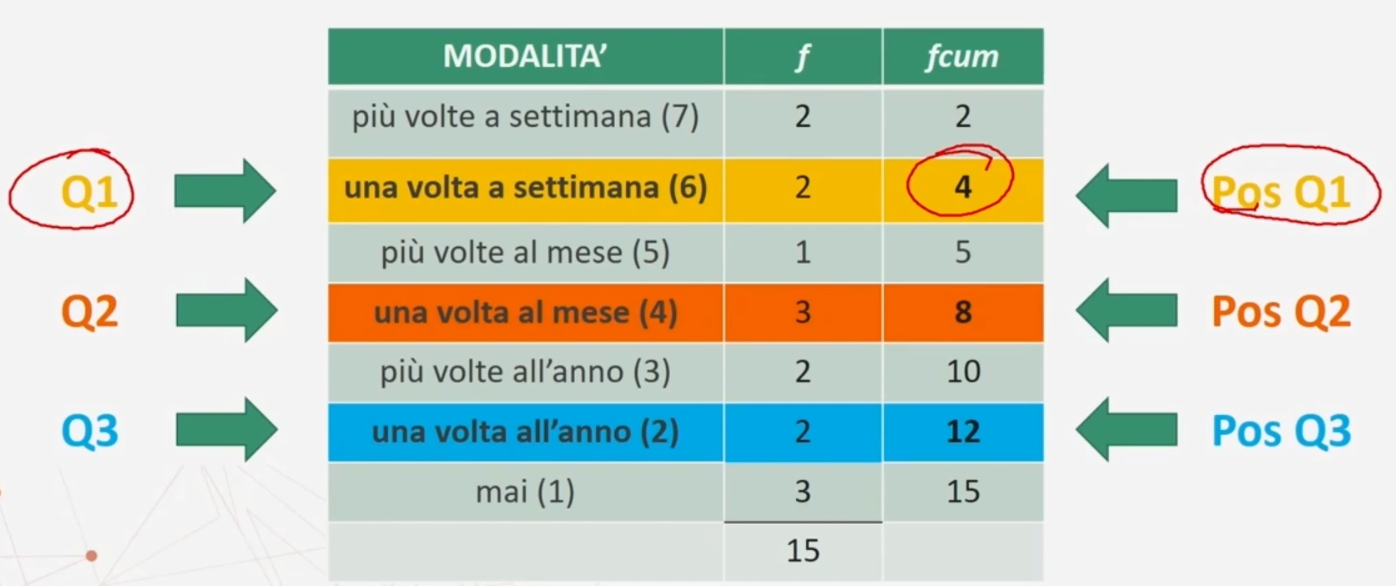
Abbiamo i seguenti quartili
Il primo quartile è 6 «una volta a settimana» (occupa la 4° posizione nella distribuzione).
Il secondo quartile è 4 «una volta al mese» (occupa la 8° posizione nella distribuzione).
Il terzo quartile è 2 «una volta all’anno» (occupa la 12° posizione nella distribuzione).
Decili
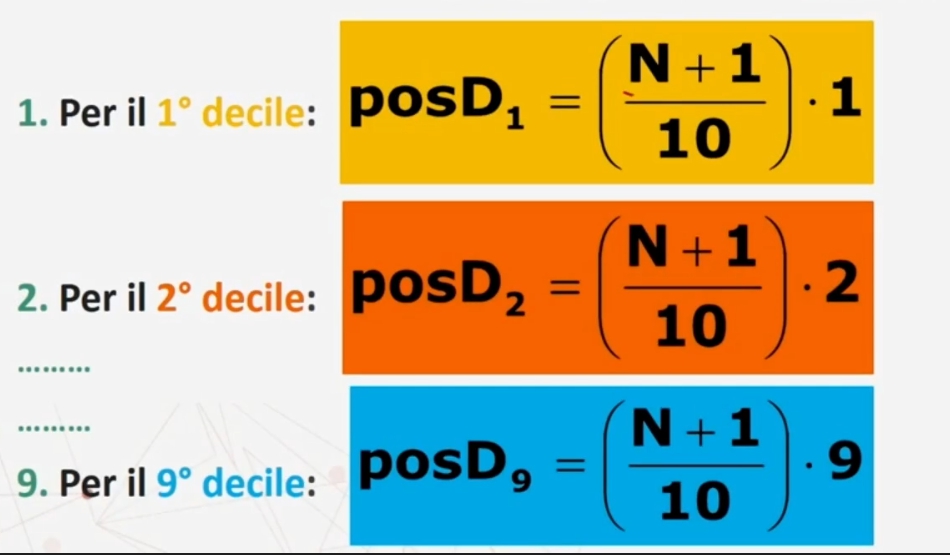
I decili, in maniera analoga ai quartili, sono i valori in corrispondenza dei quali la distribuzione viene suddivisa in dieci parti eguali. I decili sono nove
1° decile D₁: valore sotto il quale ricade il 10% dei casi
2° decile D₂: valore sotto il quale ricade il 20% dei casi
eccetera ….
9° decile D₉: valore sotto il quale ricade il 90% dei casi
COME SI RINTRACCIANO:
Si ordinano in senso crescente le modalità o i valori della variabile
Si calcolano le frequenze cumulate
Si calcola la posizione del decile con le apposite formule
Si cerca nella distribuzione il valore corrispondente alla posizione trovata
Proviamo a fare un esempio più concreto:
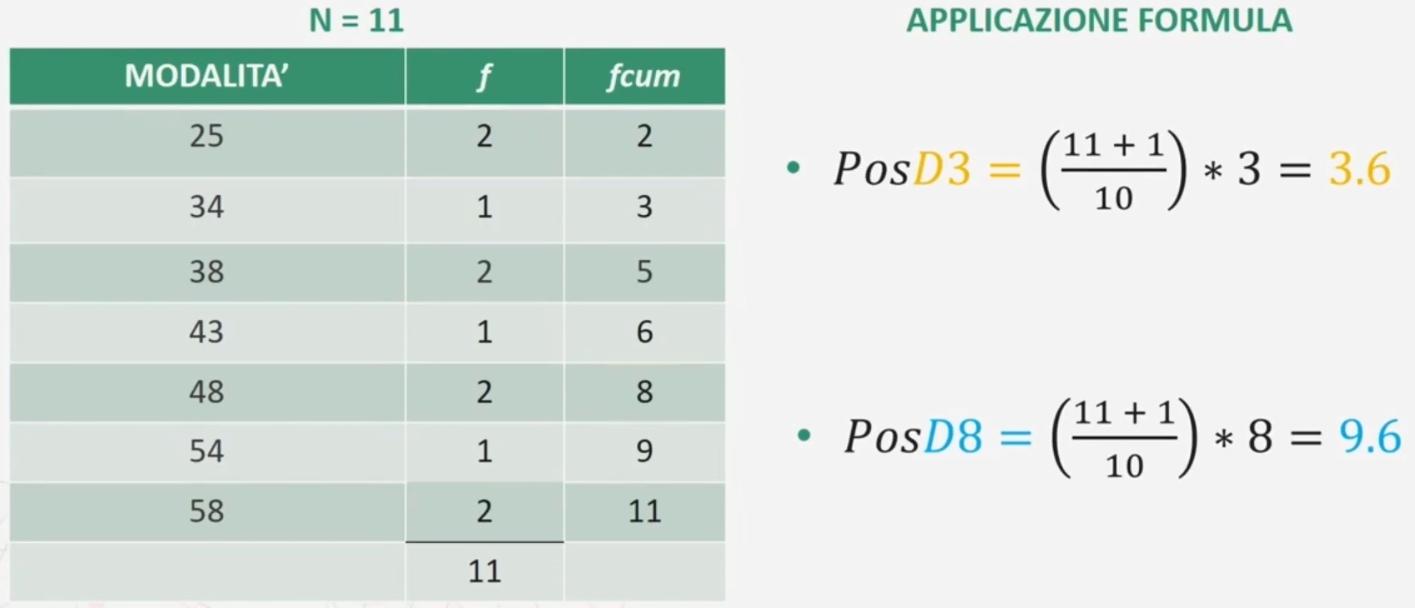
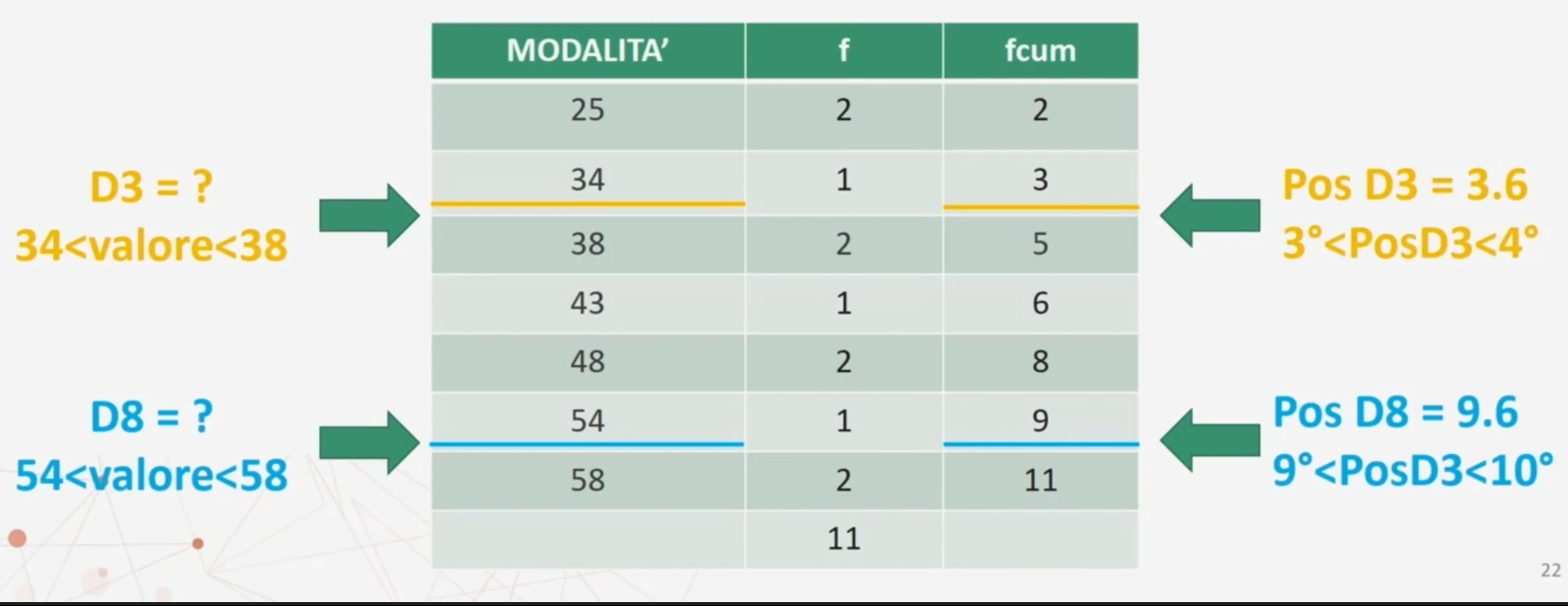
Abiamo 11 bambini di 36 mesi che hanno ottenuto ad un test sul linguaggio la seguente serie di punteggi: 25 43 34 58 25 48 38 38 54 48 58
Trovare il 3° e l’ 8° decile…
Per ottenere i valori associati ai decili si procede così
Si moltiplica la differenza tra i due valori 34 e 38 per la quantità che eccede dalla 3° posizione: 3.6 – 3 = 0.6 → (38-34) x 0.6 = 2.4
Si somma questa quantità al valore corrispondente alla 3° posizione: 34 + 2.4 = 36.4 terzo decile
Si moltiplica la differenza tra i due valori 58 e 54 per la quantità che eccede dalla 9ª posizione: 9.6 – 9 = 0.6 → (58-54) x 0.6 = 2.4.
Si somma questa quantità al valore corrispondente alla 9ª posizione: 54 + 2.4 = 56.4 Ottavo decile
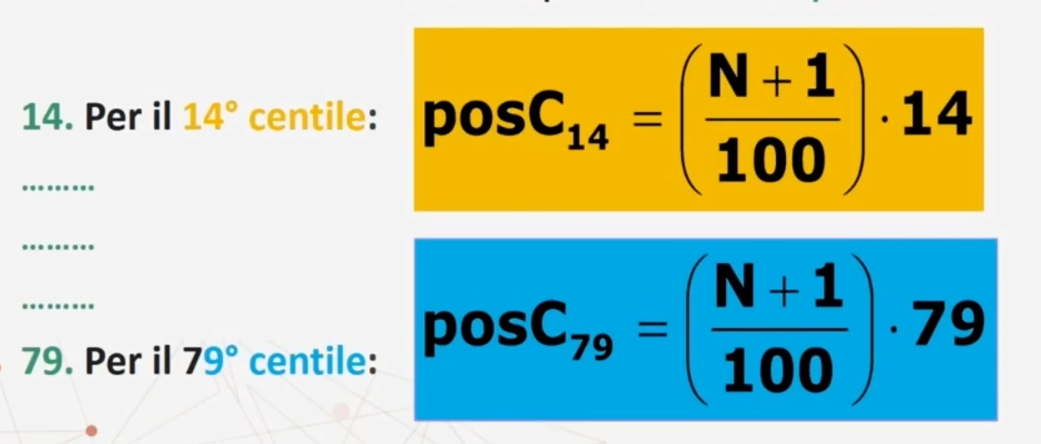
Centili
Sono i valori in corrispondenza dei quali la distribuzione viene suddivisa in cento parti eguali. I centili sono novantanove
15° centile C₁₅: valore sotto il quale ricade il 15% dei casi
45° centile C₄₅: valore sotto il quale ricade il 45% dei casi
99° centile C₉₉: valore sotto il quale ricade il 99% dei casi
COME SI RINTRACCIANO:
Si ordinano in senso crescente le modalità o i valori della variabile
Si calcolano le frequenze cumulate
Si calcola la posizione del centile con le apposite formule
Si cerca nella distribuzione il valore corrispondente alla posizione trovata
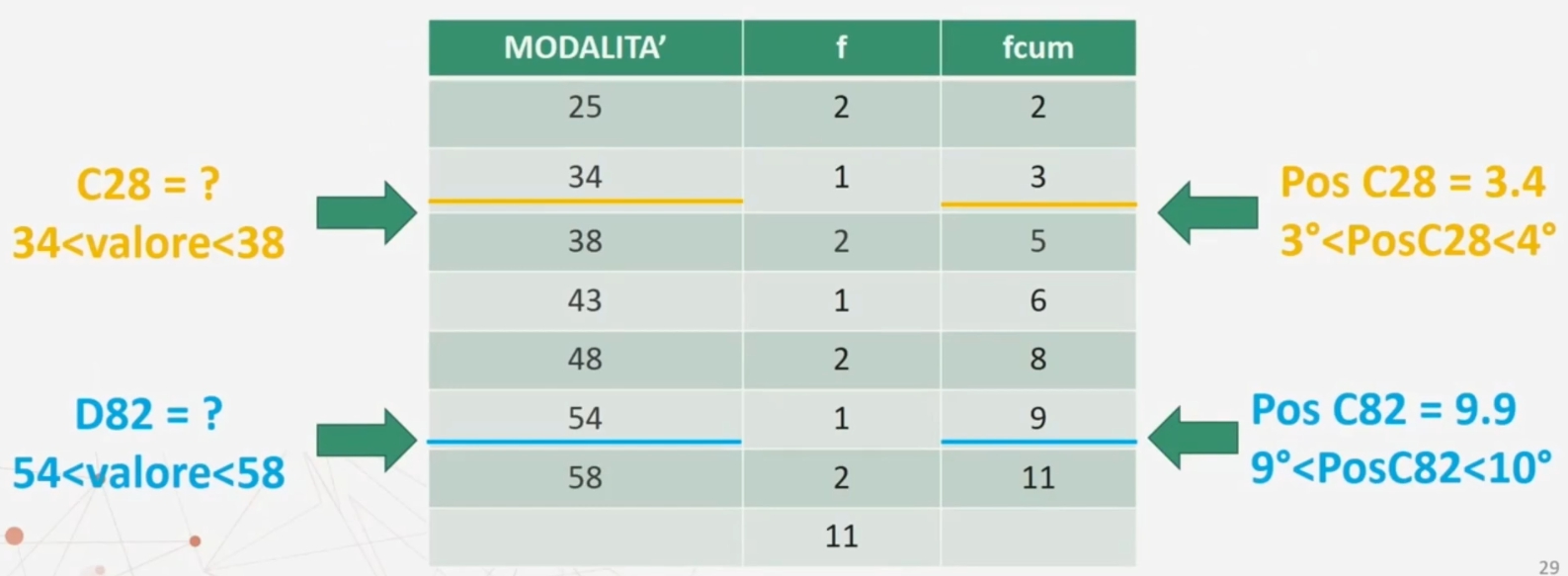
Proviamo a fare un esempio più concreto: abbiamo 11 bambini di 36 mesi hanno ottenuto ad un test sul linguaggio la seguente serie di punteggi: 25 43 34 58 25 48 38 38 54 48 58. Trovare il 28° e l’ 82° centile…
Si procede come prima:
Si moltiplica la differenza tra i due valori 34 e 38 per la quantità che eccede dalla 3° posizione: 3.4 – 3 = 0.4 → (38-34) x 0.4 = 1.6
Si somma questa quantità al valore corrispondente alla 3° posizione: 34 + 1.6 = 35.6 che è il valore del VENTOTTESIMO CENTILE
Si moltiplica la differenza tra i due valori 58 e 54 per la quantità che eccede dalla 9° posizione: 9.9 – 9 = 0.9 → (58-54) x 0.9 = 3.6
Si somma questa quantità al valore corrispondente alla 9ª posizione: 54 + 3.6 = 57.6 valore del OTTANTADUESIMO CENTILE
Ogiva
L’ogiva è la rappresentazione grafica per il calcolo di quartili, decili e centili. L’ogiva è la rappresentazione grafica delle frequenze cumulate
Sull’ASSE delle ASCISSE si riportano i VALORI assunti da una VARIABILE.
Sull’ASSE delle ORDINATE si riportano le FREQUENZE CUMULATE.
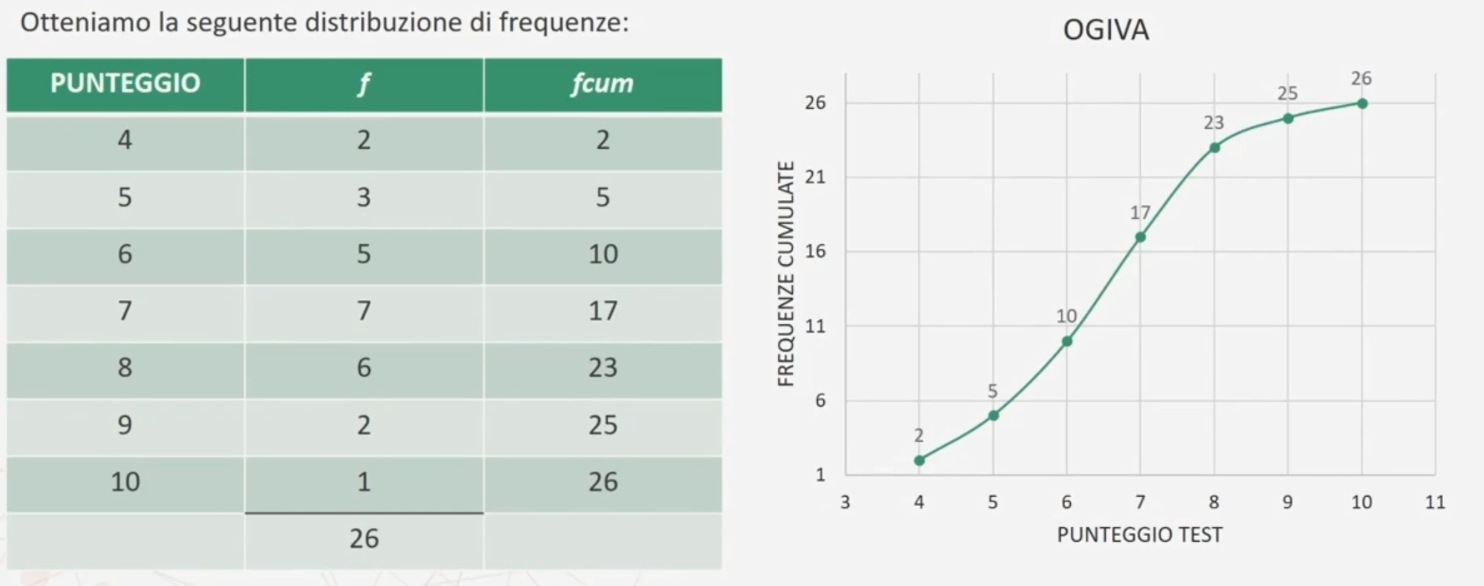
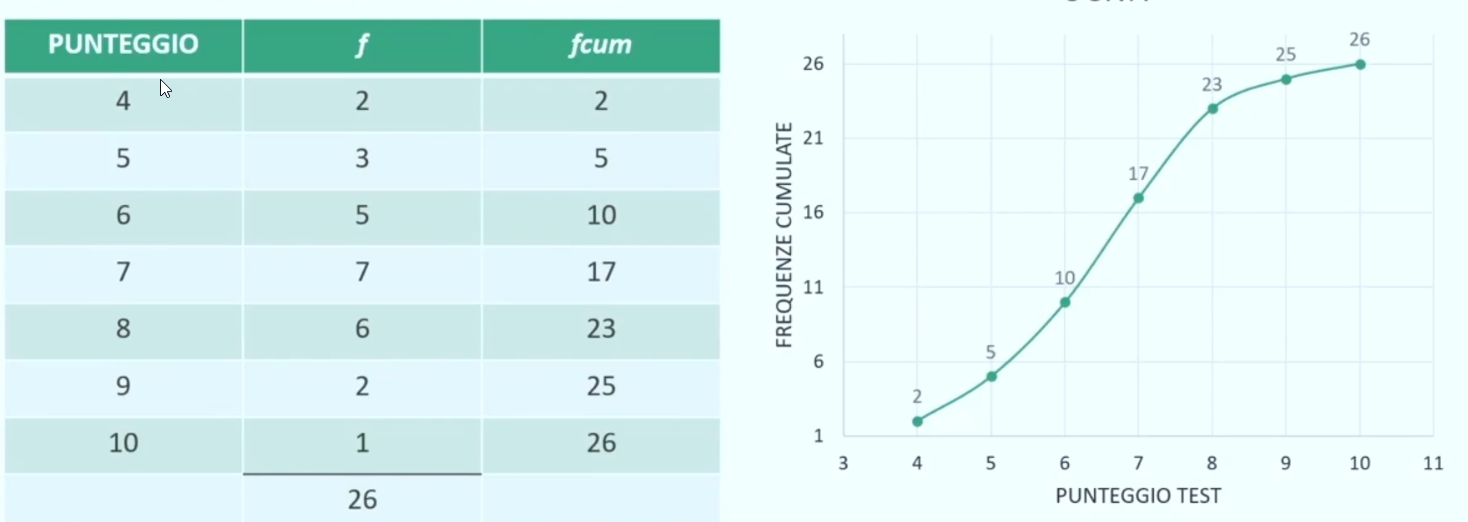
Esempio: Poniamo il caso di aver misurato i punteggi ottenuti su un test di abilità verbali di 26 bambini di un asilo nido. Abbiamo la seguente rappresentazione.
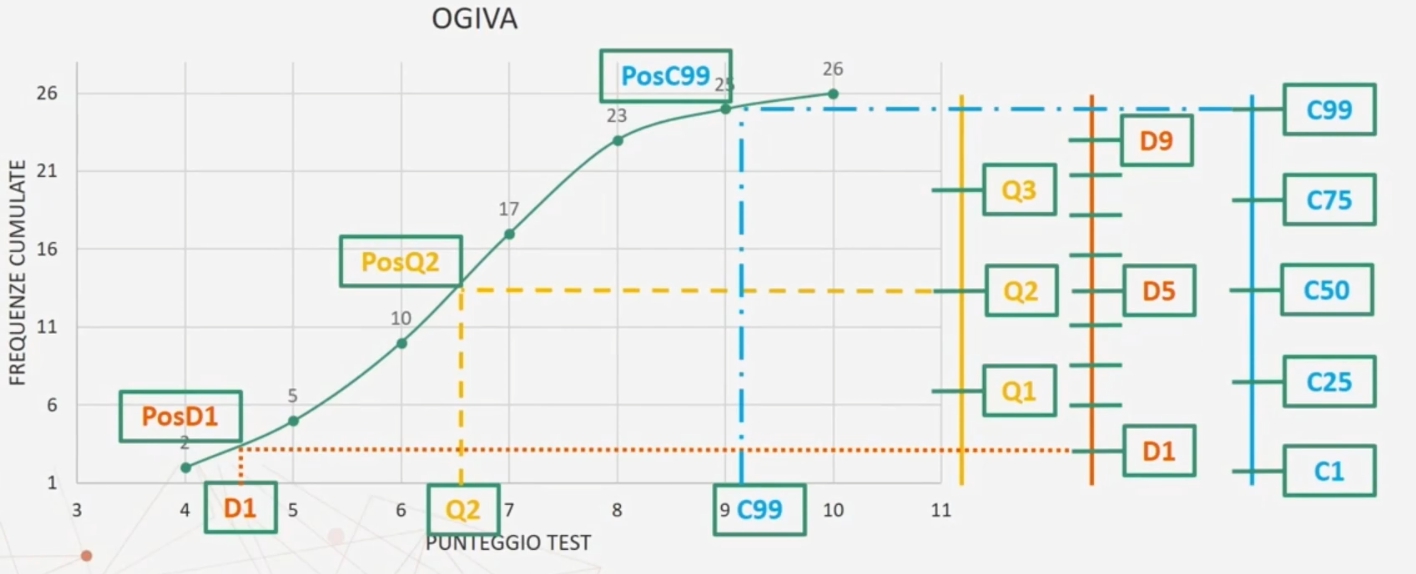
Se volessi ottenere una raprpesentazione grafica per il calcolo dei quartili, decili e centili posso tracciare un segmento parallelo all’asse delle ordinate e lo divido per 4, 10, 100.
Otteniamo i punti dell’asse che corrispondono rispettivamente ai quartili, decili, centili.
Si noti accanto alla curca le righe verticali parelle alla ascissa delle ordinate, e la divisione di queste in 4, 10, e 100 (righe verticali colorate in giallo, rosso, blue). Tracciando una linea orizzontale che parte da queste rette e che tocca il grafico ottengo il valore corrispondente
Il ricercatore è interessato allo studio di fenomeni che variano. Proprio questa variabilità consente di stabilire dei nessi e di formulare ipotesi.
A tal fine, è necessario identificare parametri che sono capaci di riassumere la variabilità dei dati grezzi e descrivere l’oggetto di ricerca.
I due parametri fondamentali che consentono di sintetizzare i dati sono:
INDICATORE DI TENDENZA CENTRALE → valore che rappresenta un insieme dei dati grezzi.
INDICATORE DI DISPERSIONE → valore che specifica la variabilità di un insieme di dati grezzi.
Ad esempio, potremmo essere interessati a confrontare la prestazione complessiva di due diversi gruppi ad una medesima prova. In questo caso sarebbe utile disporre di un valore o parametro capace di rappresentare la prestazione complessiva fornita da ciascun gruppo.
Tale valore o parametro è definito INDICATORE DI TENDENZA CENTRALE.
Il valore o parametro maggiormente adeguato per descrivere l’insieme di dati grezzi sarà diverso in funzione della scala di misura attraverso cui sono stati rilevati i dati (cioè, scala nominale, ordinale, a intervalli o rapporti equivalenti). A ciascuna scala di misura corrisponde un INDICATORE DI TENDENZA CENTRALE capace di rappresentare in modo maggiormente efficace il relativo insieme di dati.
Gli indicatori che consentono di sintetizzare un insieme di dati tramite un unico valore sono tre: moda, mediana e media
Moda
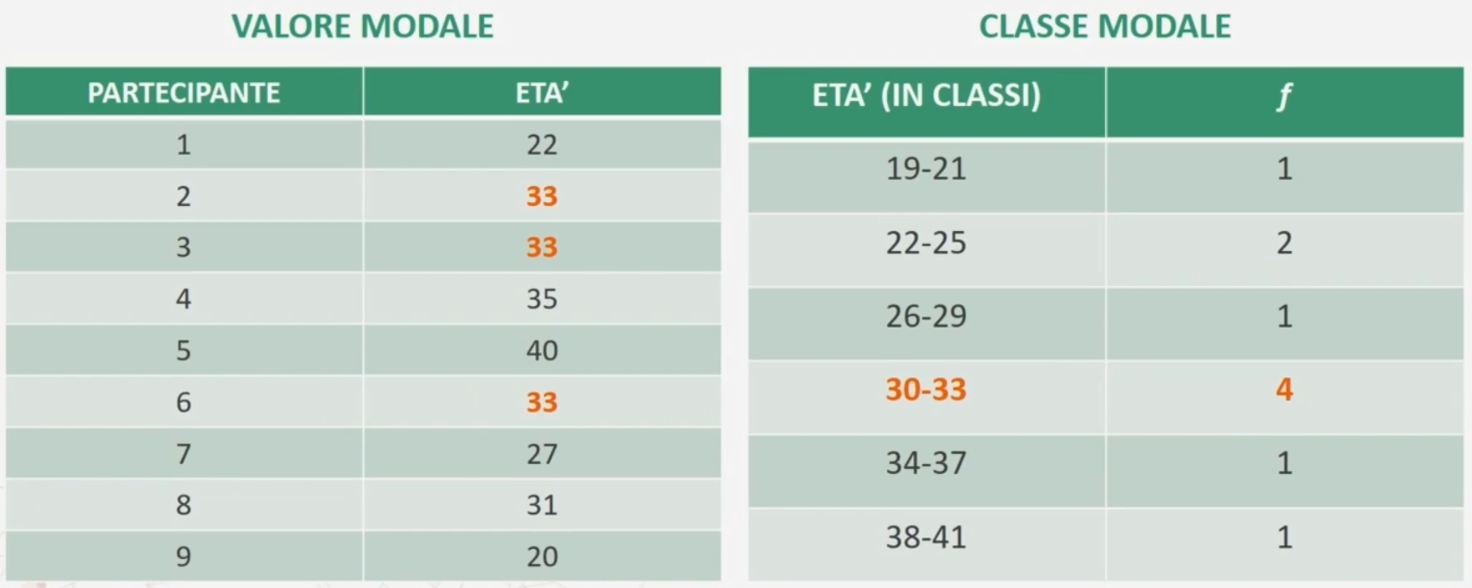
La moda corrisponde alla modalità di una variabile che si presenta con una frequenza maggiore all’interno della distribuzione oggetto di studio. Viene indicata con Mo. Tale modalità è altresì detta valore modale.
Nel caso la distribuzione di frequenza oggetto di studio è in classi si parla di classe modale.
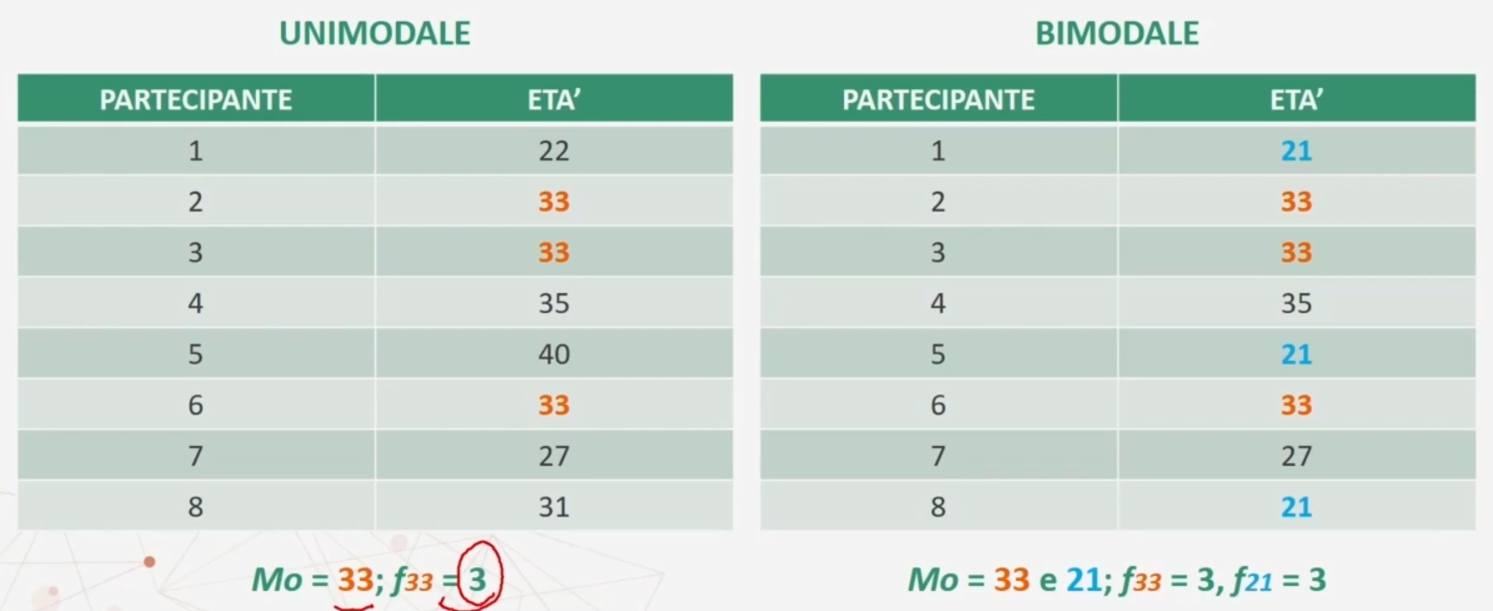
Esempio con moda 33 (valore che si presenta più volte) e classe modale 30-33 (che ha la frequenza maggiore, ovvero 4)
Una distribuzione di frequenza può avere più di un valore o classe modale:
DISTRIBUZIONE UNIMODALE → la moda è definita da un unico valore.
DISTRIBUZIONE BIMODALE → la moda è definita da due valori.
Esempio di una distribuzione unimodale e bimodale. Nel primo caso la moda è 33. Nel secondo caso la moda è composta due valori, 33 e 21. In entrambi i casi ho frequenza 3 (la più alta).
La moda può essere ottenuta con dati rilevati con tutte le scale di misura (cioè, nominale ordinale, a intervalli o rapporti). Tuttavia, è l’unico indicatore di tendenza centrale che può essere utilizzato per i dati qualitativi, misurati su scala nominale.
Rappresenta un indice puramente descrittivo, poco informativo, poco duttile e ambiguo. Per queste caratteristiche è generalmente poco utilizzato.
Mediana
La MEDIANA corrisponde alla modalità di una variabile che occupa la POSIZIONE CENTRALE in una distribuzione ordinata.
È il valore al di sopra o al di sotto del quale ricade il 50% dei casi (o un uguale numero di casi).
In altre parole, è quel valore che divide la distribuzione in due parti uguali.
Viene indicata con Me o Mdn.
La mediana indica quindi la POSIZIONE CENTRALE (cioè, MEDIANA) di una distribuzione ordinata. La posizione della mediana si ottiene con
N rappresenta la somma totale dei casi.
Attraverso la formula, siamo in grado di stabilire in corrispondenza di quale caso otteniamo il valore della mediana.
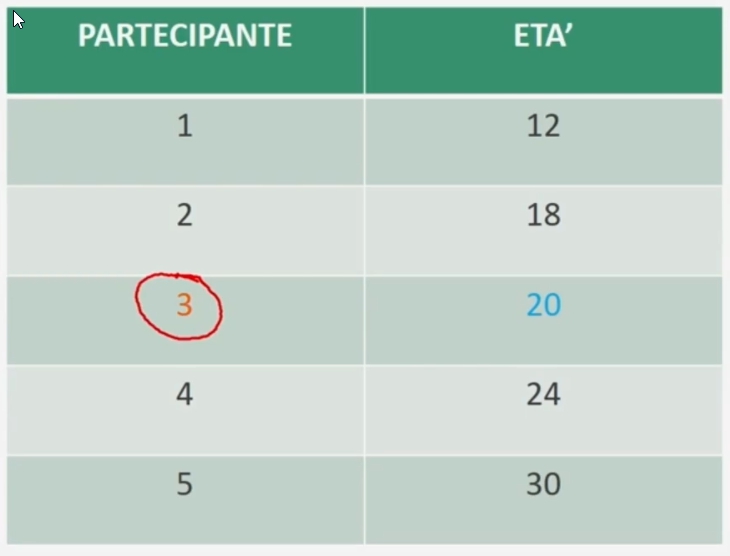
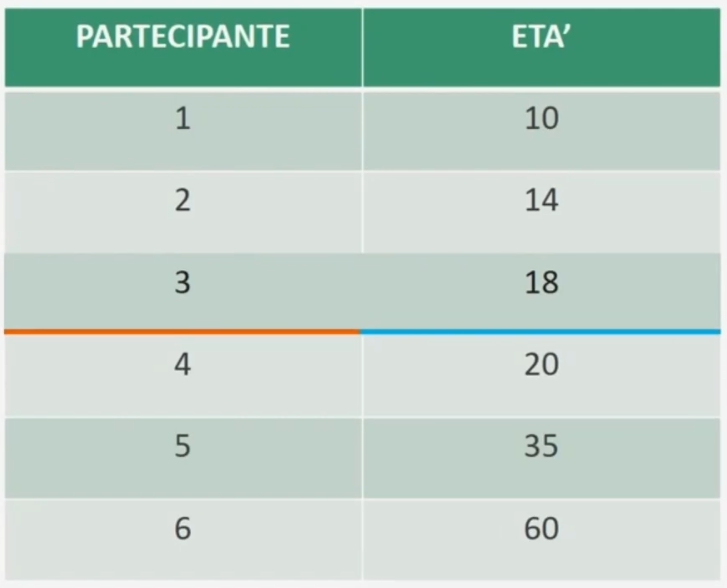
esempio con n=5 dispari: distribuzione di frequenza dell’età di 5 partecipanti. La mediana è rappresentata dal valore corrispondente al caso individuato
La mediana è rappresentata dal valore che occupa la terza posizione.
Vediamo ora un caso con n=6 pari. La mediana NON è direttamente rappresentata dal valore corrispondente al caso individuato. Occorre calcolare la semisomma dei valori intorno al caso individuato
La mediana è rappresentata dal valore che occupa la posizione tra 3 e 4 o 18 e 20.
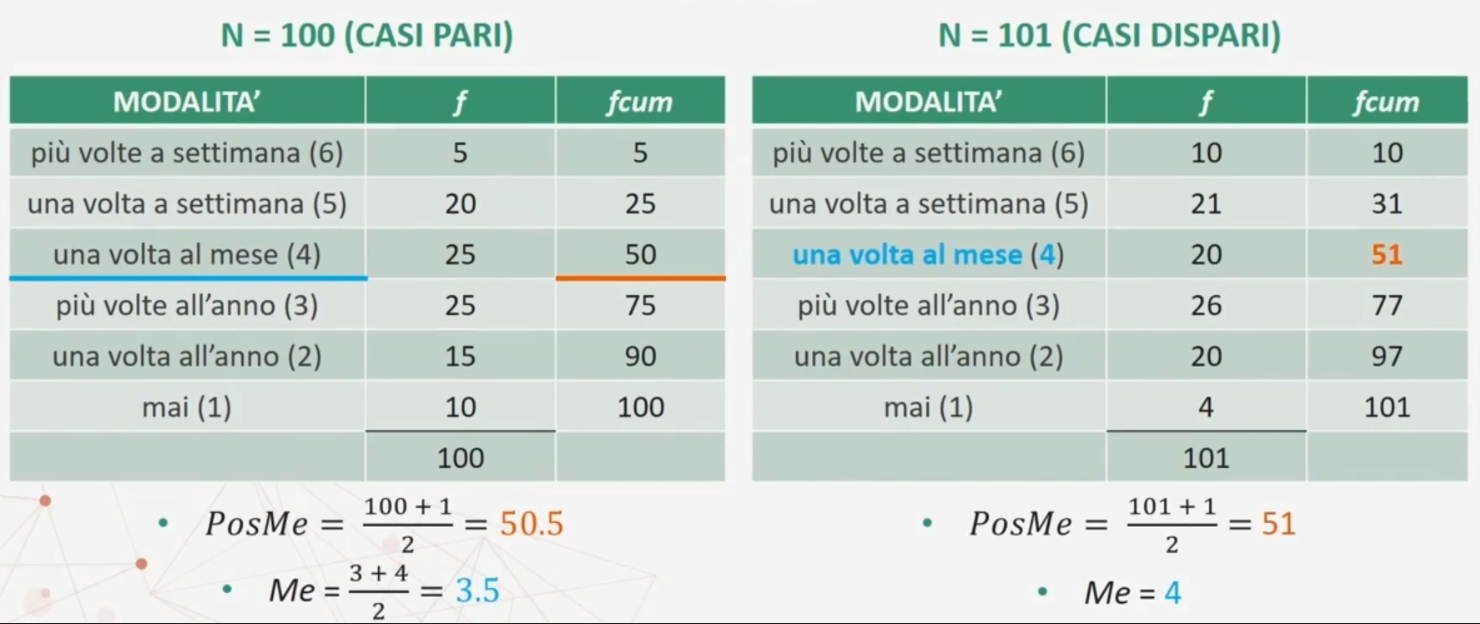
Proviamo a fare un esempio più concreto. Supponiamo di avere le risposte di 100 (Numero di casi pari) e 101 (Numero di casi dispari) partecipanti ad una domanda (“quanto spesso vai al cinema” ordinate secondo una scala di risposta a 6 punti):
6 = più volte a settimana; 5 = una volta a settimana; 4 = una volta al mese; 3 = più volte all’anno; 2 = una volta all’anno; 1 = mai;
Questi sono i dati raccolti
La mediana può essere ottenuta con dati rilevati con scale di misura:
ordinale
a intervalli
a rapporti
La MEDIANA, insieme alla moda, rappresenta l’INDICATORE DI TENDENZA CENTRALE per i dati qualitativi misurati su SCALA ORDINALE.
Media
Il concetto di MEDIA è un concetto comune. Temperatura media di una ragione dell’anno, l’età media di una popolazione, il reddito medio all’interno di una nazione, ecc.
Tutti questi indicatori sono il risultato di una sintesi ed è stata effettuata su un insieme di dati. Ciò che potrebbe essere meno noto, è il procedimento che consente di arrivare a tale indicatore, e soprattutto quali sono le sue caratteristiche indipendenti dall’oggetto che viene misurato.
La MEDIA aritmetica si definisce come la somma delle misure osservate diviso il numero delle osservazioni fatte (totale dei casi).
Viene usualmente indicata con M o con X̄ in relazione al campione.
Quando ci si riferisce alla popolazione si indica con μ.
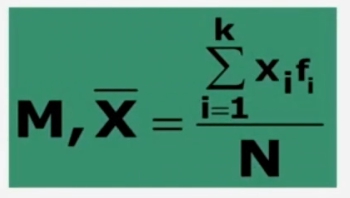
Nel caso di una serie di dati non raggruppati, la media è calcolabile con una semplice formula.
Dove:
Σ = sommatoria
Xi = generica osservazione
N = totale dei casi osservati
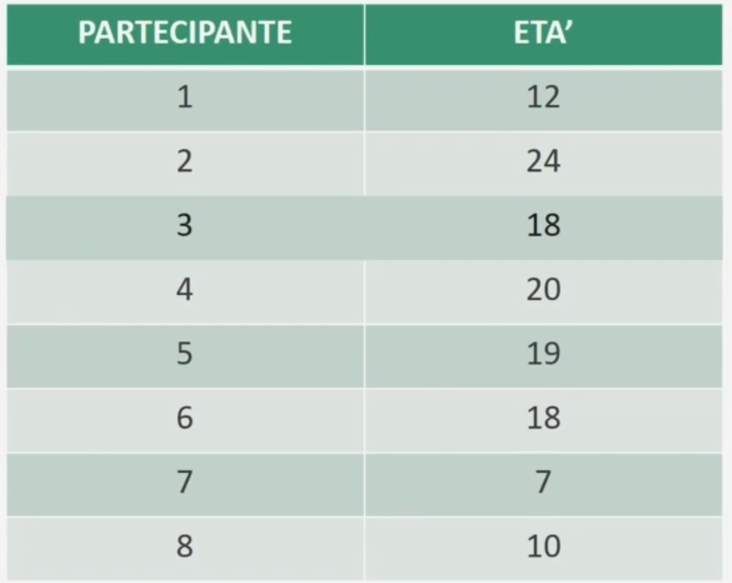
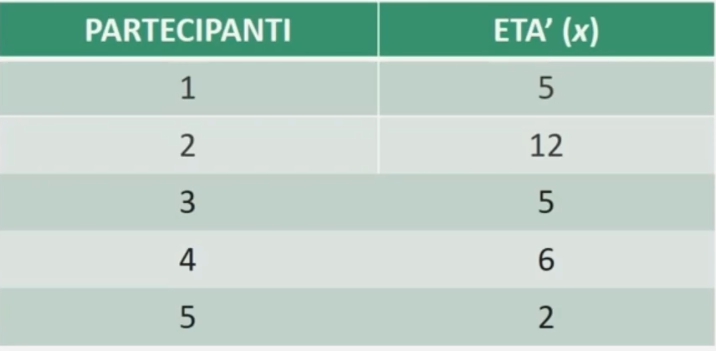
Facciamo un esempio con la media (dati non raggruppati): Proviamo a calcolare l’età media di N = 8 partecipanti.
Per ottenere la media si sommano le 8 età dei partecipanti e si divide per il numero totale dei casi:
Nel caso di una serie di dati organizzati in una distribuzione di frequenza, la media è calcolabile:
Dove:
Σ = sommatoria
Xi = generica osservazione
fi = frequenza associata a ciascun valore
k = numero dei diversi valori (modalità di xi)
N = totale dei casi osservati
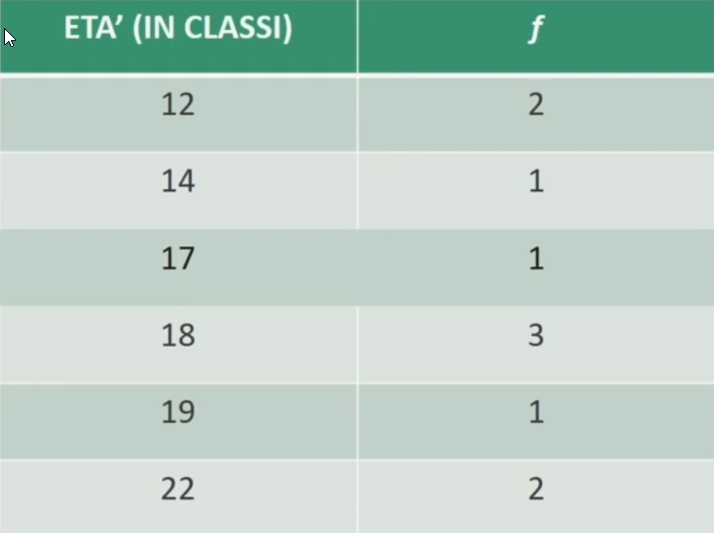
Facendo un esempio proviamo a calcolare l’età media di N = 10 partecipanti.
Per ottenere la media si sommano le 10 età dei partecipanti tenendo conto (moltiplicando) della frequenza in cui si presentano, e poi si divide per il numero totale dei casi:
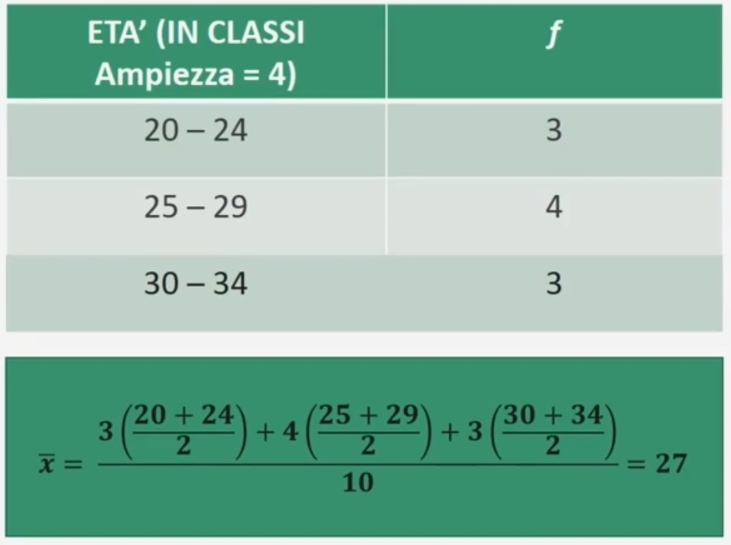
Nel caso di una serie di dati raggruppati in classi di ampiezza > 1, la media è calcolabile:
Dove:
Σ = sommatoria
Xc = punto medio di classe
fc = frequenza associata a ciascun classe
k = numero dei diversi valori (modalità di xi)
N = totale dei casi osservati
Esempio: Proviamo a calcolare l’età media di N = 10 partecipanti.
Per ottenere la media Si moltiplica la frequenza di ogni classe per il valore effettivo del punto medio di classe, prima di fare la somma e dividere per il numero totale dei casi
Proprietà della media
La MEDIA aritmetica ha due importanti proprietà che sono alla base di operazioni statistiche più complesse (es, varianza, deviazione standard, regressione, ecc.):
La somma degli scarti dei singoli valori che compongono la media è sempre uguale a zero.
La somma dei quadrati degli scarti di ciascun valore dalla media è minore della somma degli scarti degli stessi valori da un qualsiasi altro numero (proprietà dei minimi quadrati).
Vediamo la prima proprietà “La somma degli scarti dei singoli valori che compongono la media è sempre uguale a zero.”
Lo scarto è quanto si discosta ciascun valore dalla sua media.
La dimostrazione è verificabile dalle seguenti immagini
Vediamo ora la proprietà “La somma dei quadrati degli scarti di ciascun valore dalla media è minore della somma degli scarti degli stessi valori da un qualsiasi altro numero (proprietà dei minimi quadrati).”
La dimostrazione nella seguente immagine
come si vede 38 > 18 e anche 23 > 18.
In generale possiamo dire che la media può essere ottenuta con dati rilevati con scale di misura:
a intervalli
a rapporti
La MEDIA, insieme alla moda e alla mediana, rappresenta l’INDICATORE DI TENDENZA CENTRALE per i dati quantitativi misurati su SCALE METRICHE.
Confronto tra media e mediana
La MEDIA può essere trattata con il CALCOLO ALGEBRICO, mentre la MEDIANA non può esserlo. Questo comporta che la MEDIA può essere PONDERATA per confrontare campioni con N diverso, mentre la MEDIANA non può.
La MEDIANA varia maggiormente passando da un campione all’altro, mentre la MEDIA è più stabile. Questo comporta che la MEDIA può essere utilizzata per la STATISTICA INFERENZIALE, mentre la MEDIANA non può.
Come vantaggio della mediana abbiamo che la MEDIANA è più stabile rispetto ai VALORI ESTREMI, mentre la MEDIA non lo è, comportando svantaggi e svantaggi a seconda dei casi.
Facciamo i seguenti esempi:
Esempio 1: 4, 6, 8, 9, 11, 12, 12 → Me=9 M=8.8 In questo caso media e mediana sono pressoché identiche.
Esempio 2: 4, 6, 8, 9, 11, 12, 56 → Me=9 M=15.1 In questo caso la mediana è più rappresentativa dei dati.
Esempio 3: 4, 6, 8, 9, 91, 92, 96 → Me=9 M=44.3 In questo caso la media è maggiormente rappresentativa.
Confronto tra moda, media e mediana
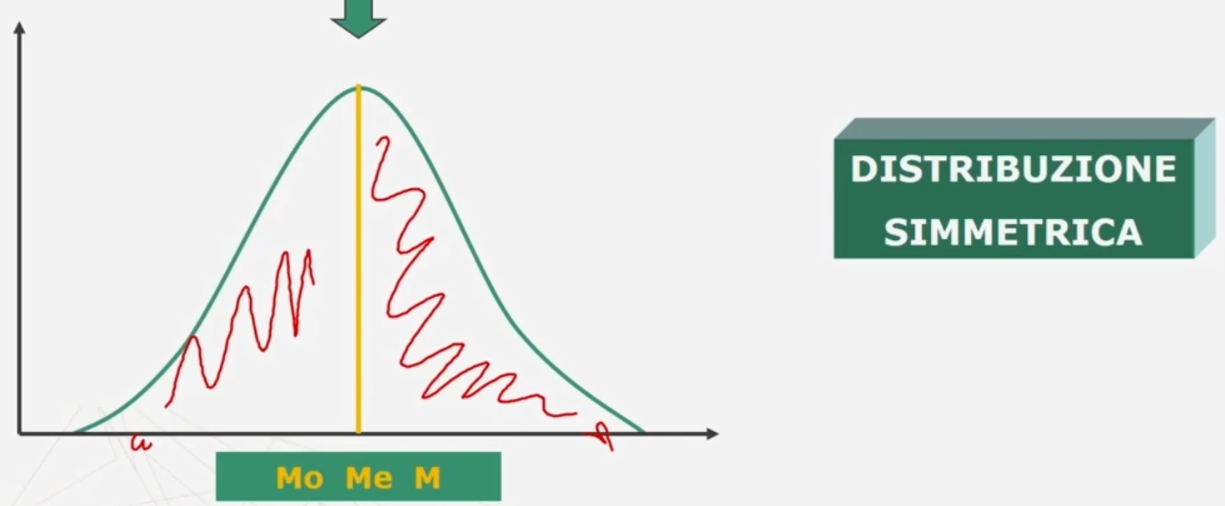
Nel caso di una distribuzione simmetrica media moda e mediana coicidono.
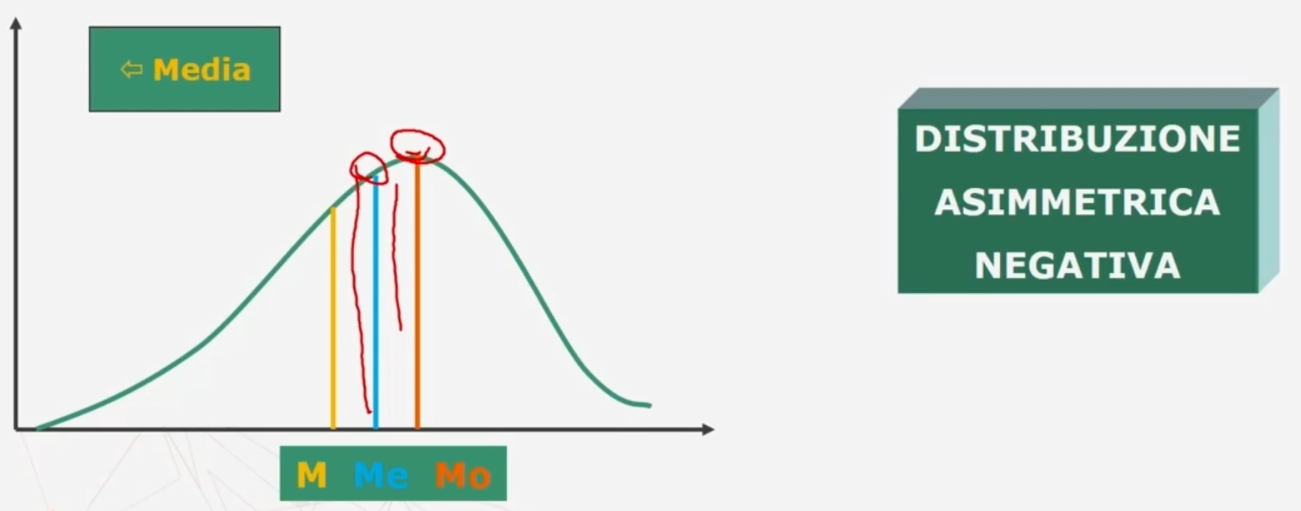
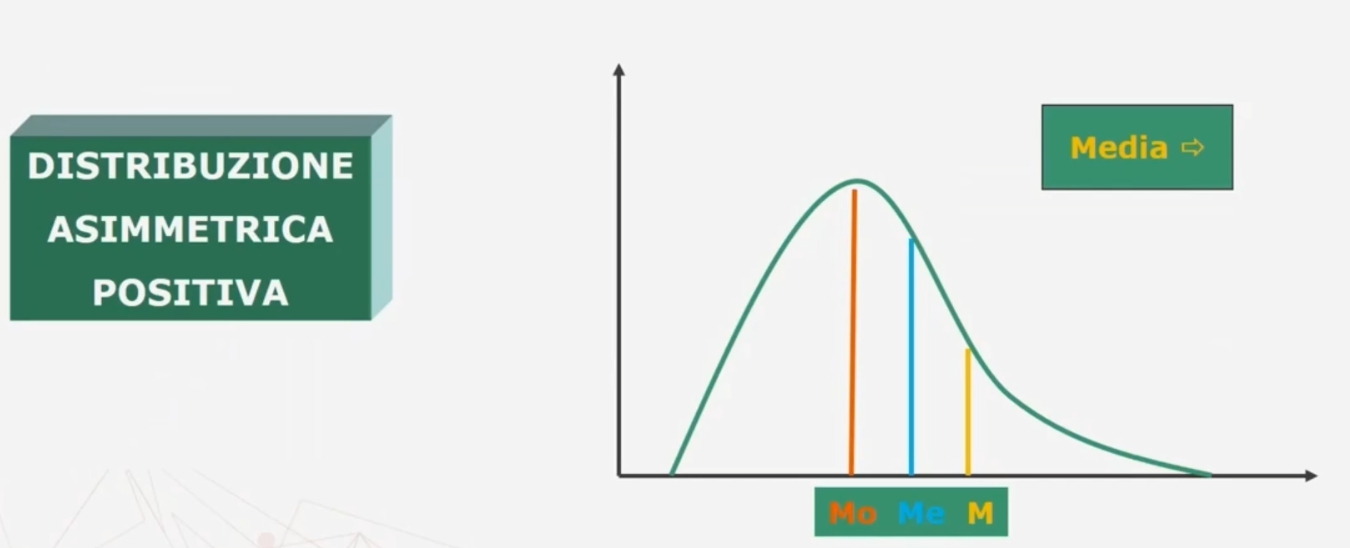
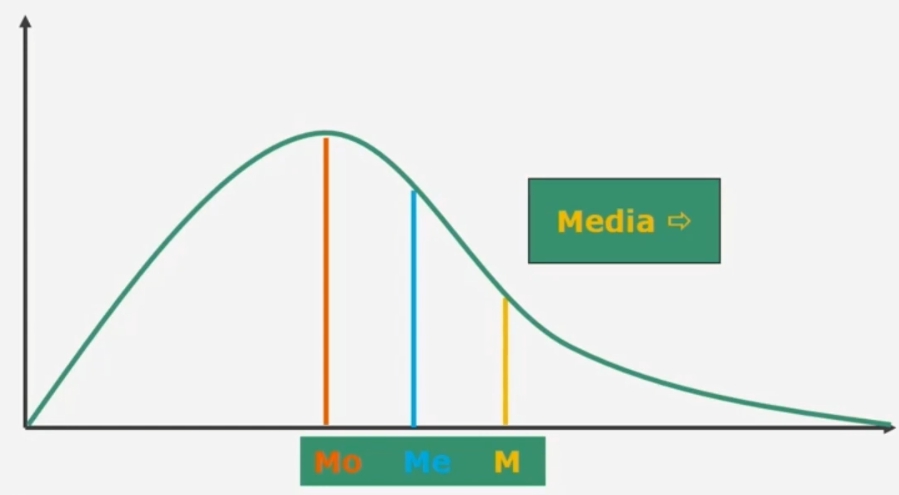
Nel caso di una distribuzione asimmetrica negativa e positiva
Se esiste una forte asimmetria (sia positiva che negativa) è preferibile la mediana alla media (come in questo caso)
Le tabelle di frequenza consentono di raccogliere i dati derivanti dal calcolo delle distribuzioni di frequenza. Possono essere:
TABELLE SEMPLICI
TABELLE A DOPPIA ENTRATA O DI CONTINGENZA
TABELLE A ENTRATA MULTIPLA
Tabelle semplici
Nelle tabelle semplici i dati sono classificati secondo una singola variabile.
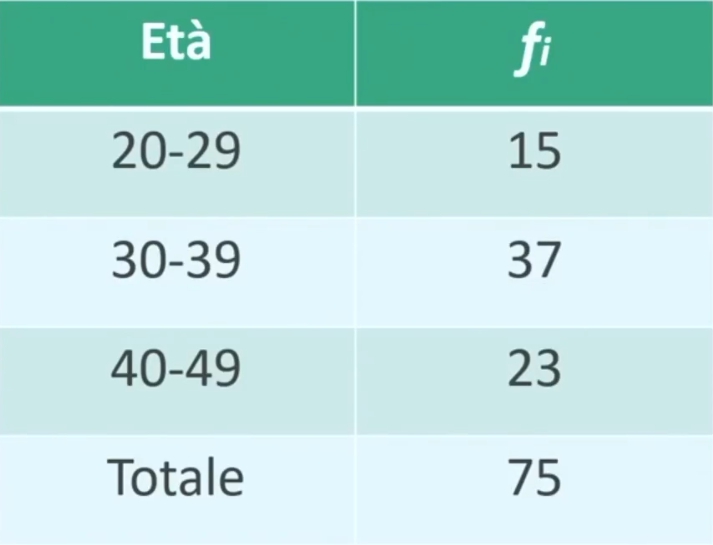
Ad esempio, potremmo essere interessati a raggruppare i partecipanti in funzione di diverse fasce di età.
Otterremo dunque una tabella che riporta le modalità assunte dalla variabile X=età e la relativa distribuzione di frequenza
Tabelle a doppia entrata o di contigenza
Questa viene usata nello studio congiunto di due variabili. I valori sono raggruppati in classi. Ci interessa analizzare come si distribuiscono le frequenze (esempio come il titolo di studio è distribuito in funzione del genere).
A questo scopo occorre costruire la tabella di classificazione a doppia entrata, o tabella di contingenza, composta da
r righe (sono le categorie o classi della prima variabile)
c colonne (sono le categorie o classi della seconda variabile).
All’interno di questa tabella, in ogni cella si trova il valore detto frequenza interne.
Le frequenze totali
sommando i valori per riga sono detti frequenze marginali per riga
sommando i valori in colonna sono detti frequenze marginali per colonna
Esempio:
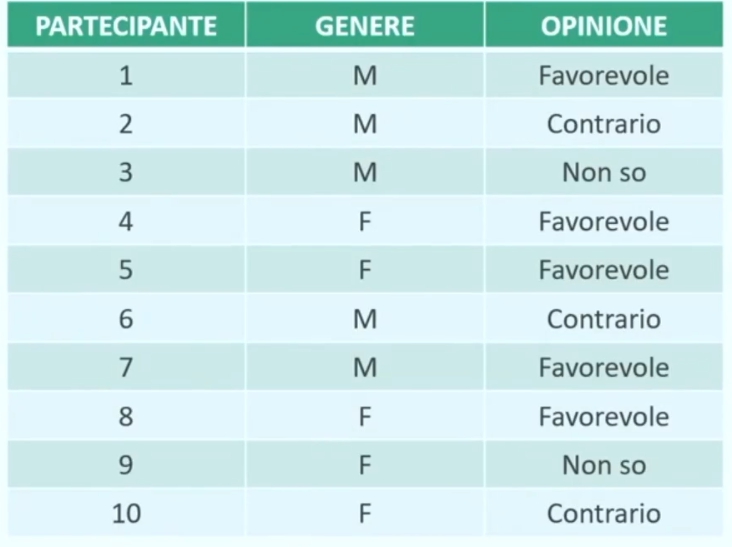
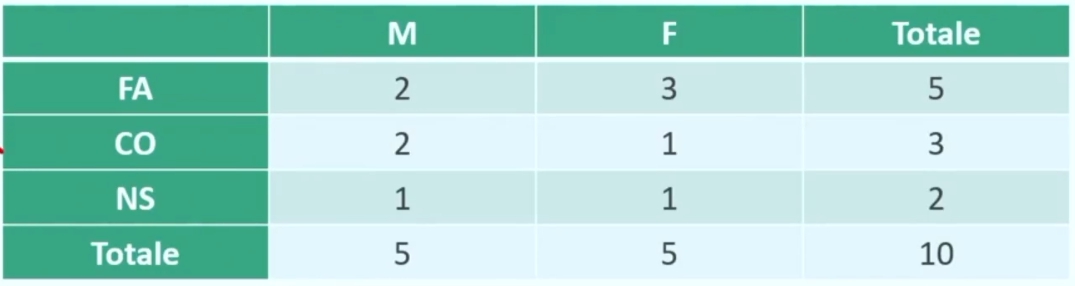
Ho 10 partecipanti (5 maschi e 5 femmine) (prima variabile = GENERE con due categorie M e F), l’opinione circa il divieto di vendere alcolici in discoteca, classificata in FAVOREVOLE, CONTRARIO, NON SO (seconda variabile = OPINIONE con tre categorie FA, CO, NS).
Avremmo dunque il seguente file dati:
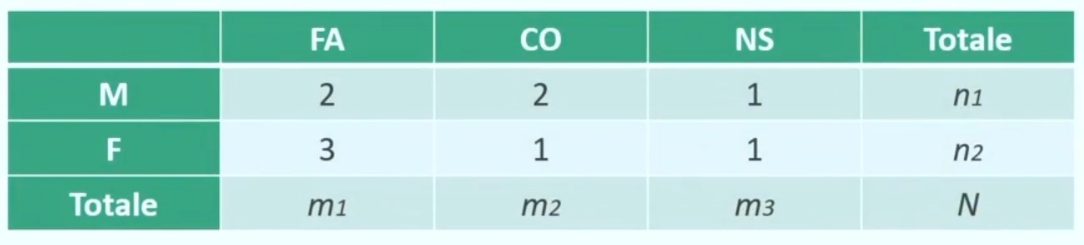
Per vedere come si distribuiscono le opinioni secondo il genere si costruisce una tabella a doppia entrata (2 righe × 3 colonne), dove per riga si mettono le categorie della variabile GENERE (M e F) e per colonna le categorie della variabile OPINIONE (FA, CO e NS).
Nelle 6 celle della tabella si inseriscono le frequenze interne f₁, f₂, f₃, f₄, f₅, f₆
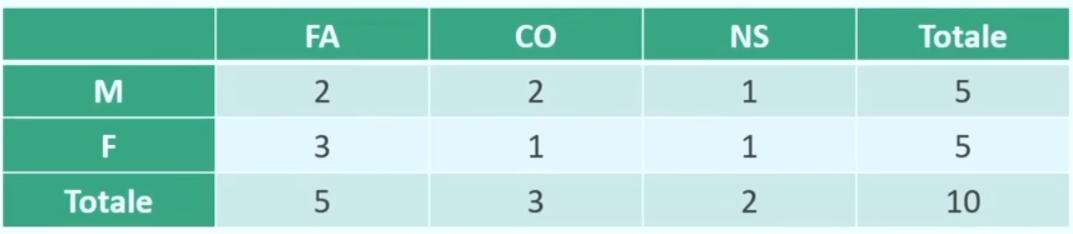
Otteniamo quindi
Indicando con n₁ e n₂ le frequenze marginali per riga, con m₁, m₂, m₃ le frequenze marginali per colonna, e con N il totale generale, possiamo controllare che i «conti» tornino.
l risultato finale è la tabella di contingenza o a doppia entrata:
Naturalmente, è possibile costruire l’analoga tabella (3 × 2), sempre composta da 6 celle, invertendo righe e colonne.
In alcuni casi, le tabelle a doppia entrata consentono di risalire a frequenze ignote (cioè, numero di partecipanti in una data classe) partendo da altre frequenze già note.
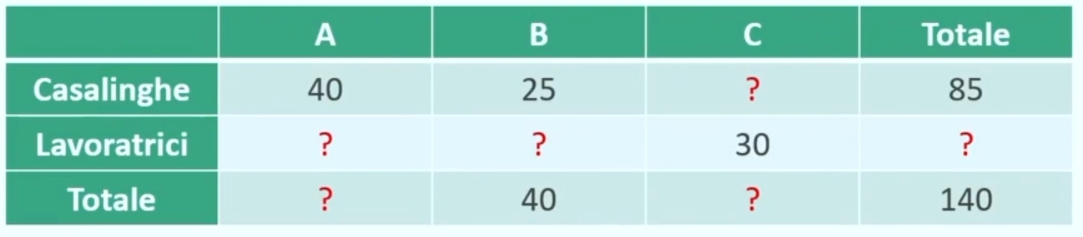
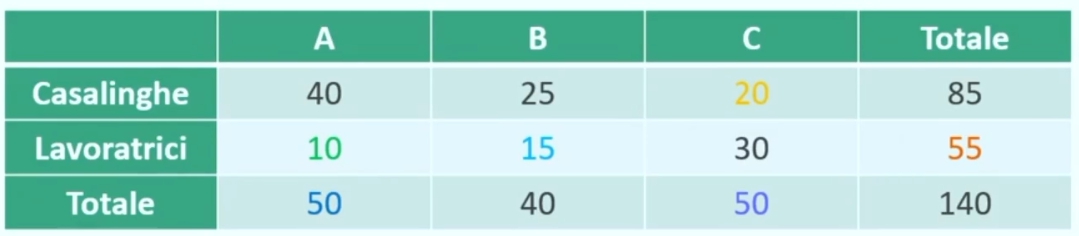
Esempio: Supponiamo di voler studiare come si distribuiscono 140 donne intervistate mettendo in relazione
TITOLO DI STUDIO (3 categorie: A = licenza media; B = diploma; C = laurea)
Sappiamo che, delle 140 donne, 85 sono casalinghe, di cui 40 con titolo di studio A e 25 con titolo di studio B. Tra le lavoratrici 30 sono laureate. Sappiamo inoltre che il totale di donne con titolo di studio B è 40.
Attraverso queste informazioni siamo in grado di costruire la nostra tabella di contingenza (2 × 3).
Attraverso semplici operazioni algebriche, risulta facile andare a completare la tabella inserendo le frequenze mancanti.
In una tabella a doppia entrata, la frequenza interna di ogni cella può essere trasformata in frequenza percentuale per riga, per colonna o totale. La trasformazione da frequenza assoluta (f) a frequenza percentuale (f%) è:
f% = (f × 100) / n
Esempio: prendiamo come esempio la tabella precedente 2 × 3 (occupazione per titolo di studio)
Possiamo calcolare le frequenze percentuali per riga, ottenendo la percentuale di laureate, diplomate e con licenza media tra casalinghe (n = 85), lavoratrici (n = 55) e sul totale del campione (n = 140).
Possiamo anche calcolare le frequenze percentuali per colonna,
Infine possiamo calcolare le frequenze percentuali sul totale
Tabelle a entrata multipla
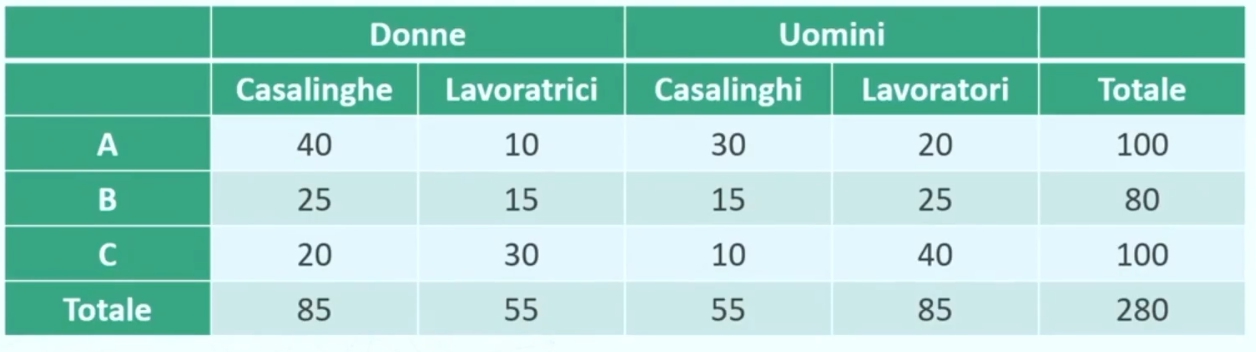
In questo caso i dati sono classificati secondo 3 o più variabili. Le frequenze sono calcolate tenendo presente delle molteplici combinazioni delle modalità delle variabili.
Per esempio aggiungendo il genere (Uomini e donne) all’esempio “Titolo di studio” per occupazione, otterremmo una tabella 3x2x2.
Le rappresentazioni grafiche
Le distribuzioni di frequenza possono essere rappresentate graficamente in vari modi.
Istogramma
L’ISTOGRAMMA è una rappresentazione grafica su due assi cartesiani nella quale si riportano le frequenze in colonne affiancate.
Per quanto riguarda le ORDINATE, posso avere:
Variabili continue con classi di uguale ampiezza: allora ordinata = frequenze → frequenze direttamente proporzionali all’altezza dell’istogramma.
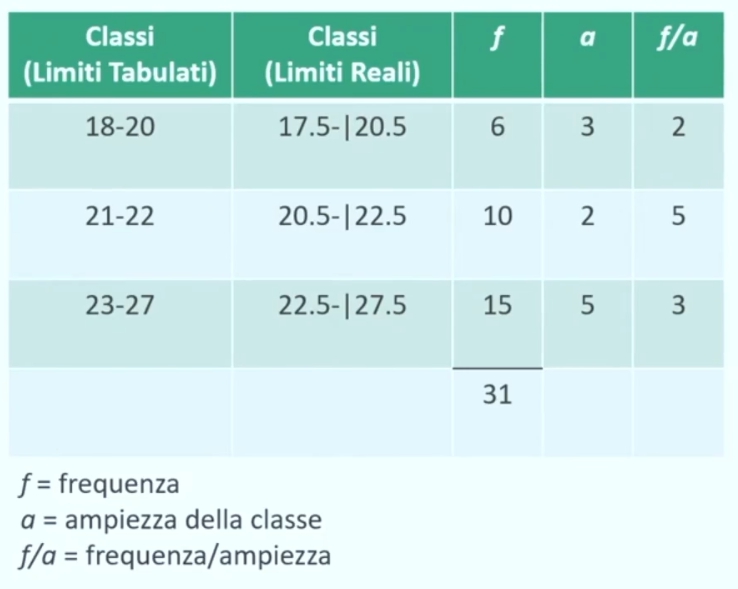
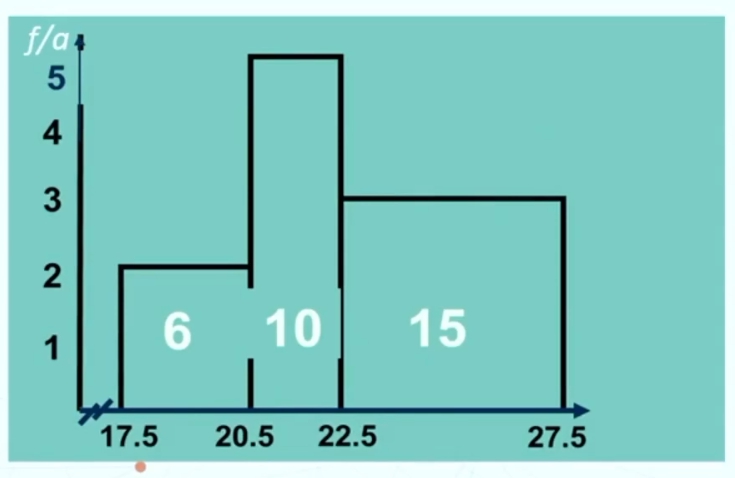
Variabili continue con classi di ampiezza diversa: allora ordinata ≠ frequenze → è necessario calcolare l’altezza del rettangolo attraverso la formula: ordinata = frequenza / ampiezza.
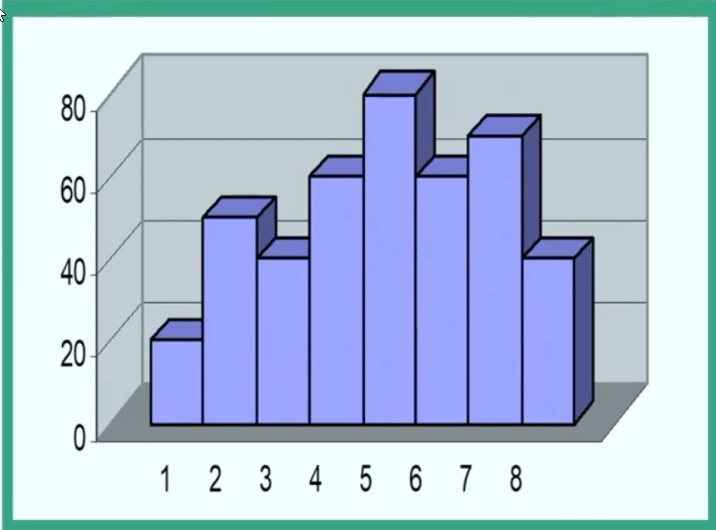
Di seguito esempio con variabile continua e classi di ampiezza unitaria.
Nel caso in cui invece ho una variabile continua con classi di ampiezza diversa allora:
Ascissa: valori della variabile raggruppati in classi di ampiezza diversa. Questa è la base del rettangolo. In soldoni è l’ampiezza della classe.
Ordinata: altezza di ciascun rettangolo ottenuta con la formula frequenza/ampiezza (f/a)
La frequenza è uguale all’area del rettangolo.
Nel caso di VARIABILI NOMINALI sull’asse delle ASCISSE vengono riportate le MODALITÀ che la variabile può assumere.
Le basi dei rettangoli dell’istogramma sono per convenzione di UGUALE AMPIEZZA E NON ADIACENTI. Per quanto riguarda l’asse delle ORDINATE, avremo dunque le FREQUENZE.
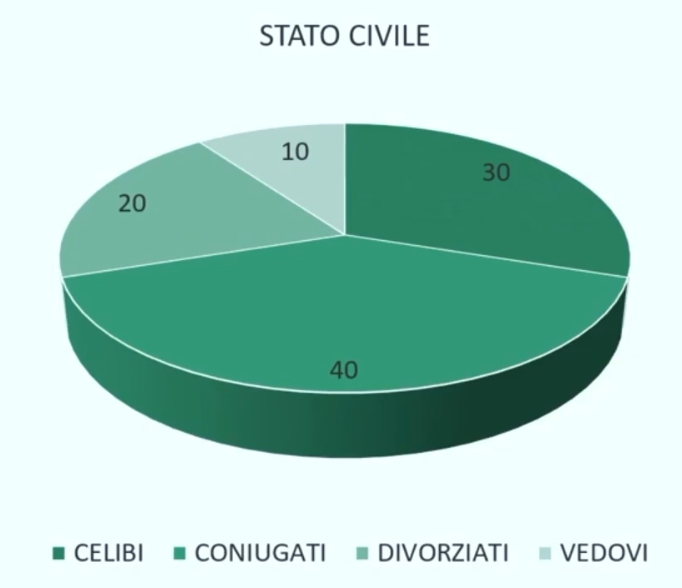
Diagramma a torta
Permette di rappresentare le frequenze in termini percentuali. Quindi abbiamo
Si ottiene il seguente diagramma a torta
Poligono di frequenza
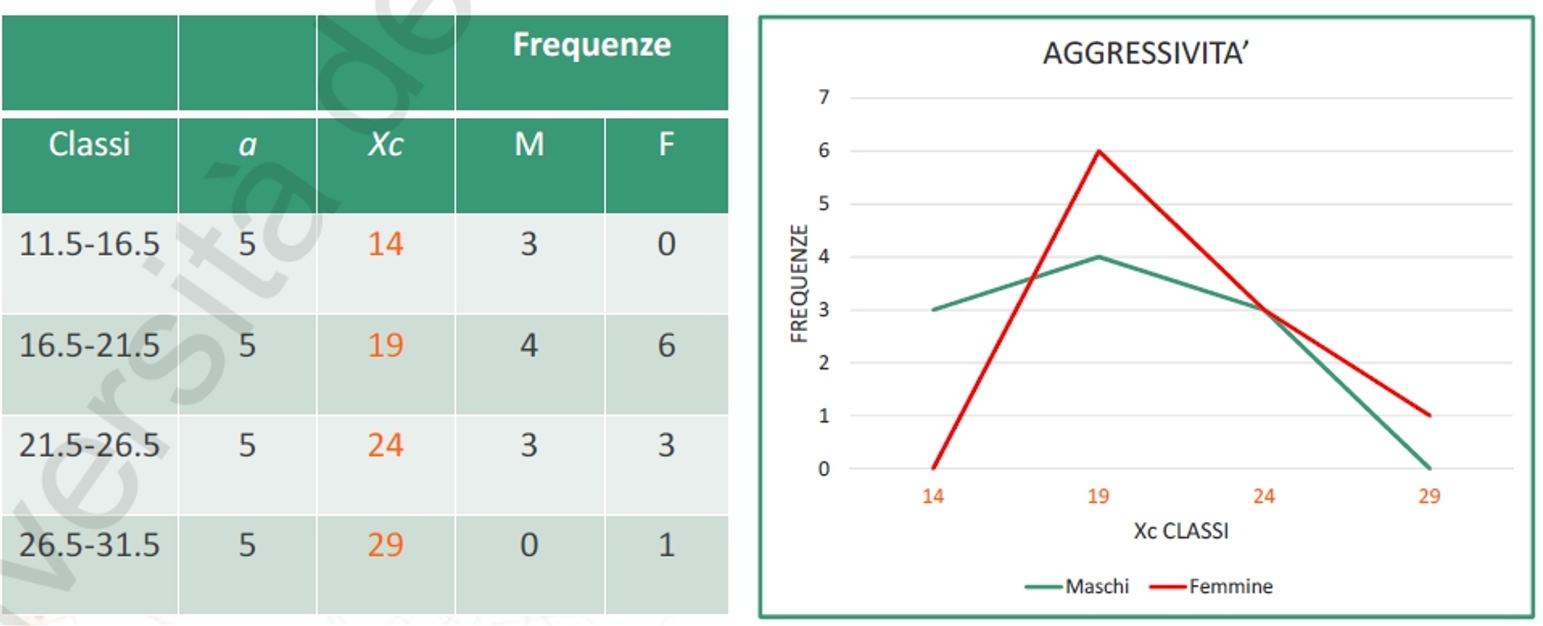
Il poligono di frequenza è una rappresentazione grafica su due assi cartesiani di una linea spezzata che rappresenta l’andamento delle frequenze.
Sull’asse delle ascisse si riporta il valore medio di ciascuna classe (cioè il limite reale superiore meno il limite reale inferiore, diviso 2)
Sull’asse delle ordinate si riportano le frequenze.
e questo è il grafico
Ogiva
L’ogiva permette di ottenere una rappresentazione grafica delle frequenze cumulate.
Sull’asse delle ascisse si riporta i valori assunti da una variabile, generalmente continua
Sull’asse delle ordinate si riportano le frequenze cumulate.
Poniamo il caso di aver misurato i punteggi ottenuti su un test di abilità verbali di 26 bambini di un asilo nido. Otteniamo la seguente distribuzione di frequenze.
I Dati grezzi sono tutto ci che viene osservato nel nostro campione di interesse. Per esempio i dati grezzi possono essere:
le risposte di ogni singolo soggetto ad un questionario di personalità
le sue risposte ad una scala di atteggiamento
la categorizzazione del comportamento di ogni singolo soggetto
Tutto ciò che raccogliamo deve essere poi trasformato in un file dati
Operazioni preliminari per la tabulazione dei dati
Per passare da dati raccolti in un file dati dobbiamo seguire alcuni passaggi:
Costruire un legame tra il questionario cartaceo e il file dati. Usualmente questa procedura prevede siglare ciascun questionario con un numero
Stabilire l’ordine secondo il quale le risposte vengono inserite nel file dati. Usualmente si segue la numerazione che le domande hanno sul supporto cartaceo
Scegliere un nome in codice per le variabili sulle quali si vuole lavorare. Questa procedura consiste nell”associare a ciascuna variabile un’ ETICHETTA
Spesso è necessario codificare numericamente alcune variabili. Di solito si attribuisce un numero intero, e se la variabile prevede solo due alternative si utilizza 0 e 1
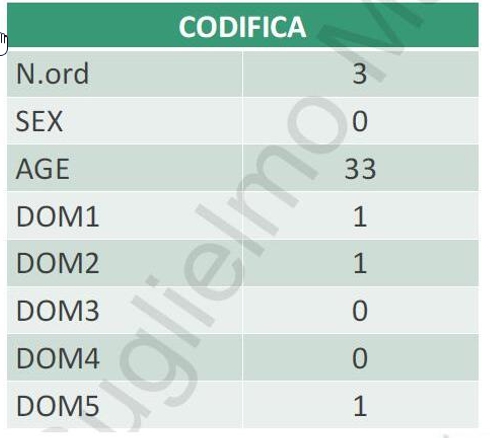
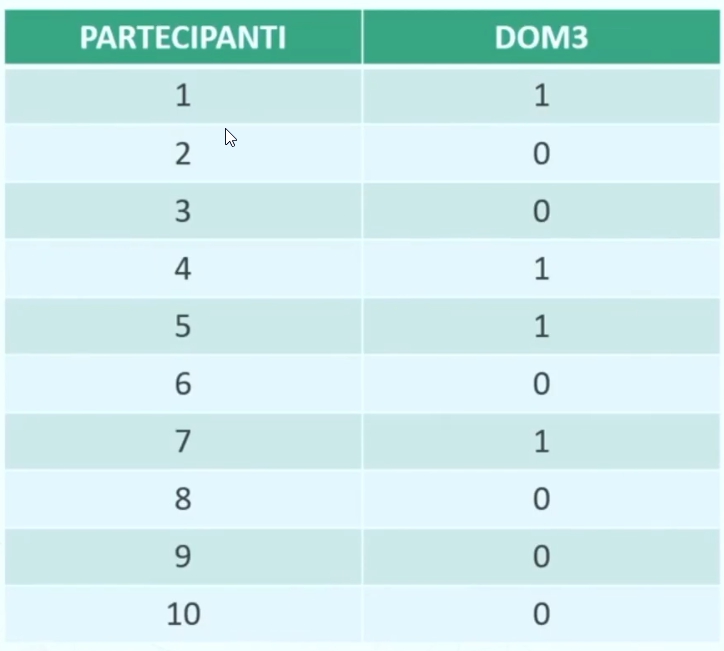
Esempio: Supponiamo di aver somministrato a 10 partecipanti una misura di atteggiamento composta da 5 affermazioni (con risposta SI/NO) e di aver rilevato anche il genere, l’età e il titolo di studio:
Numeriamo i questionari da 1 a 10
Decidiamo l’ordine delle variabili: — Numero, genere, età, domande da 1 a 5 (seguendo l’ordine che le domande hanno nel questionario)
Stabiliamo un codice per le modalità assunte dalla variabile: — SEX: maschio = 0, femmina = 1 — Domande: SI = 1, NO = 0
Supponiamo ora di codificare le risposte del terzo partecipante, maschio, di 33 anni. Questo ha risposto alle 5 affermazioni nel seguente modo: SI, SI, NO, NO, SI
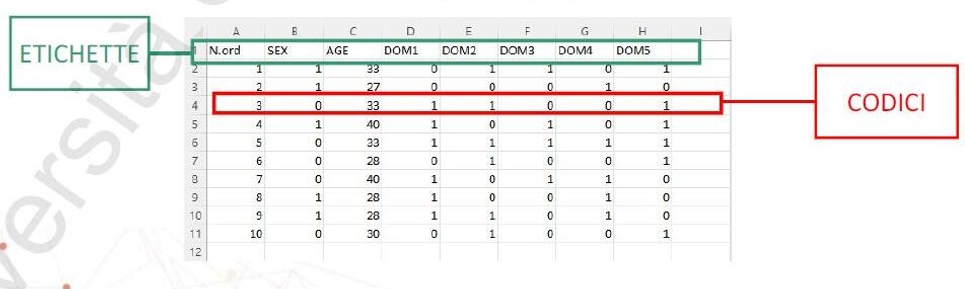
IL RISULTATO FINALE DI QUESTE OPERAZIONI È IL FILE DATI, una matrice casi (in riga) x variabili (in colonna)
La frequenza
La FREQUENZA è il numero delle volte in cui un determinato evento si verifica. In irferimento a un file dati la frequenza indica il Numero di casi osservati per ciascuna modalità che la variabile assume.
Ad esempio
Se la variabile di interesse è il sesso dei partecipanti → contare il numero di volte in cui si presenta la modalità «MASCHIO» oppure «FEMMINA» → si ottiene un numero che rappresenta la frequenza di partecipanti maschi e femmine nel gruppo.
Esempio frequenza (livello di misura scala nominale)
Ho 10 partecipanti che rispondono SÌ (codice 1) 4 volte e NO (codice 0) 6 volte.
Ho 10 partecipanti che rispondono SÌ (codice 1) 4 volte e NO (codice 0) 6 volte.
Le frequenze sono 4 (per risposta 1) e 6 (per risposta 0)
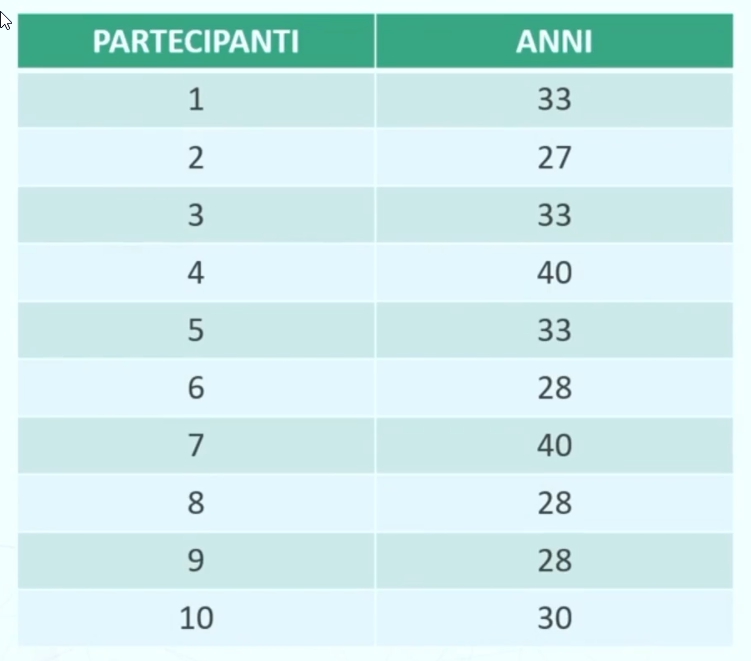
Esempio frequenza (livello di misura scala a rapporti o intervalli)
A destra ho una tabella che riporta gli anni di ciascun partecipante. Quindi ho (f indica frequenza)
anni 27 → f₁ = 1
anni 28 → f₂ = 3
anni 30 → f₃ = 1
anni 33 → f₄ = 3
anni 40 → f₅ = 2
Gli indici 1, 2, 3, 4 e 5 delle frequenze f (i.e., f₁, f₂, f₃, f₄, f₅) stanno a significare che la variabile assume 5 diversi valori. Indichiamo con k il numero dei valori diversi e con N il numero totale dei partecipanti.
Allora potremmo scrivere:La somma di tutte le frequenze è uguale al numero totale dei partecipanti. Dove:
N = totale partecipanti
Σ = sommatoria
Xᵢ = valore generico della variabile (o codifica della variabile)
fᵢ = numero delle volte in cui si presenta ciascun valore di X
k = numero di valori che X può assumere (modalità)
Distribuzione di frequenza
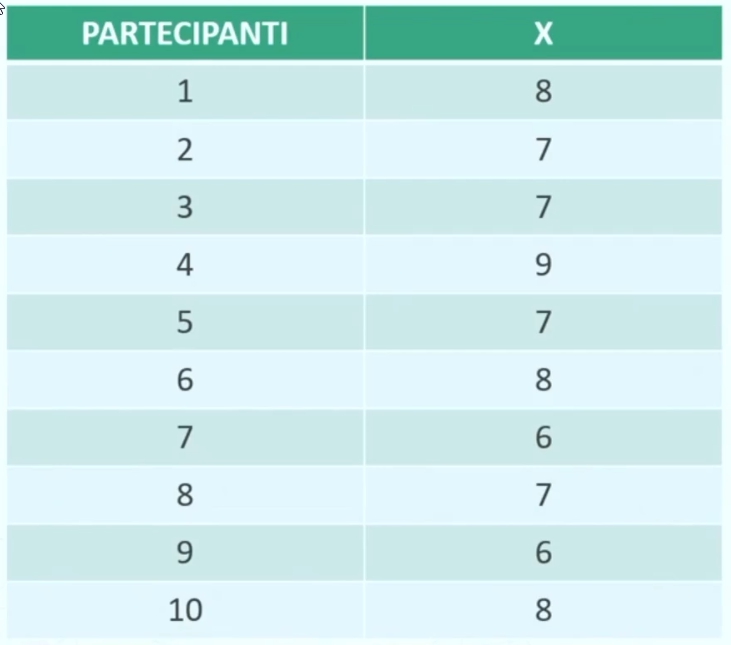
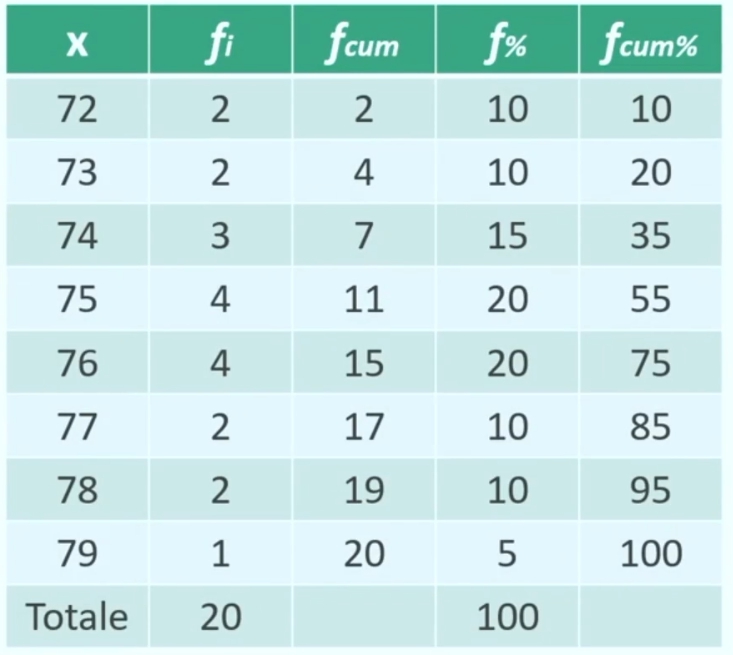
Seguendo la formula precedente posso creare la distribuzione di frequenza della variabile x. Ciò equivale a costruire una distribuzione in cui a ciascun valore di X viene associata la sua frequenza.
le frequenze sono
X₁ = 6 → f₁ = 2
X₂ = 7 → f₂ = 4
X₃ = 8 → f₃ = 3
X₄ = 9 → f₄ = 1
da cui abbiamo la seguente formula, con K=4 (modalità) e N=10
Frequenze cumulate
Un altro modo di conteggiare le frequenze è quello delle frequenze cumulate. Si ottengono sommando progressivamente le frequenze della distribuzione.
Questo procedimento ha lo scopo di facilitare e velocizzare la lettura dei dati: ad esempio, individuare la quantità di partecipanti che hanno un punteggio da 2 a 4 sulla variabile X, cioè 6
Frequenze relative o proporziale / frequenze percentuali
La frequenza relativa è il rapporto tra le frequenze di una modalità assunta dalla variabile e il totale dei casi.
La frequenza percenuale è invece la frequenza relativa moltiplicata per 100
Per riassumere all’interno di un’unica tabella, potremmo trovare diversi conteggi associati alle frequenze e alla loro distribuzione, utili a quantificare il numero di volte in cui la variabile X assume k modalità:
Frequenze semplici
Frequenze cumulate
Frequenze percentuali
Frequenze percentuali cumulate
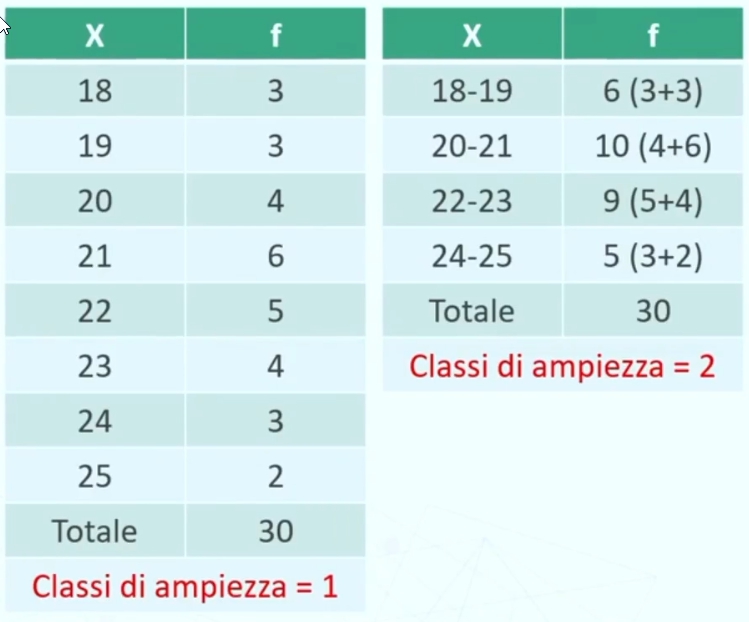
Le distribuzioni in classi
Le frequenze possono essere distribuite in specifiche classi.
Ciò è particolarmente utile quando le modalità della variabile sono molte (ad esempio, variabili metriche, x può avere 30 o 50 valori diversi).
Raggruppando le modalità della variabile oggetto di esame in classi o intervalli, otteniamo la FREQUENZA DI CLASSE, ovvero il numero di dati (partecipanti) compresi tra i valori che definiscono la classe (o intervallo).
Per costruire le classi posso seguire 3 criteri
Coprire l’intera gamma dei punteggi (altrimenti perderemmo dei dati)
Intervalli di uguale ampiezza (se possibile) (rende semplice il confronto e la rappresentazione grafica)
Intervalli mutuamente esclusivi (un dato deve entrare specificatamente in una classe e non in un’altra)
Esempio di partecipanti che riportano la loro età (f riporta il numero di volte che si è presentato il dato)
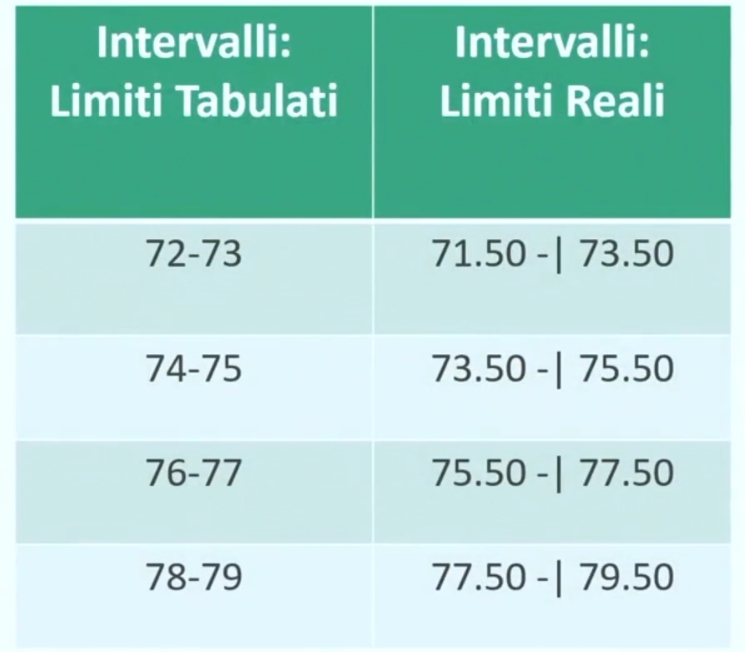
Numeri come 72, 73, 74, …, 79 rappresentano quelli che vengono definiti LIMITI TABULATI.
Poniamo ora il caso in cui fossimo interessati a classificare alcuni individui in base al loro peso (numeri con virgola). In questo caso dovremmo ricorrere ai LIMITI REALI.
I limiti reali si ottengono aggiungendo .50 al limite tabulato superiore e sottraendo .50 al limite tabulato inferiore.
Come si può procedere alla definizione delle classi e della loro ampiezza?
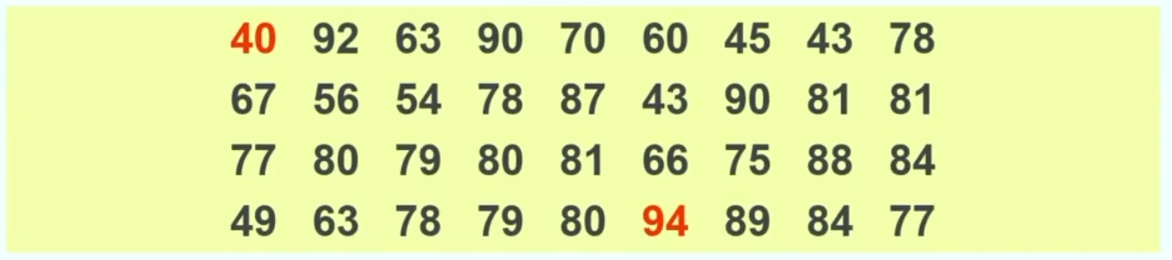
Consideriamo la seguente distribuzione di punteggi
possiamo usare le seguenti due formule
Gamma = (Xₘₐₓ − Xₘᵢₙ + 1) = 94 − 40 + 1 = 55 -> gamma è il rage di valori che può assumere la variabile
Ampiezza = (gamma : n° classi) = 55 : 5 = 11 -> questa rappresenta l’ampiezza di ciascuna classe
Otteniamo quindi 5 classi – i dati raggruppati nella seguente immagine
Riassumendo si definisce la Gamma della distribuzione (massimo − minimo + 1) e si divide per il numero delle classi volute. Questo porta all’ampiezza delle classi.
I LIMITI TABULATI dell’intervallo comprendono tutti i valori maggiori al limite inferiore e minori o uguali al limite superiore.
I LIMITI REALI si considerano mezzo punto sotto il limite inferiore e mezzo punto sopra il limite superiore.
Il numero delle classi non deve essere troppo elevato
(esempio 5 < k < 20)
ed è preferibile che l’ampiezza delle classi sia uguale
(es. 2, 3, 5, 10 e multipli).
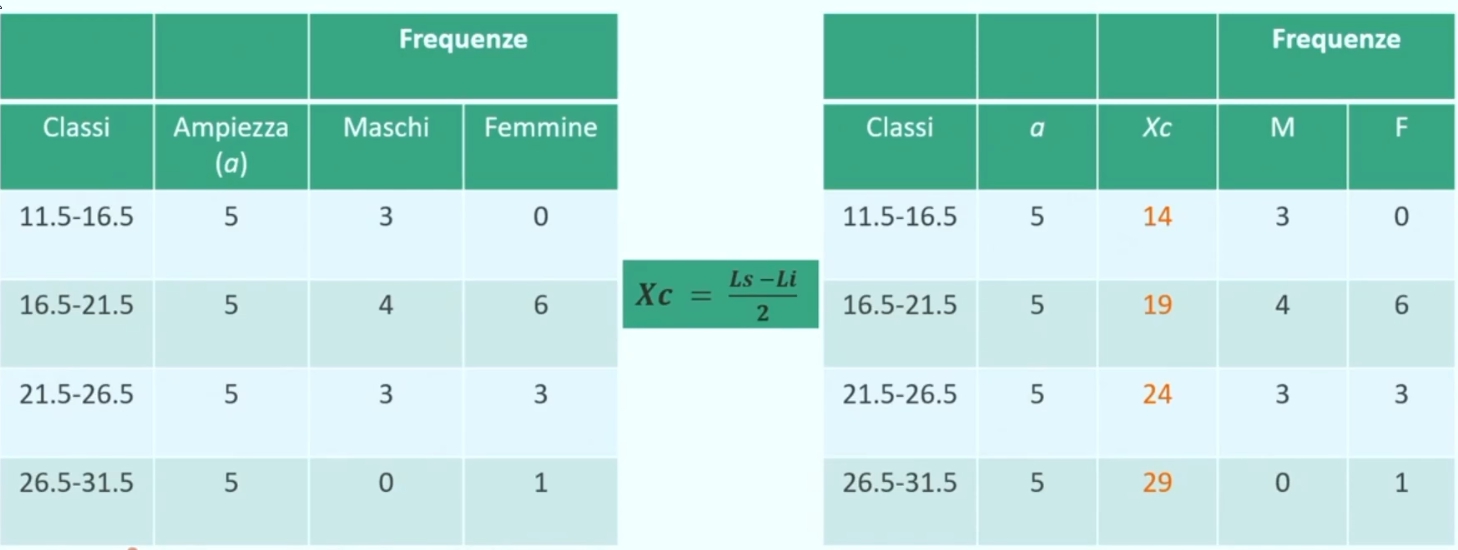
Posso calcolare il punto medio di ciascuna classe facendo la semisomma dei limiti inferiore e superiore.
I costrutti psicologici (concetti teorici non direttamente osservabili, come l’intelligenza, l’ansia o la personalità) possono essere rilevati seguendo diversi livelli di misurazione.
Diversi livelli corrispondono alle diverse proprietà dei numeri (come la capacità di identificare, ordinare o sommare i valori).
La misurazione avviene attraverso quattro tipologie di scale di misura.
Queste scale permettono di eseguire una serie crescente di possibili operazioni matematiche in base alle proprietà dei numeri che vengono utilizzate:
SCALA NOMINALE
SCALA ORDINALE
SCALA A INTERVALLI EQUIVALENTI
SCALA A RAPPORTI EQUIVALENTI
Scala nominale
La SCALA NOMINALE rappresenta il livello base di misurazione. Serve esclusivamente a classificare qualitativamente gli oggetti o i soggetti (definiti casi) che vengono studiati. In pratica, è un modo per organizzare i casi in gruppi o categorie.
A ogni categoria della variabile viene associato un numero che ha solo una funzione di simbolo: serve a identificare la categoria e a distinguerla dalle altre, senza indicare un valore numerico reale.
La proprietà dei numeri utilizzata è quindi la CLASSIFICAZIONE.
Alcuni esempi di questa scala sono:
Appartenenza politica (ad esempio: 1 = Destra; 2 = Centro; 3 = Sinistra)
Appartenenza ad una categoria diagnostica (ad esempio: 1 = Disturbo Ossessivo-Compulsivo; 2 = Depressione; 3 = Ansia sociale)
Un caso specifico di questa scala è la variabile dicotomica (una variabile che prevede solo due categorie). Questo è il livello di misurazione più basso in assoluto, poiché non può esistere classificazione se non ci sono almeno due opzioni. Esempi tipici sono:
Sì / No
Genere (Maschio / Femmina)
Risposta giusta / sbagliata
La scala nominale segue precise PROPRIETÀ FORMALI:
L’EQUIVALENZA tra i membri della stessa categoria si basa su:
Simmetria (se A è uguale B, allora B è uguale ad A)
Transitività (se A è uguale a B e B è uguale a C, allora anche A è uguale a C)
La NON EQUIVALENZA tra membri di categorie diverse si basa su:
Simmetria (se A è diverso da B, allora B è diverso da A)
Non transitività (se A è diverso da B e B è diverso da C, non è detto che A sia diverso da C; A e C potrebbero anche appartenere alla stessa categoria)
Per quanto riguarda le OPERAZIONI MATEMATICHE POSSIBILI, su questa scala è consentito solo il conteggio dei casi per ogni categoria, ovvero il calcolo delle frequenze (contare quante volte compare una determinata caratteristica).
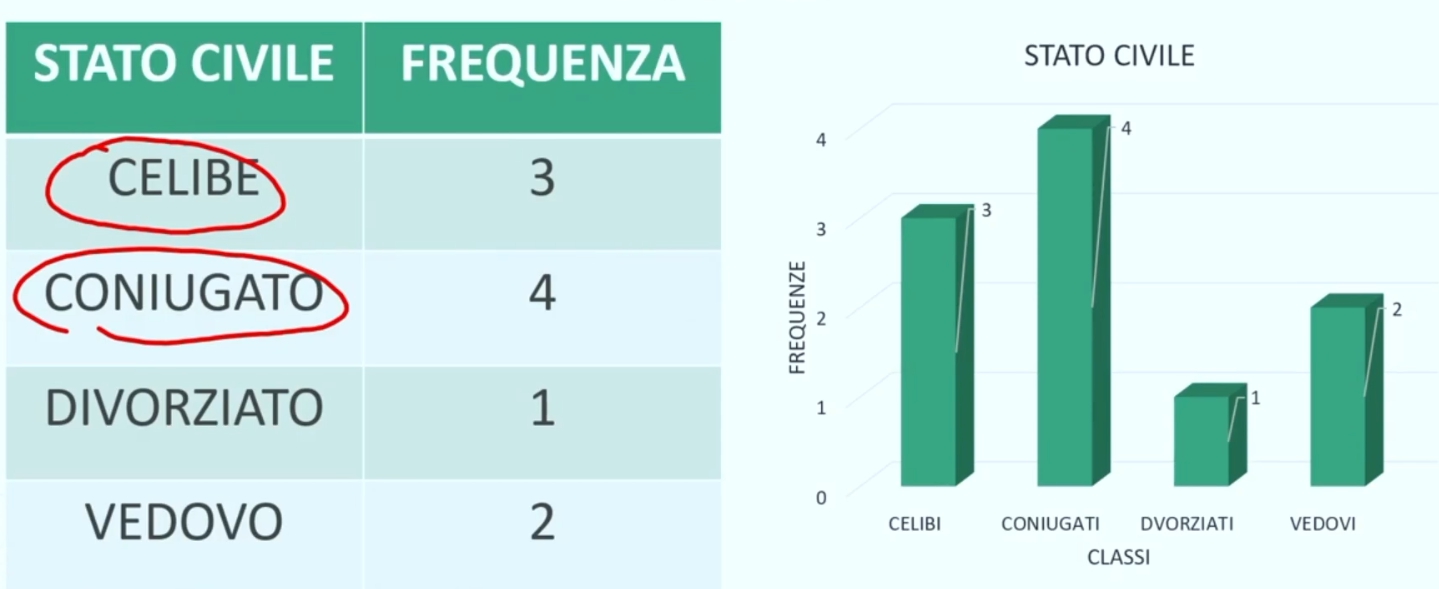
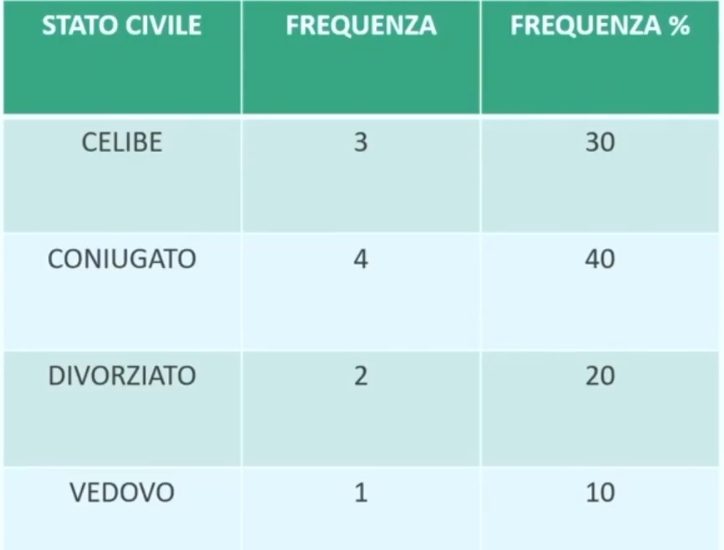
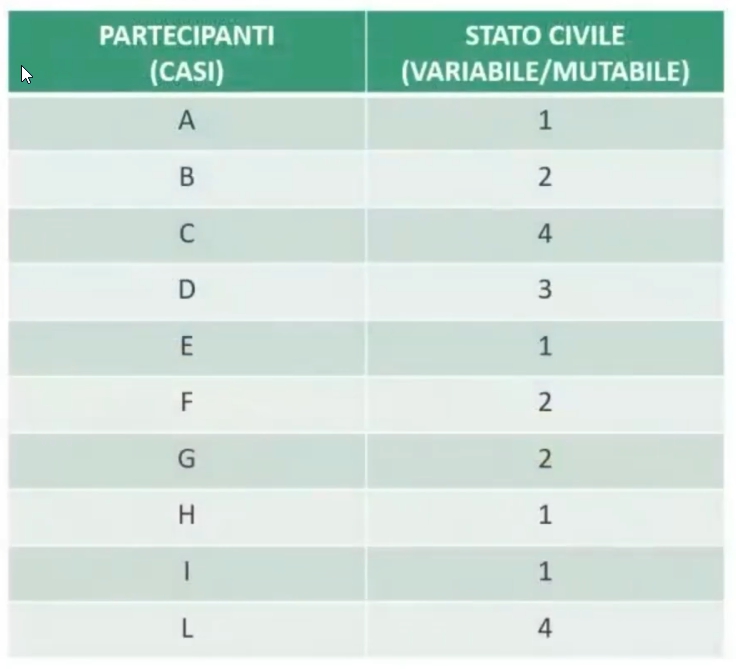
Ad esempio, se analizziamo la variabile stato civile su 10 partecipanti:
Possiamo solo calcolare quanti soggetti appartengono a ogni gruppo (ad esempio scoprire che ci sono 4 coniugati, 3 celibi, ecc.). Non si possono fare somme o medie tra i numeri assegnati alle categorie.
Le PROCEDURE STATISTICHE APPLICABILI sono i Test non parametrici (metodi statistici che non presuppongono una distribuzione normale dei dati e si usano per campioni piccoli o variabili qualitative). Questi test si basano esclusivamente sul conteggio delle frequenze.
Le variabili misurate con questa scala sono chiamate categoriali o nominali . Sono variabili discrete (composte da categorie ben distinte) e qualitative.
Scala ordinale
La SCALA ORDINALE aumenta leggermente il grado di precisione della misurazione perché introduce il concetto di ORDINE tra le categorie. In questo caso, i dati vengono classificati secondo un ordine gerarchico o di rango (la posizione occupata in una classifica).
Il numero associato alla categoria indica solo la posizione (ad esempio: superiore/inferiore, prima/dopo, maggiore/minore) e NON la quantità esatta della caratteristica misurata. Le differenze tra le classi non sono quindi quantificabili (non sappiamo “quanto” distano tra loro), ma solo ordinabili.
La proprietà dei numeri utilizzata è l’ORDINE.
Alcuni esempi di questa scala sono:
Titolo di studio (ad esempio: 1 = Dottorato; 2 = Laurea; 3 = Diploma; 4 = Licenza media; 5 = Licenza elementare)
Valutazione del livello di una prestazione (ad esempio: 1 = Bassa; 2 = Media; 3 = Alta)
Ordine di preferenza (ad esempio: 1 = Preferisco la mattina presto; 2 = Preferisco la tarda mattinata; 3 = Preferisco il pomeriggio)
La scala ordinale segue precise PROPRIETÀ FORMALI:
L’EQUIVALENZA tra i membri della stessa categoria (come nella scala nominale) si basa su:
Simmetria (se A = B allora B = A)
Transitività (se A = B e B = C allora A = C)
La RELAZIONE D’ORDINE tra membri di categorie diverse si basa su:
Asimmetria (se A > B allora B < A; ad esempio, se il titolo di studio di A è maggiore di quello di B, allora quello di B non può essere maggiore di quello di A)
Transitività (se A > B e B > C allora A > C; se la laurea è superiore al diploma e il diploma è superiore alla licenza media, allora la laurea è superiore alla licenza media)
Per quanto riguarda le OPERAZIONI MATEMATICHE POSSIBILI, rimane possibile solo il conteggio delle frequenze (contare quanti soggetti appartengono a ogni categoria), proprio come nella scala nominale.
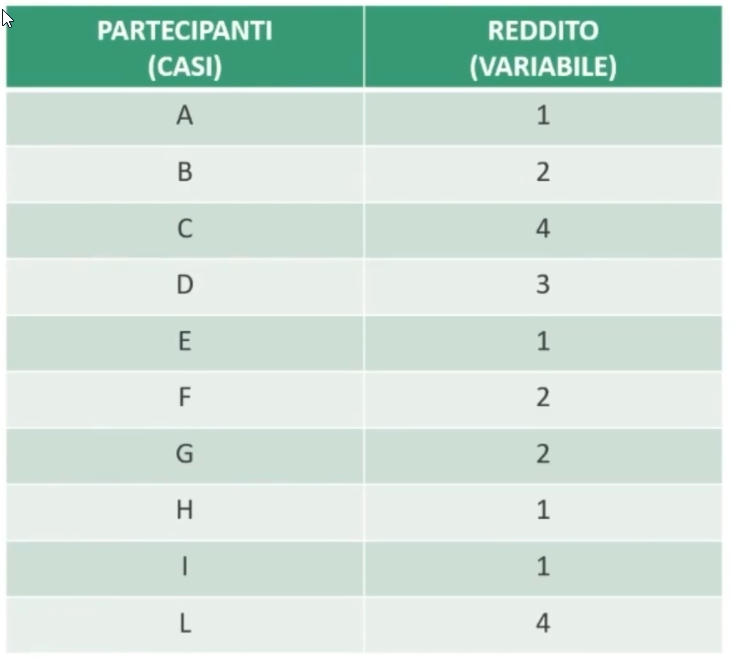
Ad esempio, se classifichiamo 10 partecipanti in base alla loro fascia di reddito:
1 = alto, 2 = medio-alto, 3 = medio, 4 = basso
Possiamo contare quanti soggetti ci sono in ogni fascia (frequenza) e, a differenza della scala nominale, possiamo stabilire un ordine di posizionamento dei casi (sappiamo chi guadagna più di chi, anche se non sappiamo esattamente quanto).
Le PROCEDURE STATISTICHE APPLICABILI sono i Test non parametrici (metodi statistici che si usano quando i dati non seguono una distribuzione precisa o sono in piccoli campioni). Questi test si basano sul conteggio delle frequenze e sull’ordinamento o rango (la posizione in graduatoria).
Le variabili misurate con questa scala sono definite ordinali. Sono variabili discrete (non ammettono valori intermedi tra una categoria e l’altra) e qualitative.
Scala a intervalli equivalenti
La SCALA A INTERVALLI EQUIVALENTI rappresenta un progresso notevole rispetto alle scale nominale e ordinale. Utilizza una unità di misura costante che permette di effettuare operazioni algebriche basate sulle differenze tra i numeri. In questo modo, è possibile classificare i dati secondo un ordine e contemporaneamente quantificare le differenze tra le varie posizioni (ad esempio, sappiamo che tra 10 e 20 c’è la stessa distanza che esiste tra 30 e 40). A ogni modalità della variabile viene associato un numero secondo una specifica grandezza d’ordine.
In questa scala, il numero rappresenta la quantità di una determinata caratteristica posseduta dal soggetto. Tuttavia, l’assegnazione dei numeri è arbitraria perché non esiste uno zero assoluto (uno zero che indica l’assenza totale della caratteristica, come ad esempio l’assenza totale di intelligenza).
Le codifiche numeriche (esempio intelligenza = 10) sono convenzionali e stabilite dal ricercatore mantenendo costante la distanza tra gli intervalli. Questi valori possono essere positivi, negativi o anche corrispondere allo zero, ma si tratta sempre di uno zero convenzionale e non assoluto.
La proprietà dei numeri utilizzata è la QUANTIFICAZIONE.
Il limite principale di questa scala è proprio il partire da uno zero arbitrario: questo non permette di stabilire dei rapporti diretti di equivalenza (non possiamo dire che 20 è il doppio di 10).
Ad esempio:
La temperatura misurata in gradi Celsius o Fahrenheit ha uno zero arbitrario.
Possiamo affermare che la differenza tra 2°C e 4°C è uguale alla differenza tra 3°C e 5°C.
NON possiamo però dire che 4°C è il doppio di 2°C. Infatti, convertendo questi valori in Fahrenheit, il rapporto matematico non reggerebbe più, dimostrando che il “doppio” non ha un senso reale in questa scala.
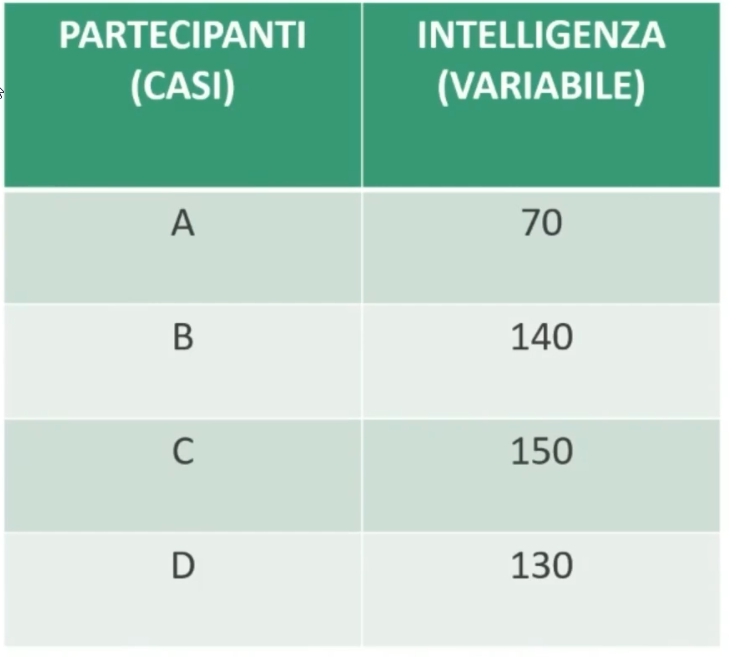
Anche in psicologia si usa questa logica e la maggior parte delle variabili psicologiche viene misurata su scale a intervalli. Ad esempio, se somministriamo un test di intelligenza a 4 partecipanti:
Possiamo dire che la distanza tra un punteggio di 140 e 150 è la metà della distanza che c’è tra 130 e 150.
NON POSSO però dire che un soggetto con punteggio 140 è doppiamente intelligente rispetto a uno con 70.
Le PROPRIETÀ FORMALI di questa scala includono:
EQUIVALENZA (simmetrica e transitiva) tra i membri che hanno lo stesso valore.
RELAZIONE D’ORDINE (asimmetrica e transitiva) tra valori diversi.
COSTANZA DELLA DIFFERENZA TRA INTERVALLI: la distanza tra due numeri (es. 1 e 2) è identica a quella tra altri due numeri con lo stesso scarto (es. 3 e 4).
Per quanto riguarda le OPERAZIONI MATEMATICHE POSSIBILI, sono consentite l’addizione e la sottrazione. Non è invece possibile stabilire rapporti diretti (divisioni o moltiplicazioni) tra le misure.
Le PROCEDURE STATISTICHE APPLICABILI sono i Test parametrici (metodi statistici più potenti che richiedono dati misurati su scale numeriche e specifiche assunzioni sulla distribuzione dei dati).
Le variabili misurate con questa scala sono dette metriche. Sono variabili quantitative che possono essere continue (possono assumere qualsiasi valore numerico, anche con decimali) o discrete (valori numerici interi). In questa scala non si hanno più categorie ma VALORI NUMERICI (punteggi reali). Esempi tipici sono la temperatura in gradi centigradi e i test psicologici che misurano il Quoziente Intellettivo (Q.I.).
Scale a rapporti equivalenti
La SCALA A RAPPORTI EQUIVALENTI, definita anche proporzionale o razionale, rappresenta il livello di misurazione più elevato. Questa scala permette di classificare e ordinare i dati quantificando le differenze partendo da uno zero assoluto. A differenza della scala a intervalli, lo zero qui non è arbitrario ma indica la reale assenza della caratteristica misurata. Non può assumere valori negativi
Il numero rappresenta quindi la quantità reale ed effettiva della variabile.
La proprietà dei numeri utilizzata è la QUANTIFICAZIONE.
Le PROPRIETÀ FORMALI di questa scala sono:
EQUIVALENZA (simmetrica e transitiva) tra i soggetti che hanno lo stesso valore numerico.
RELAZIONE D’ORDINE (asimmetrica e transitiva) tra valori diversi.
COSTANZA DEL RAPPORTO TRA INTERVALLI (la distanza tra 1 e 2 è identica a quella tra 3 e 4).
COSTANZA DEL RAPPORTO TRA VALORI: è possibile stabilire rapporti diretti tra le misure. Ad esempio, possiamo dire con certezza che:
2 è il doppio di 1
2 è la metà di 4
3 è il triplo di 1
1 è un terzo di 3
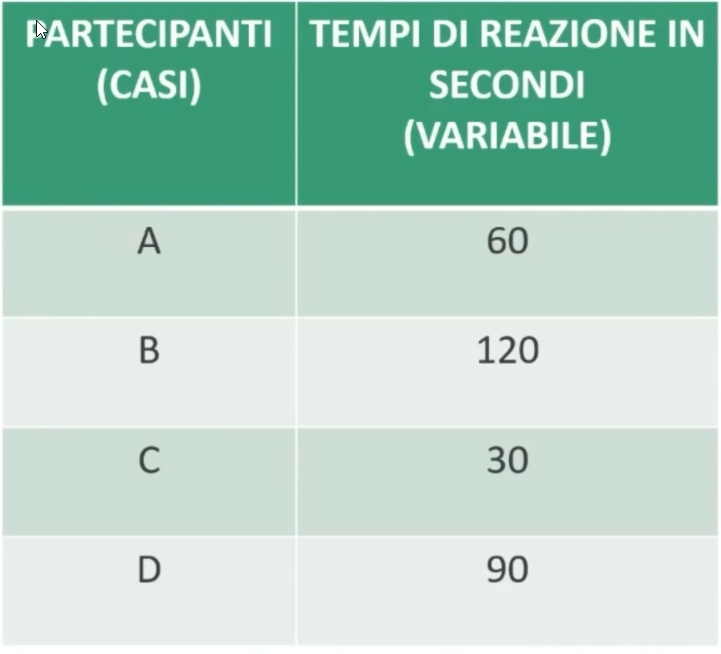
Un esempio pratico in psicologia è la misurazione dei tempi di reazione (il tempo che passa tra la presentazione di uno stimolo, come un’immagine, e la risposta del soggetto). Se analizziamo i dati di 4 partecipanti:
A impiega 60 secondi
B impiega 120 secondi
C impiega 30 secondi
D impiega 90 secondi
In questo caso, possiamo affermare che A ha impiegato la metà del tempo di B e il doppio del tempo di C, mentre D ha impiegato il triplo del tempo di C.
L’unica arbitrarietà di questa scala riguarda l’unità di misura scelta (ad esempio secondi o minuti). Tuttavia, se cambiamo unità di misura (ad esempio dividendo i secondi per 60 per ottenere i minuti), i rapporti tra i valori non cambiano: A (1 minuto) sarà sempre la metà di B (2 minuti). I rapporti tra i VALORI rimangono quindi invariati.
Per quanto riguarda le OPERAZIONI MATEMATICHE POSSIBILI, su questa scala sono consentite TUTTE le operazioni (addizione, sottrazione, moltiplicazione e divisione).
Le PROCEDURE STATISTICHE APPLICABILI sono i Test parametrici (metodi statistici accurati che richiedono dati misurati su scale numeriche e specifiche caratteristiche della distribuzione).
Le variabili misurate con questa scala sono definite metriche. Sono variabili quantitative che possono essere continue (possono assumere qualsiasi valore, anche con decimali) o discrete (utilizzano solo numeri interi). Non si parla più di categorie ma di VALORI NUMERICI reali. Esempi tipici sono l’età, l’altezza e i tempi di reazione.
Riassumendo
RIASSUMENDO…
SCALA NOMINALE: si tratta di una misura qualitativa di una variabile. Il numero viene utilizzato esclusivamente come simbolo per categorizzare e distinguere i gruppi (ad esempio: 1 = italiano).
SCALA ORDINALE: serve per ORDINARE le categorie secondo una gerarchia. I numeri indicano una posizione, ma le distanze tra un valore e l’altro non sono costanti né quantificabili
SCALA A INTERVALLI: permette di QUANTIFICARE una caratteristica in modo arbitrario. In questa scala, la distanza tra i numeri è costante e uguale, ma non esiste uno zero reale da cui partire.
SCALA A RAPPORTI: permette di QUANTIFICARE effettivamente la quantità di una caratteristica. Questa scala parte da uno 0 (zero assoluto, che indica l’assenza totale del fenomeno misurato) e mantiene distanze costanti tra i valori numerici.
Inoltre
Ogni scala di misura possiede tutte le caratteristiche di quella che la precede nella gerarchia.
È dunque possibile abbassare il livello della scala di misura (ad esempio, trasformare una scala a intervalli in una scala ordinale riducendo la precisione delle informazioni), ma NON È POSSIBIBILE IL PROCEDIMENTO INVERSO (una scala ordinale non può mai essere trasformata in una scala a intervalli poiché mancano le informazioni numeriche necessarie).
La scelta della scala di misura da utilizzare dipende dalla definizione operativa della variabile (l’insieme di regole e procedure concrete che il ricercatore stabilisce per misurare un costrutto) e dal suo scopo all’interno della ricerca.
Una caratteristica psicologica qualitativa può essere quantificata, permettendo il passaggio da un livello QUALITATIVO a un livello QUANTITATIVO (ad esempio, contando il numero di comportamenti manifestati da un individuo).
L’aggressività può essere definita in diversi modi in base all’obiettivo:
Presente/Assente SCALA NOMINALE
Bassa, Media, Alta SCALA ORDINALE
Numero di comportamenti aggressivi osservati SCALA A RAPPORTI
Questo processo riguarda l’operazionalizzazione del costrutto (il processo di traduzione di un concetto teorico astratto in variabili misurabili), che deve essere definita a priori, cioè prima di iniziare lo studio. Una volta che i dati sono stati raccolti ad un livello nominale, NON è possibile passare successivamente ad un livello di misura superiore.
In base allo scopo della ricerca, la stessa variabile può essere trattata a diversi livelli:
Titolo di studio SCALA ORDINALE
Anni di scolarità → SCALA A RAPPORTI
Anche in questo caso, il livello di misura deve essere deciso prima della raccolta dei dati: se raccogliamo solo il titolo di studio, non potremo mai risalire con precisione agli anni esatti di scolarità.
Dopo aver effettuato la misurazione, l’unica trasformazione possibile è quella che parte dal livello di misura più elevato per scendere verso quelli inferiori (QUANTITATIVO → QUALITATIVO):
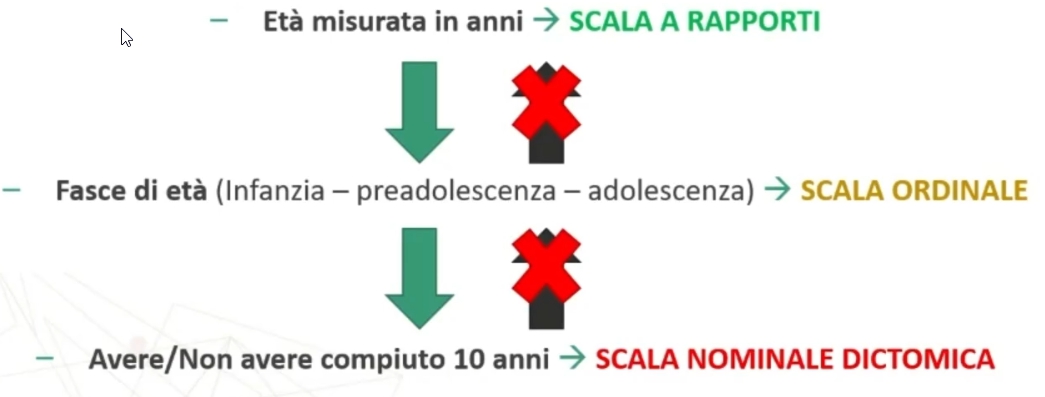
Età misurata in anni SCALA A RAPPORTI (livello massimo di precisione)
Fasce di età (Infanzia – preadolescenza – adolescenza) → SCALA ORDINALE (raggruppamento in categorie ordinate)
Avere/Non avere compiuto 10 anni → SCALA NOMINALE DICOTOMICA (semplice classificazione in due gruppi)
Tipi di variabili
Si definisce VARIABILE una proprietà o una caratteristica di un fenomeno che può essere espressa attraverso più valori, siano essi numerici o categoriali (suddivisi in categorie). Solitamente, la variabile si oppone al concetto di COSTANTE (un elemento che non cambia mai il suo valore all’interno di un’osservazione).
Più precisamente, una variabile è una qualunque caratteristica che può assumere diversi valori in un dato intervallo. Alcuni esempi chiariscono la differenza:
Il sorgere del sole NON è una variabile, ma una COSTANTE (il fenomeno non è classificabile in modi diversi perché il sole sorge sempre e solo una volta al giorno).
Il numero di nasi in un volto è una COSTANTE (non varia tra gli individui comuni).
L’ora in cui il sole sorge è invece una VARIABILE (il fenomeno è misurabile e cambia durante il corso dell’anno).
Età, reddito, intelligenza, colore di capelli, aggressività e ansia sono tutti esempi di fenomeni VARIABILI.
Le VARIABILI vengono ulteriormente classificate in base a due criteri:
Il livello di misura:
Continue e discrete
Qualitative e quantitative
Nominali e metriche
Il ruolo che hanno nell’osservazione del comportamento o nella ricerca:
Indipendenti
Dipendenti
Una VARIABILE DISCRETA può assumere un numero FINITO di valori all’interno di un intervallo (si passa da un valore all’altro senza possibilità di frazioni intermedie). Esempi:
Numero di figli
Numero di errori in un compito
Numero di risposte giuste ad un test di profitto (valutazione delle conoscenze acquisite)
Una VARIABILE CONTINUA può assumere un numero INFINITO di valori all’interno di un intervallo (può avere infiniti decimali tra un numero intero e l’altro). Esempi:
Tempi di reazione
Età
Peso
Una VARIABILE QUALITATIVA O NOMINALE si riferisce a categorie e non a quantità numeriche. Esempi:
Colore di capelli
Tipo di patologia psicologica
Diagnosi di un disturbo
Una VARIABILE QUANTITATIVA O METRICA è associabile a scale numeriche e alle diverse modalità (i valori specifici che la variabile può assumere) che può presentare. Esempi:
Età
Quoziente di intelligenza (indice numerico usato per valutare le capacità cognitive)
Punteggi di ansia
Infine, le variabili si distinguono per il rapporto di causa-effetto:
La VARIABILE INDIPENDENTE è la variabile capace di predire, influenzare o esercitare un effetto su un’altra variabile (quella dipendente). Può essere manipolata dallo sperimentatore (che ne decide il valore per vedere cosa succede) o essere già presente nel campione studiato.
La VARIABILE DIPENDENTE è la variabile che viene predetta, influenzata o plasmata dalla variabile indipendente. Il suo valore varia proprio al variare della variabile indipendente. Viene solo misurata sul campione e non viene manipolata dall’osservatore.
La psicometria è la disciplina che studia la misura di caratteristiche psicologiche. I temi principali sui quali si concentra sono:
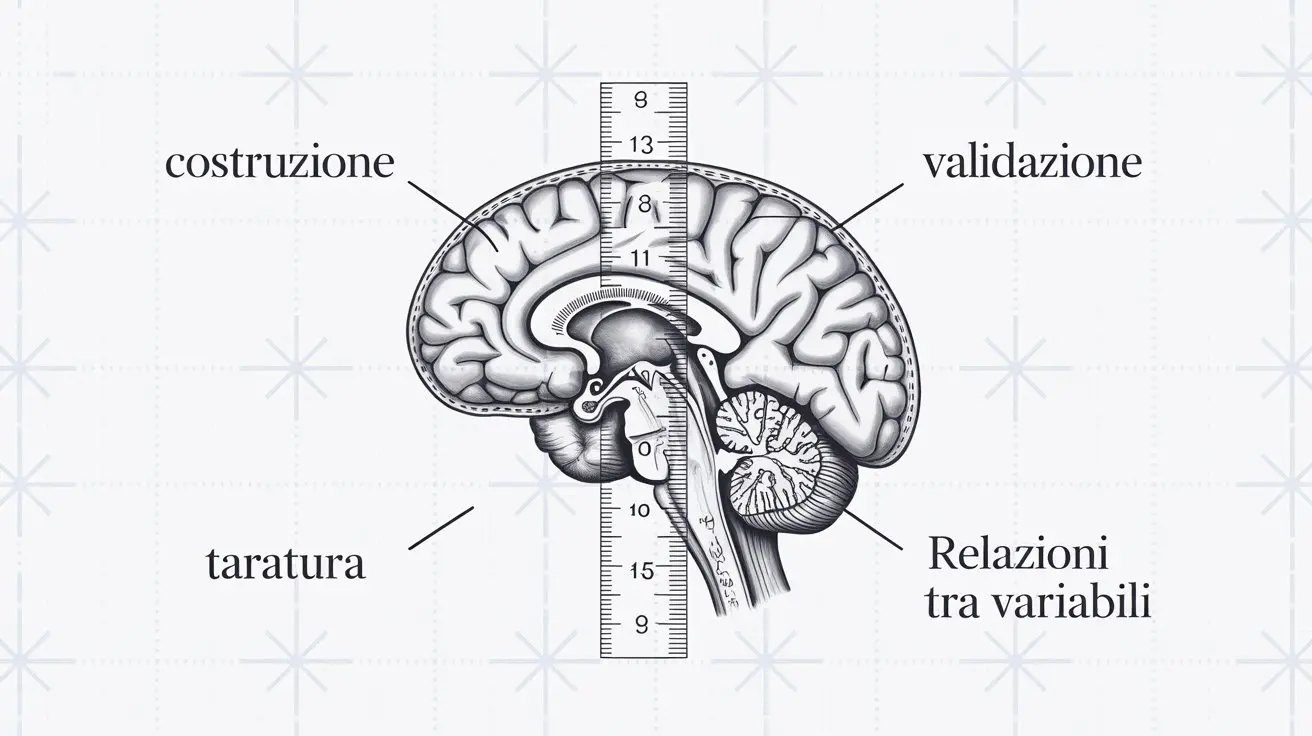
la costruzione, la validazione e la taratura (processo per stabilire le norme di riferimento di un test) di strumenti di misura mirati a rilevare determinati concetti psicologici, come ad esempio un questionario sull’aggressività;
l’applicazione delle tecniche statistiche necessarie a testare le ipotesi formulate sulla base di teorie psicologiche, (ad esempio per esaminare se l’esposizione a episodi di bullismo favorisca futuri comportamenti aggressivi).
La ricerca scientifica, in psicologia come in altre discipline, è interessata allo studio e all’approfondimento delle relazioni fra variabili. Per indagare le relazioni fra variabili, la statistica è uno strumento indispensabile.
Ad esempio, uno psicologo o ricercatore potrebbe essere interessato a studiare l’efficacia di un trattamento psicoterapeutico nella cura di un disturbo. Al fine di ottenere evidenza scientifica circa l’efficacia di tale trattamento, egli dovrà pianificare una ricerca, articolando accuratamente le sue fasi, e giungere ad una dimostrazione della sua ipotesi di partenza (ovvero che il trattamento sia efficace). La statistica accompagnerà il ricercatore o psicologo lungo tutto il processo, a partire dalla pianificazione della ricerca fino ad arrivare alla dimostrazione di efficacia del trattamento.
Teoria e formulazioni delle ipotesi di ricerca
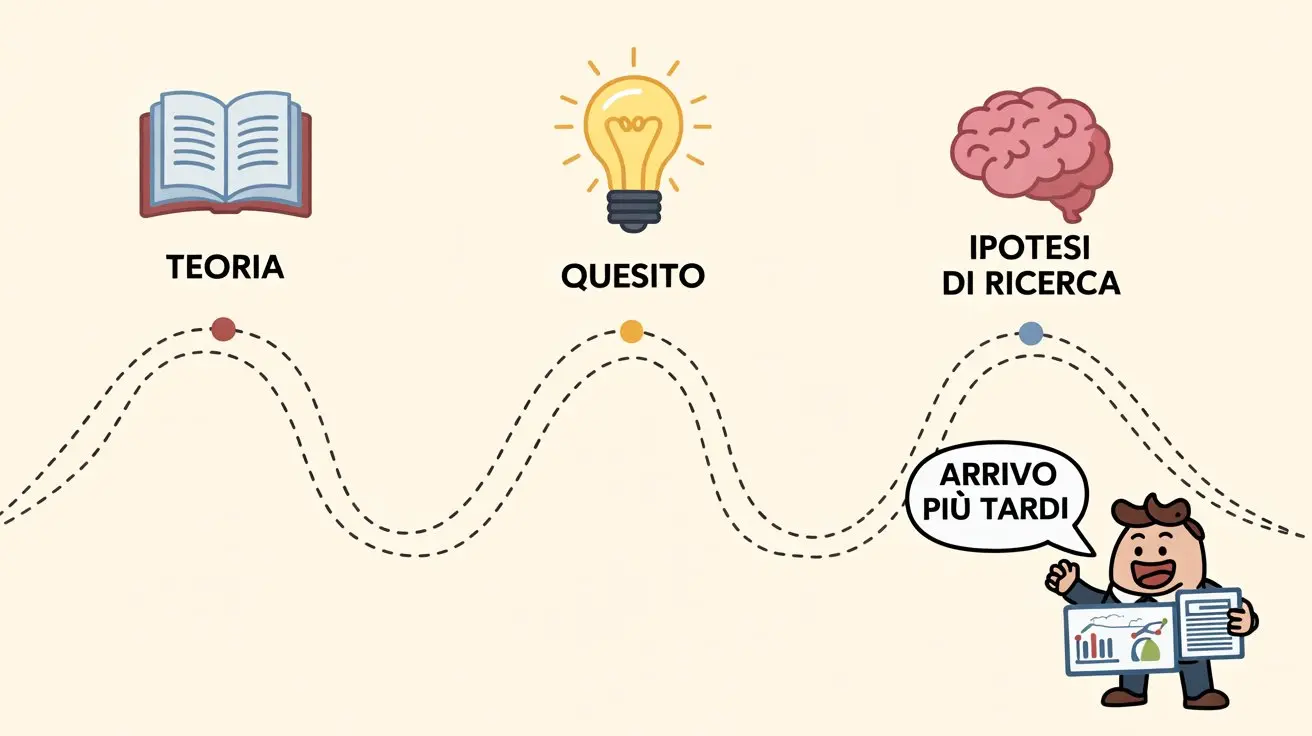
Per quanto riguarda la teoria e la formulazione delle ipotesi, il processo segue questi passaggi:
TEORIA: è la prima fase e riguarda la definizione teorica dei concetti d’interesse (ad esempio, avere una conoscenza approfondita di un disturbo psicologico che si vuole curare).
QUESITO: il ricercatore si pone la domanda di ricerca (ad esempio: in che modo è possibile curare quel disturbo?).
IPOTESI DI RICERCA: corrisponde alla definizione formale delle aspettative relative al quesito. Ci si aspetta che un gruppo di pazienti con un certo disturbo mostri dei miglioramenti dopo l’esposizione a uno specifico trattamento.
In queste fasi iniziali la statistica ha un rilievo minore
Piano esecutivo
Con il piano esecutivo andiamo ad indagare le ipotesi definite in precedenza:
IPOTESI OPERATIVE: consiste nella definizione operativa delle ipotesi formulate. In pratica, si specifica che il gruppo di pazienti con un certo disturbo esposto al trattamento mostrerà miglioramenti rispetto a un gruppo con lo stesso disturbo ma non esposto al trattamento.
POPOLAZIONE: indica gli individui di cui siamo interessati a studiare le caratteristiche (ad esempio i pazienti con quel disturbo). In questa fase la statistica è necessaria per estrarre un campione rappresentativo della popolazione e per stabilire la quantità di individui da includere nella ricerca.
STRUMENTI: sono i mezzi, come questionari o interviste, che permettono di misurare e quantificare le variabili oggetto di studio. La statistica è fondamentale per costruirli, elaborarli e utilizzarli correttamente.
METODI STATISTICI: sono le procedure attraverso le quali si intende testare le ipotesi di ricerca, come ad esempio effettuare il confronto tra un gruppo esposto al trattamento e uno non esposto.
Racolta ed elaborazione dei dati
Una volta pianificata la ricerca si continuerà con la raccolta dati
CALCOLO INDICI STATISTICI: consiste nel trasformare i punteggi rilevati tramite gli strumenti (come un questionario) in indicatori della variabile di interesse (ad esempio, ottenendo un punteggio unico che indichi il livello del disturbo nei pazienti).
VERIFICA IPOTESI: riguarda l’applicazione di tecniche statistiche per fornire evidenza sulle aspettative teoriche della ricerca. Si utilizza, ad esempio, il test t (un test statistico di confronto) per verificare se i pazienti sottoposti al trattamento riportano effettivamente un livello medio di disturbo minore rispetto a quelli non trattati.
DISCUSSIONE DEI RISULTATI: basandosi sulle evidenze statistiche ottenute, si esplicitano le conclusioni concettuali della ricerca (ad esempio, affermando che il trattamento risulta efficace per la cura del disturbo).
La misura in psicologia
Concetto di misura
Misurare consiste nello stabilire una corrispondenza tra certe proprietà dei numeri e certe proprietà degli oggetti.
I problemi legati alla misurazione sono presenti in tutte le discipline, ma sono particolarmente rilevanti per le caratteristiche psicologiche (come opinioni o atteggiamenti), in quanto bisogna tradurre concetti astratti in numeri. La differenza fondamentale tra misurare l’altezza e l’aggressività è che l’altezza è una caratteristica direttamente osservabile, mentre l’aggressività non lo è.
Le grandezze estensive (come l’altezza) hanno specifiche proprietà: sono divisibili in parti, sommabili, direttamente misurabili (percepibili e quantificabili direttamente) e dotate di un’unità campione standardizzata sulla quale operare in termini additivi (come il peso in Kg o la lunghezza in Km).
Le grandezze intensive (come l’aggressività) si distinguono da quelle estensive poiché non sono direttamente osservabili, ma inferibili indirettamente attraverso determinati indicatori comportamentali.
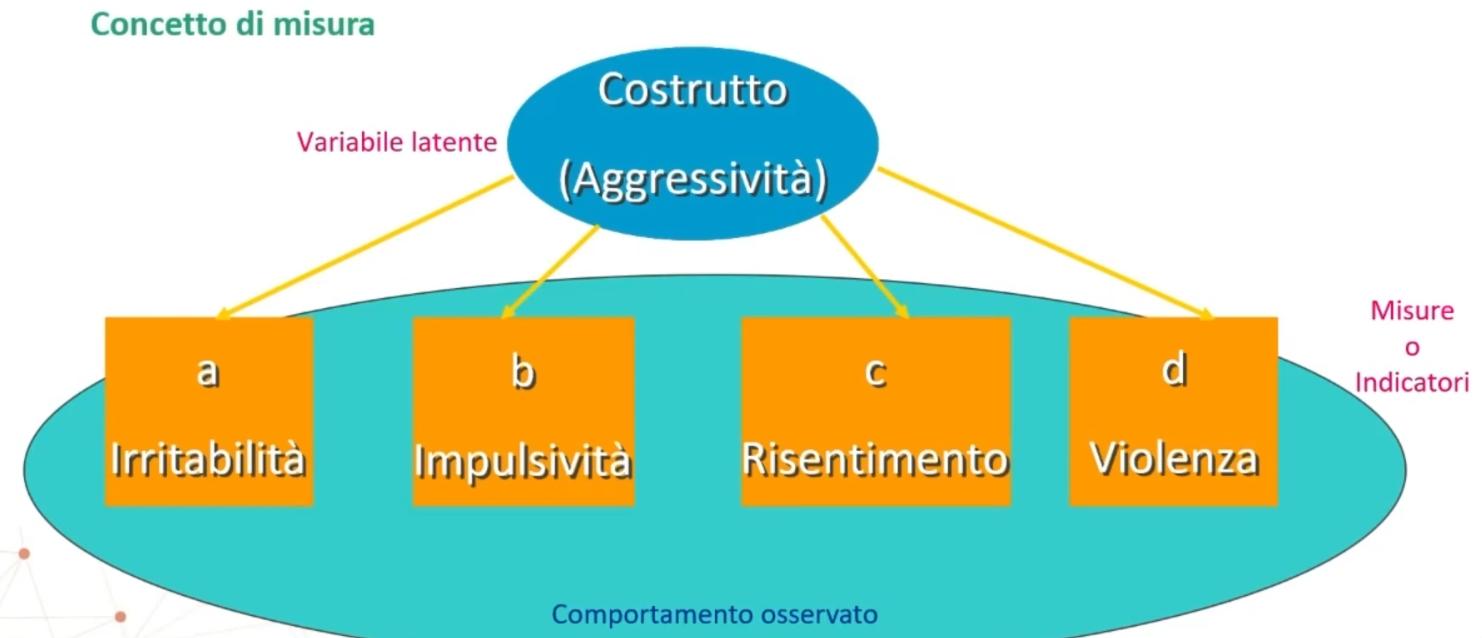
Le variabili psicologiche sono tutte di tipo intensivo e vengono chiamate costrutti (o costrutti latenti): sono astrazioni teoriche che vengono inferite a partire dall’osservazione del comportamento. Tali grandezze sono comunque graduabili e dunque misurabili.
Visivamente, possiamo immaginare il costrutto (variabile latente, es. Aggressività) che si manifesta attraverso misure o indicatori del comportamento osservato (es. Irritabilità, Impulsività, Risentimento, Violenza).
Se volessimo misurare il costrutto «aggressività» dovremmo seguire questi passaggi:
definire «teoricamente» ciò che intendiamo per aggressività;
decidere «cosa» osservare del comportamento (definizione operativa);
stabilire «come» quantificare il comportamento (es. numero di volte che si presenta o la sua intensità);
decidere gli strumenti di misura che permettono di quantificare il costrutto.
La difficoltà principale risiede nello stabilire una relazione univoca tra il sistema empirico (comportamento osservato) e quello numerico (quantificazione del comportamento). Tale relazione non è naturale ma convenzionale e teorica. Il ricercatore deve scegliere, tra le proprietà dei numeri e gli strumenti, quelli che teoricamente si adattano meglio alle caratteristiche del costrutto. In questo processo esiste sempre un margine di incertezza o imprecisione, definito errore casuale di misurazione.
Cosa e come misuriamo
La base della misurazione in psicologia è l’osservazione del comportamento (quantificare le osservazioni oggetto di studio).
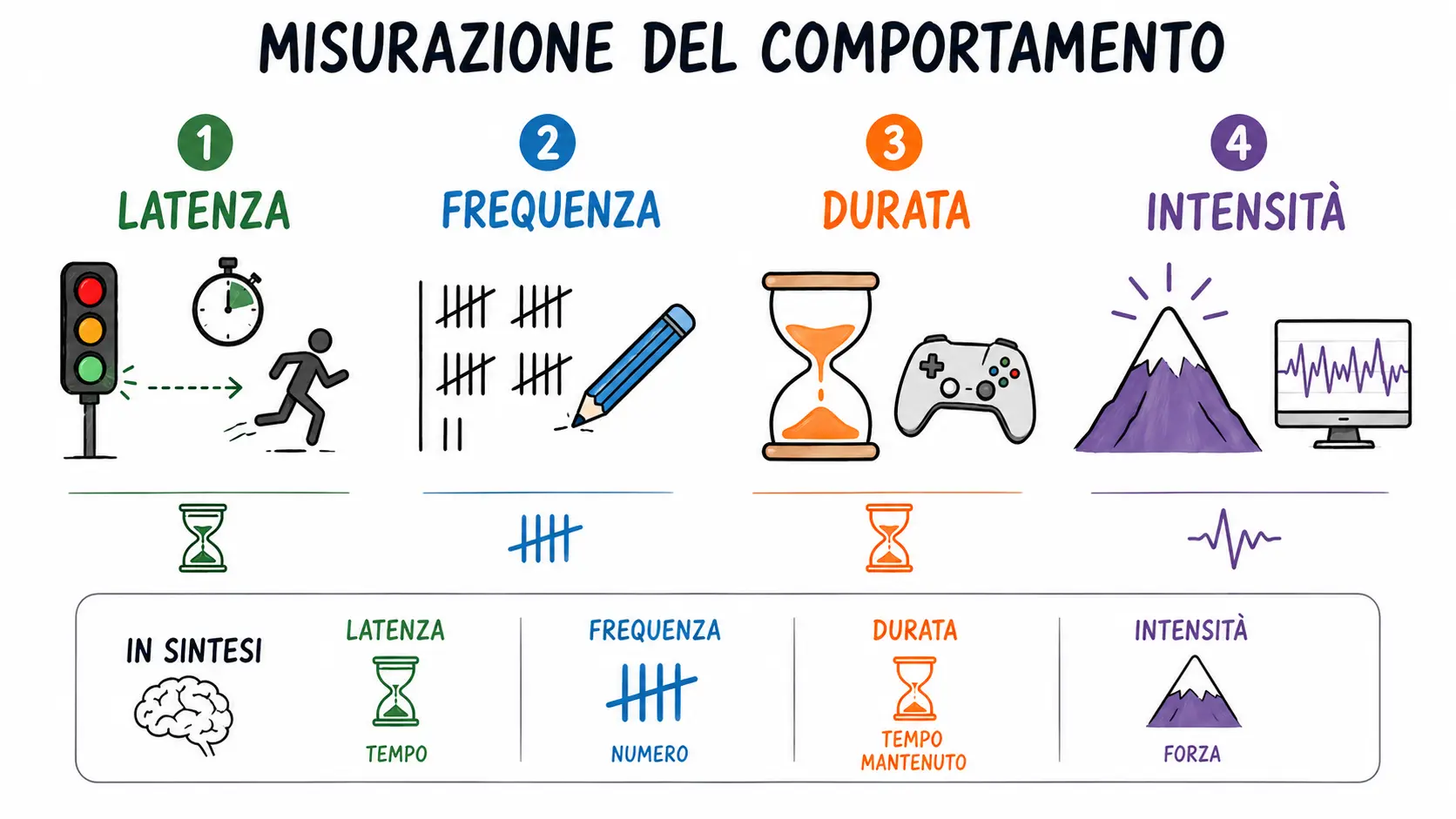
Le osservazioni si basano su quattro elementi fondamentali:
LATENZA: corrisponde all’intervallo di tempo che intercorre tra la presentazione di uno stimolo e il verificarsi di uno specifico evento (ovvero la risposta). Un esempio è la misurazione dei tempi di reazione durante la somministrazione del test di Rorschach, in cui si registra il tempo che passa tra la presentazione di una tavola e la prima risposta del soggetto.
FREQUENZA: corrisponde al numero di volte in cui si presenta un determinato evento.
DURATA: corrisponde alla quantità di tempo in cui un singolo comportamento viene mantenuto.
INTENSITÀ: corrisponde al grado di forza con cui si produce o manifesta un fenomeno psicologico. È l’elemento più difficile da definire e misurare, ed è spesso confusa con la frequenza. Esempi di intensità sono i picchi delle onde cerebrali o i valori rilevati nelle scale di atteggiamento.
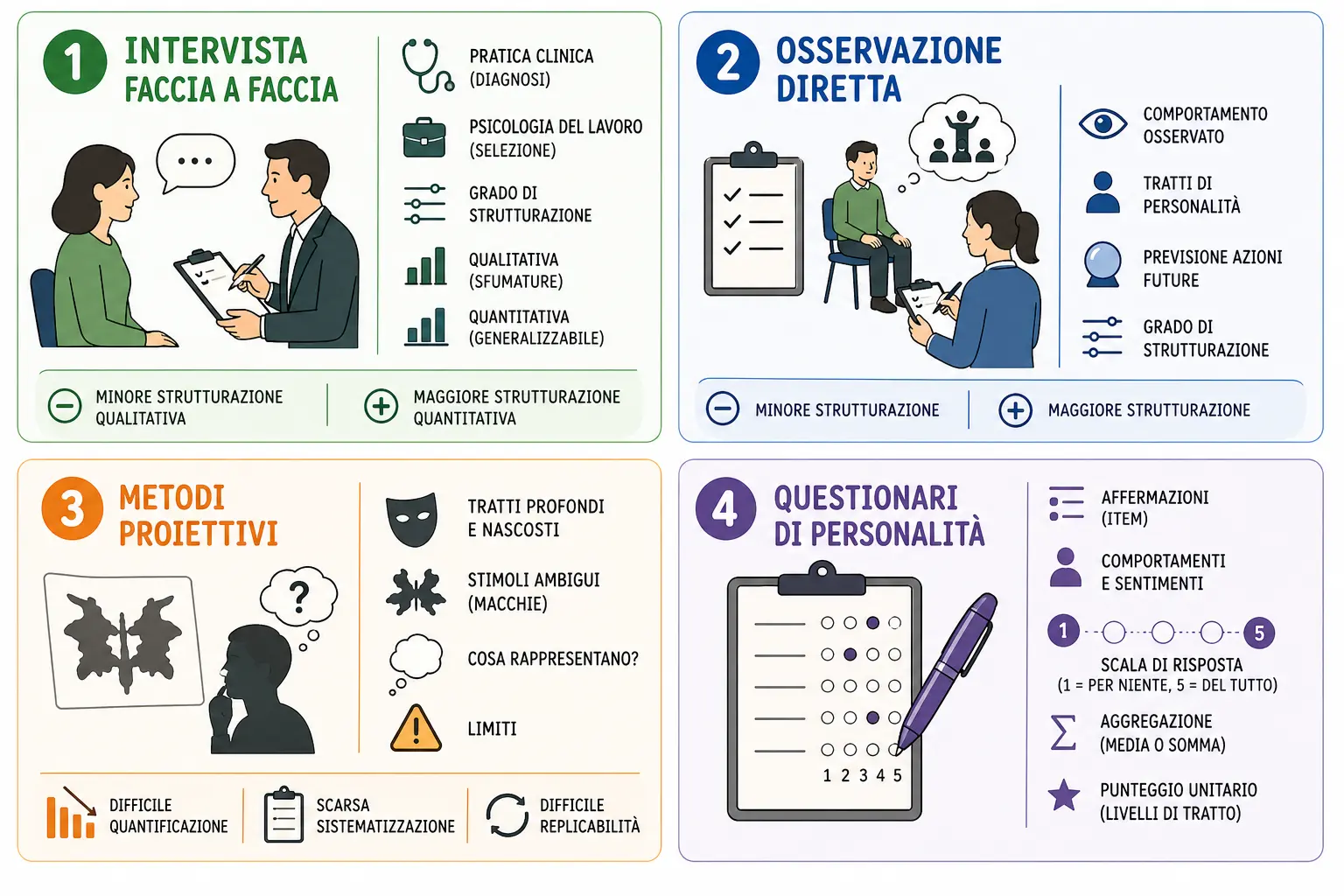
I test psicologici
I principali strumenti utilizzati per indagare i concetti psicologici sono i test psicologici, il cui scopo principale è misurare le caratteristiche oggetto di interesse.
I tes possono essere:
TEST COGNITIVI: le risposte vengono valutate su parametri oggettivi di correttezza (giusto/sbagliato).
TEST NON COGNITIVI: le risposte vengono interpretate come autodescrizione del comportamento ed opinioni individuali. Esempi di questa tipologia sono i test di personalità e le scale di atteggiamento.
I test cognitivi
Possono essere:
I Test di abilità sono una serie di problemi che misurano le capacità degli individui in specifici ambiti cognitivi, come quello verbale, matematico o spaziale. Sono utilizzati prevalentemente in ambito scolastico.
I Test di intelligenza sono prove che hanno lo scopo di misurare le abilità generali di ragionamento.
I Test di profitto sono una serie di quesiti che misurano il grado di padronanza di un insieme di cognizioni. Si differenziano dai test di intelligenza e di abilità per una maggiore contestualizzazione: si concentrano infatti sul grado di competenza raggiunto in una specifica materia piuttosto che su capacità astratte. Sono usati soprattutto in ambito educativo.
I Test attitudinali hanno l’obiettivo di fornire una stima della performance futura di un individuo. La differenza sostanziale rispetto ai test di abilità risiede nel fatto che questi ultimi misurano la competenza presente, mentre i test attitudinali mirano a predire quella futura.
I test non cognitivi
I test di personalità partono dal presupposto teorico che il comportamento e le sue diverse forme siano riconducibili a caratteristiche personali dell’individuo, denominate tratti.
L’obiettivo è misurare questi tratti attraverso:
L’intervista faccia a faccia è un metodo molto usato nella pratica clinica (es. diagnosi) e nella psicologia del lavoro (es. selezione). Può essere condotta con diversi gradi di strutturazione:
Un minore grado di strutturazione porta a una descrizione qualitativa della personalità, utile per cogliere sfumature peculiari.
Un maggiore grado di strutturazione porta a una descrizione quantitativa, capace di fornire informazioni generalizzabili a più individui.
L’osservazione diretta assume che i tratti di personalità regolino le modalità del comportamento individuale. Osservando il comportamento è possibile stabilire le caratteristiche tipiche di una persona e prevederne le azioni future.
I metodi proiettivi, sviluppati originariamente per i disturbi di personalità, si propongono di rilevare tratti profondi e nascosti. Consistono nel mostrare una serie di stimoli ambigui (come macchie di inchiostro) chiedendo al soggetto cosa rappresentano. Tuttavia, presentano numerosi limiti quali una difficile quantificazione, scarsa sistematizzazione e difficile replicabilità.
I questionari di personalità consistono in una serie di affermazioni (chiamate item) che riguardano comportamenti e sentimenti. Si chiede al rispondente di indicare il grado in cui un determinato comportamento è adatto a descriverlo, solitamente attraverso una scala di risposta (es. da 1 «non mi descrive per niente» a 5 «mi descrive del tutto»). Le risposte ai singoli item vengono aggregate (tramite media o somma) ottenendo un punteggio unitario che delinea i livelli di uno specifico tratto.
Scala di atteggiamento
Le scale di atteggiamento misurano il grado di favore/sfavore verso un oggetto o comportamento. (come il grado di favore o sfavore verso un partito politico o il fumo).
L’atteggiamento ha un ruolo centrale nella ricerca perché è considerato uno dei maggiori predittori del comportamento (ad esempio, avere un atteggiamento favorevole verso un prodotto rende più probabile l’acquisto).
Tra le principali tipologie troviamo:
Scala Thurstone è composta da una serie di affermazioni che descrivono vari gradi di favore o sfavore verso un oggetto. È poco utilizzata perché richiede una fase di preparazione complessa
Scala Guttman prevede una serie di affermazioni ordinate secondo un criterio di favore crescente. Anche questa è poco utilizzata
Scala Likert è costituita da affermazioni che esprimono un atteggiamento positivo o negativo verso un oggetto. Si richiede al soggetto di indicare il proprio grado di accordo con ogni frase utilizzando una scala graduata, solitamente a 5 o 7 passi (ad esempio, posizionandosi tra “in disaccordo” e “in accordo” rispetto alla frase «fumare è piacevole»).
Scala del differenziale semantico utilizza una lista di aggettivi semanticamente contrapposti (come buono vs cattivo, o positivo vs negativo) posti agli estremi di una scala graduata, generalmente a 5 o 7 passi. Il rispondente descrive la propria valutazione dell’oggetto posizionandosi lungo la scala tra i due aggettivi opposti.
Concetto di validità
La VALIDITÀ è la capacità di uno strumento di cogliere effettivamente la caratteristica o il costrutto che intende misurare, e non altri. Poiché i costrutti psicologici non sono direttamente osservabili, ma vengono misurati attraverso i comportamenti che ne sono una manifestazione, è fondamentale dimostrare che tali comportamenti riflettano il costrutto in modo valido. Verificare la validità è un processo complesso basato su prove indirette e deduzioni logiche.
Il processo di verifica consiste nel constatare che la misura si inserisca coerentemente in una rete di relazioni che rappresenta il significato del costrutto. Questo processo richiede il soddisfacimento di diverse condizioni:
La VALIDITÀ DI CONTENUTO si riferisce alla capacità dello strumento di rappresentare accuratamente l’universo dei comportamenti legati al costrutto che si vuole misurare. Non si basa su criteri statistici, ma sul giudizio di esperti del settore. Assume un rilievo particolare nei test di accertamento e profitto, dove è fondamentale coprire in modo esaustivo le competenze indagate.
La VALIDITÀ DI COSTRUTTO accerta la precisione delle definizioni operative, evitando confusioni con costrutti diversi. Si compone di due aspetti distinti:
Validità convergente: esprime il grado di accordo tra diversi tentativi di misurare lo stesso costrutto (es. due diverse misure di depressione devono risultare fortemente associate).
Validità discriminante: esprime il grado di disaccordo tra i tentativi di misurare costrutti diversi (es. una misura di depressione non deve essere associata, o deve esserlo negativamente, a una misura di ottimismo).
La VALIDITÀ DI CRITERIO rappresenta il grado di associazione tra la misura del costrutto d’interesse ed un criterio rilevante (un concetto teoricamente connesso). Anche questa si divide in due aspetti:
Validità concorrente: criterio e costrutto sono rilevati nello stesso momento temporale. Non dipendono l’uno dall’altro ma sono aspetti diversi di uno stesso fenomeno (es. una misura di ansia associata ad una di depressione).
Validità predittiva: il criterio è rilevato in un momento temporale successivo. Il costrutto di interesse spiega o predice il criterio (es. un atteggiamento favorevole verso un prodotto predice il futuro acquisto).
La VALIDITÀ NOMOLOGICA è la forma più generale e astratta. Corrisponde al grado in cui l’insieme delle ipotesi basate sulla misura del costrutto vengono verificate all’interno di un vasto schema concettuale (rete di relazioni teoriche). Può essere vista come un’estensione su larga scala della validità di criterio: riassume un complesso di associazioni tra il costrutto e una molteplicità di criteri (es. la depressione si associa all’ansia, si contrappone all’ottimismo e predice tendenze suicidarie).
In sintesi, da un punto di vista scientifico ogni aspetto della validità è fondamentale, con la validità nomologica che riveste un ruolo primario nella ricerca di base.
Tuttavia, da un punto di vista applicativo, si possono privilegiare aspetti specifici in base allo scopo:
la validità di contenuto è essenziale nei test di profitto;
la validità di costrutto è centrale nei test diagnostici (per non confondere diagnosi diverse);
la validità di criterio è prioritaria quando si vuole predire un comportamento a rischio (es. consumo di stupefacenti).