Table of Contents
Distribuzione di probabilità
I possibili risultati di un esperimento costituiscono uno spazio campionario di n eventi. A ciascun evento possiamo associare la probabilità del suo verificarsi.
La distribuzione di probabilità ci offre la posibilità di definire tutti i possibili risultati e le corrispondenti probabilità.
Gradi di libertà (gdl)
I gradi di libertà sono quante cose puoi scegliere liberamente, dopo aver rispettato i vincoli.
Immagina di avere dei numeri che devono soddisfare una regola.
- Se non ci sono vincoli, puoi scegliere tutti i valori liberamente → tanti gradi di libertà.
- Se ci sono vincoli, ogni vincolo “toglie libertà” → meno gradi di libertà.
Esempio ho 3 numeri che devono sommare a 10.
- Puoi scegliere liberamente i primi due (es. 3 e 4)
- Il terzo è obbligato (deve essere 3 per arrivare a 10)
Quindi: 3 numeri – 1 vincolo = 2 gradi di libertà
Consideriamo N osservazioni tutte indipendenti, ognuna libera di assumere qualsiasi valore, in questo caso i gdl sono N.
Tuttavia, se vengono imposti dei vincoli, per esempio che la somma = 20, allora i gdl diventano N-1 vincolo. Per cui, se N=5, gdl saranno 5-1, cioè 4.
In generale, i gradi di libertà sono il numero di elementi liberi di variare – il numero di vincoli.
Distribuzione chi quadro χ²
La distribuzione chi-quadro serve per misurare “quanto i dati osservati si discostano da quelli attesi”.
Hai sempre due cose:
- frequenze osservate (quello che vedi nei dati)
- frequenze attese (quello che ti aspetteresti se non ci fosse effetto)
La chi-quadro misura quanto sono grandi le differenze tra queste due. Come interpretare il dato:
- χ² piccolo → osservato ≈ atteso → nessuna differenza importante
- χ² grande → osservato ≠ atteso → c’è una differenza significativa
È una distribuzione di valori al quadrato e viene quindi definita solo sul semiasse positivo da 0 a +∞ nel seguente modo:
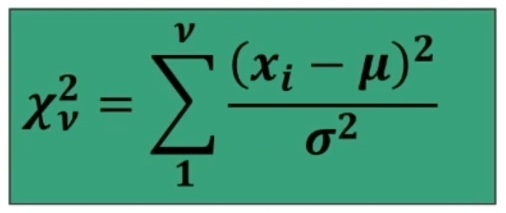
Dove μ e σ² sono media e varianza di una variabile normale casuale e ν (n in greco) è l’unico parametro che varia e corrisponde all’ampiezza del campione (numero di prove).
Data una distribuzione normale standardizzata (μ=0; σ=1) ho la seguente relazione con i punti z.
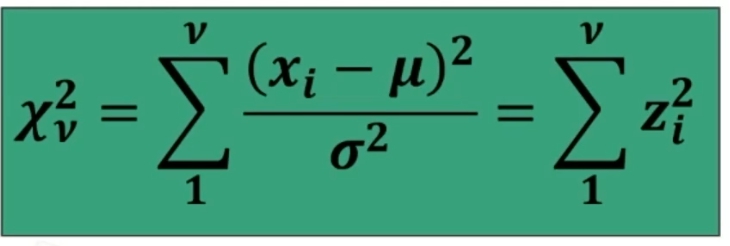
Se prendo dei valori standardizzati (cioè punti z) e li elevo al quadrato, ottieni una distribuzione chi-quadro.
All’aumentare di v=n (numero degli elementi del campione) ottengo le seguenti curve.
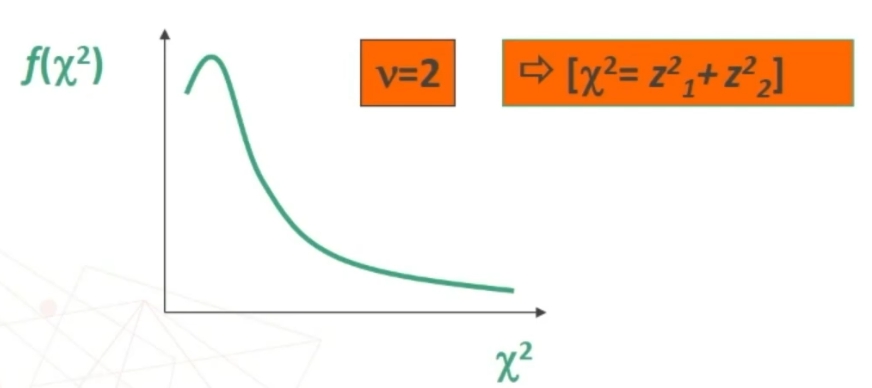
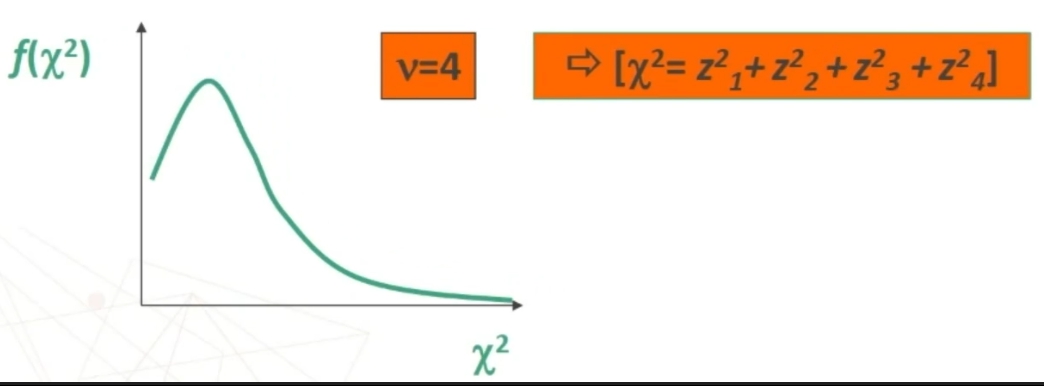
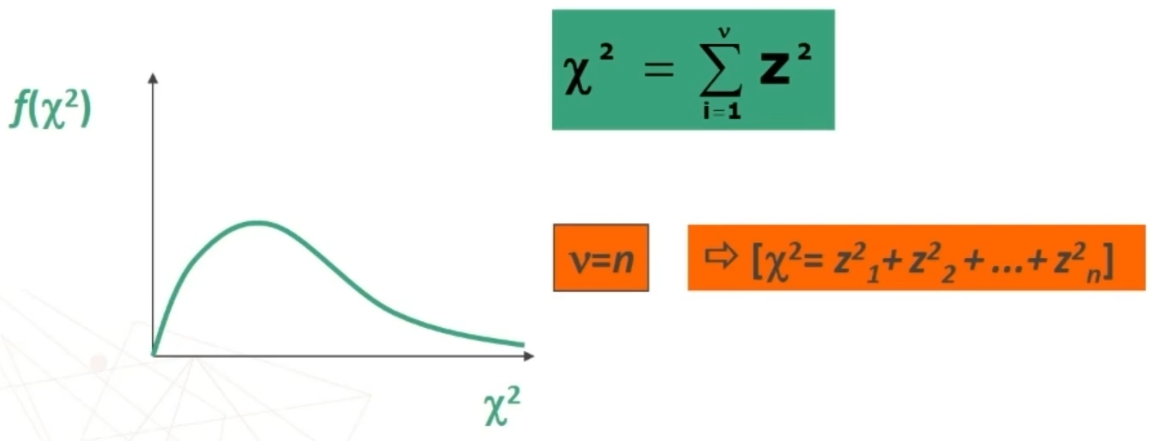
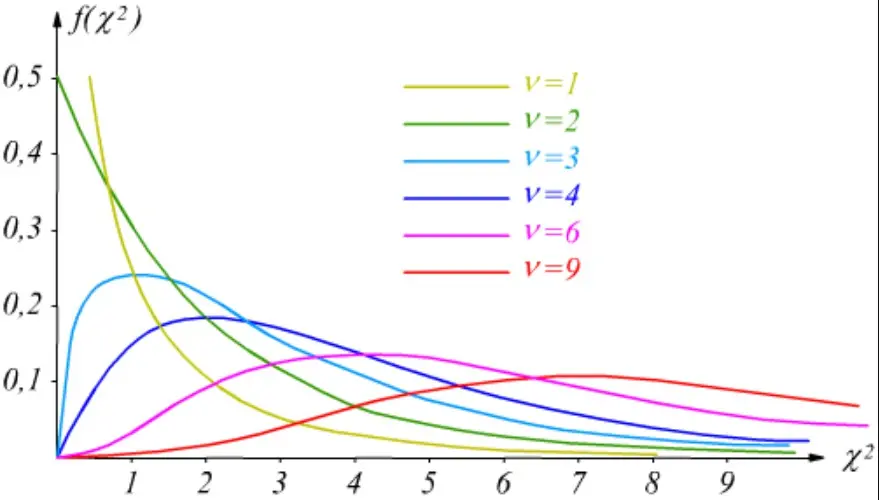
La curva:
- è una funzione continua che va da 0 a ∞ (entro il quadrante positivo degli assi cartesiani)
- La forma dipende da ν (al crescere dei gradi di libertà tende alla simmetria)
- Si usa la curva per calcolare la probabilità associata ai valori di χ² (porzioni di area), sapendo che la probabilità totale è 1, ovvero
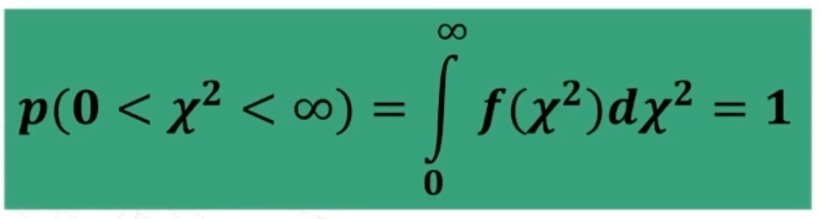
La distribuzione chi-quadro è la somma dei quadrati di valori indipendenti di una variabile normale standardizzata. Se tali valori NON sono indipendenti, bisogna stabilire quanti sono i vincoli che li condizionano. Se vi sono vincoli, il parametro ν della distribuzione, quindi, non coincide con il numero effettivo dei valori che generano la distribuzione. In questi casi esso coincide con i gradi di libertà (gdl) ossia con il numero dei valori veramente indipendenti che generano la distribuzione.
Facciamo un esempio, i gradi di libertà sono dati dal numero di valori liberi di variare entro un’equazione n₁ + n₂ + n₃ = N con k=3 (n* addendi)
- Se N non è fisso, tutti gli addendi sono liberi di variare: ν = k
- Se N è fisso, tutti gli addendi sono liberi di variare meno uno: ν = k – 1
Esempio
Esempio: n₁ + n₂ + n₃ = 20 → gdl = k – 1 = 3 – 1 = 2. Infatti, due sono gli addendi liberi di variare, il terzo è vincolato al totale che deve essere 20

Se considero 10+9 per arrivare a 20 il terzo addendo è vincolato e vale per forza 1. Nella seconda riga 8+3+9 il terzo addendo 9 è vincolato se la somma è 20. Lo stesso dicasi anche per la terza riga. (fine esempio)
Anche nel caso di questa distribuzione è possibile calcolare l’area sotto la curva. I valori sono stati tabulati per proporzioni di area di probabilità e gdl.
- le righe corrispondono ai gdl
- le colonne a diverse aree di probabilità cumulate (P) prefissate.
All’incrocio di riga x colonna viene riportato il valore del χ² corrispondente.
Esempio
Ad esempio: ho gdl = 3 e la proporzione di area di prob. che ci interessa = 0.05

All’incrocio fra gdl=3 e area 0.05 si trova χ² critico, cioè quello che lascia alla sua destra il 5% dei casi e alla sua sinistra il 95%. Ciò vuol dire che, estraendo a caso un campione di n=3, e calcolando il χ² critico, si ha una probabilità P(χ² > 7.82) = 0.05
7.82 è il valore soglia (χ² critico) e ciò vuol dire che se i dati fossero dovuti al caso, solo il 5% delle volte otterresti un valore di χ² maggiore di 7.82
Immagina di ripetere l’esperimento tantissime volte:
- nel 95% dei casi → χ² sarà ≤ 7.82
- nel 5% dei casi → χ² sarà > 7.82
👉 Quindi 7.82 separa:
- zona “normale” (sinistra)
- zona “rara” (destra)
Nei casi reali calcolo il χ² dai dati (esempio: 6 oppure 10) e poi lo confronti con 7.82
Caso 1: χ² = 6 → più piccolo di 7.82 👉 risultato normale → non significativo
Caso 2: χ² = 10 → più grande di 7.82 👉 risultato raro → significativo
Nella pratica tale procedimento è utile nella verifica delle ipotesi.
Pearson dimostra che considerando una distribuzione di frequenza con f0 (frequenze osservate), ft (frequenze teoriche) e k (numero categorie della istribuzione) abbiamo che

Ogni volta si debba confrontare una distribuzione teorica e una osservata si può fare riferimento alla distribuzione teorica di probabilità del χ².
Disponendo di una distribuzione di frequenza è possibile usare il χ² per la VERIFICA DELL’IPOTESI.
(Prevalentemente il χ² si usa quando si hanno variabili su scala non metriche)
Distribuzione F di Fisher
La distribuzione F serve per confrontare due variabilità (varianze). In altre parole mi dice se due gruppi sono diversi davvero oppure se la differenza è solo casuale.
Esempio: Ho 3 classi con risultati di un test:
- se i punteggi medi sono simili → F piccolo
- se una classe è molto diversa → F grande
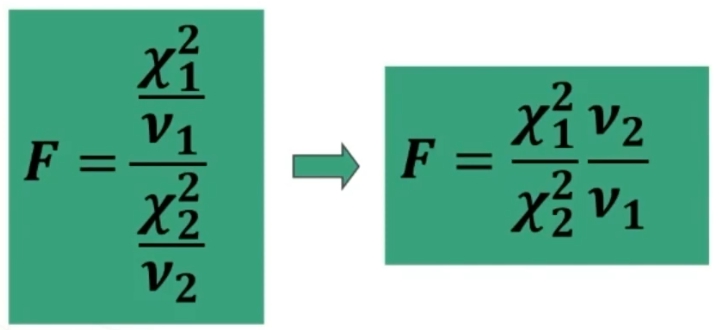
La distribuzione teorica F di Fisher (o Snedecor) è definita dal rapporto tra χ² indipendenti.
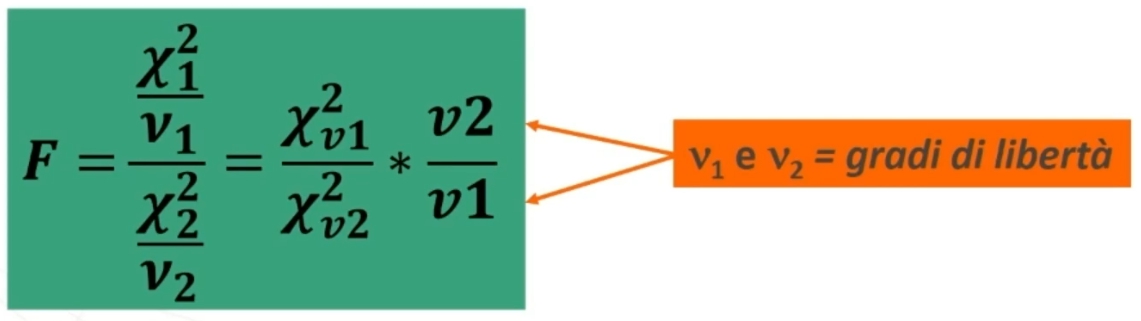
Da questa distribuzione possiamo ottenere delle famiglia di distribuzioni che variano al variare dei parametri ν1 e ν2.
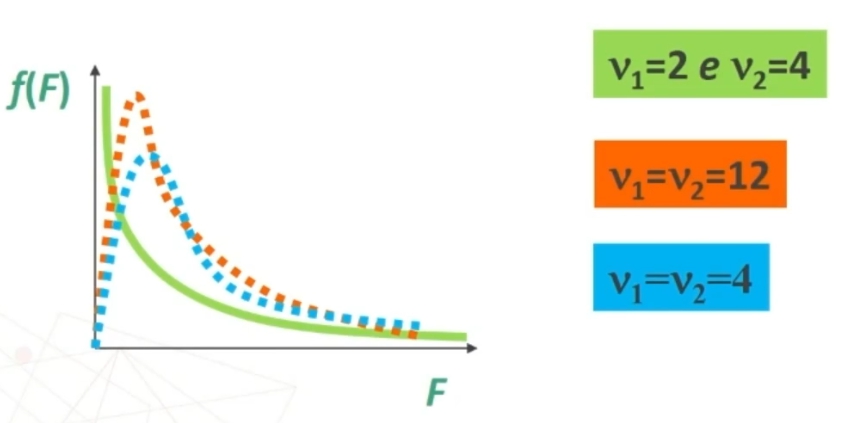
La forma della funzione di Fiscer dipende da ν1 e ν2. Inoltre la funzione è continua, che va da 0 a ∞ (entro il quadrante positivo degli assi cartesiani).
Si usa la curva per calcolare la probabilità associata ai valori di F (porzioni di area), sapendo che:
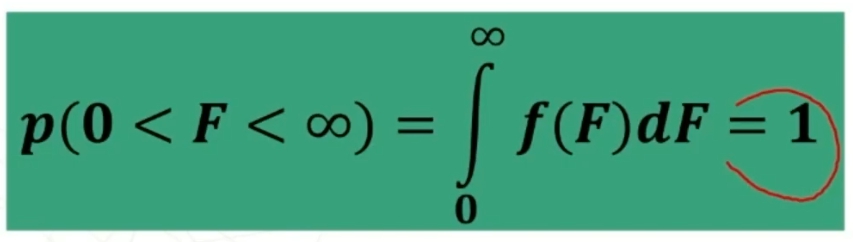
La curva definisce una distribuzione di probabilità, e tale distribuzione F è definita da:
Anche le distribuzioni F sono tabulate.
È possibile, fissati i due parametri ν1 e ν2, conoscere il valore F in corrispondenza alle probabilità p=.05 e p=.01
Nella tavola, all’incrocio delle coppie ν1, ν2 si trovano due valori: sopra gli F critici allo 0.05 e sotto allo 0.01.
Esempio
Per esempio voglio stimare il valore di un F critico, alla probabilità di 0.05 e 0.01, per due chi quadrati con gradi di libertà 5 (per il primo) e 10 (per il secondo). Incrociando come si vede nell’immagine si vedono due righe, la prima riga relativa a F 0.05, la seconda a F 0.01.
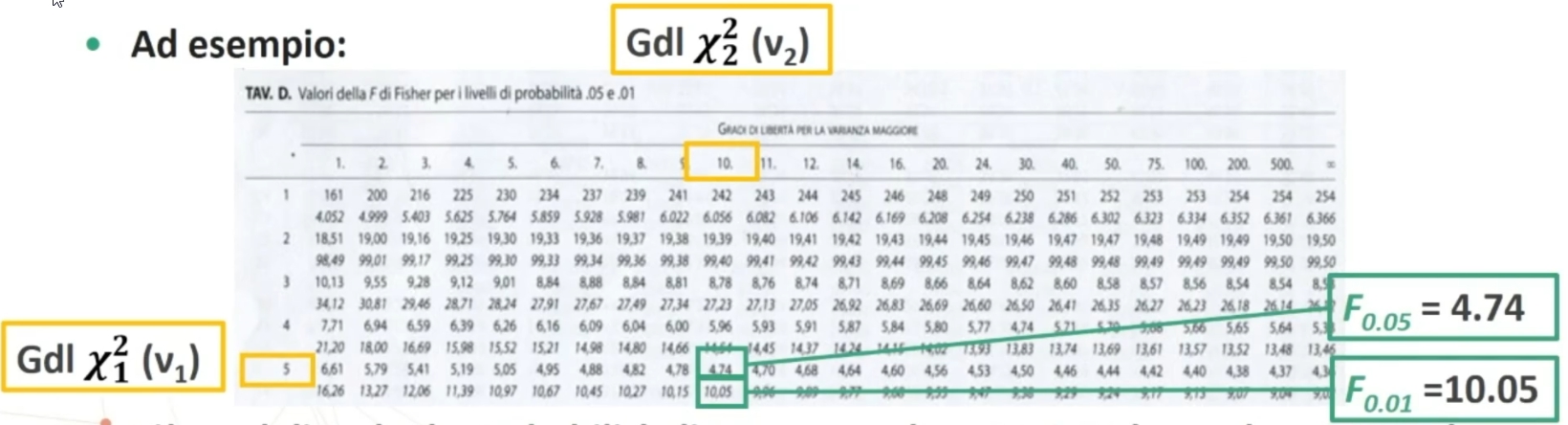
Ciò vuol dire che la probabilità di avere un valore F ≥ 4.74 è uguale a 0.05 e che la probabilità di avere un valore F ≥ 10.05 è uguale a 0.01.
Distribuzione t di Student
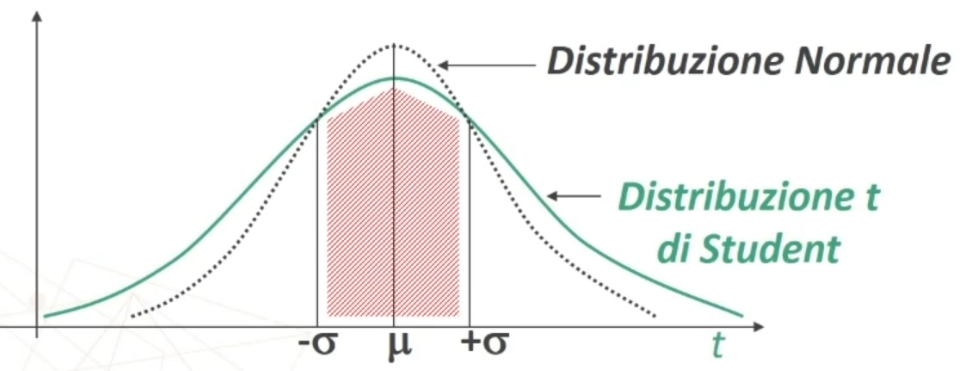
Se avessimo campioni enormi (es. N > 100), useremmo quasi sempre la distribuzione Normale. Ma in psicologia spesso lavoriamo con gruppi piccoli (es. 20 persone che seguono un trattamento).
Quando il campione è piccolo, non conosciamo la vera deviazione standard della popolazione e dobbiamo stimarla partendo dai dati del campione. Questa stima introduce un’incertezza extra. La distribuzione t è stata “inventata” proprio per correggere questa incertezza.
Se n < 30, la distribuzione delle medie dei campioni è del tipo t di Student. Questa distribuzione ha le seguenti caratteristiche (in modo simile alla normale):
- Infinità (da meno a più infinito)
- Simmetrica (rispetto al valore centrale)
- Unimodale (media moda e mediana corrispondono)
- Asintotica (non tocca ma l’asse ascisse)
Rispetto alla normale la varianza sarà maggiore. Questo perchè n < 30 (campioni piccoli) e quindi maggiore dispersione. Inoltre la curva sarà più appiattita e code più lunghe (ad esempio la porzione di area compresa tra ±1σ dalla media sarà minore del 68%)
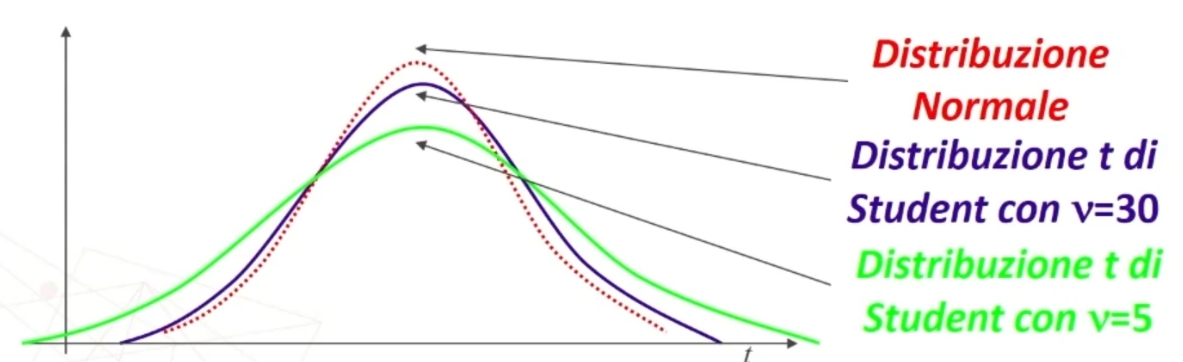
La forma della distribuzione t di Student varia secondo la dimensione n dei campioni. Questo è il parametro che la fa variare.
Ciascuna distribuzione t è definita dai parametri μ (media), σ (deviazione standard) e ν = gradi di libertà.
La t è quindi una famiglia di distribuzioni legate al numero di ν = gradi di libertà (all’aumentare di ν la distribuzione tende alla normale).
Come per la normale abbiamo:
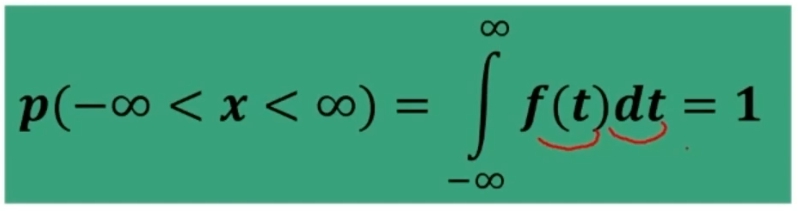
Inoltre la curva definisce una distribuzione di probabilità, e nello specifico tale distribuzione di probabilità t è definita dall’indicatore:

Abbiamo che
- Il numeratore rappresenta la differenza pura tra quello che hai osservato nel tuo esperimento e quello che ci si aspetterebbe teoricamente. Più questa differenza è grande, più il valore di t cresce.
- al denominatore, poiché non conosciamo la vera variabilità della popolazione, usiamo la deviazione standard del campione (s) corretta per la numerosità del campione (n).
Anche per questa distribuzione abbiamo delle tavole. In questo caso le righe corrispondono ai gradi di libertà (gdl) e le colonne a diverse aree di probabilità prefissate. Inoltre, nelle tabelle appaiono due diciture:
- Ipotesi monodirezionale → questo sta ad indicare che il valore p, al quale noi facciamo riferimento, riguarda un’unica estremità della curva (a una coda)
- Ipotesi bidirezionale → in qiesto caso il valore p è equamente diviso nelle due estremità della curva (a due code)
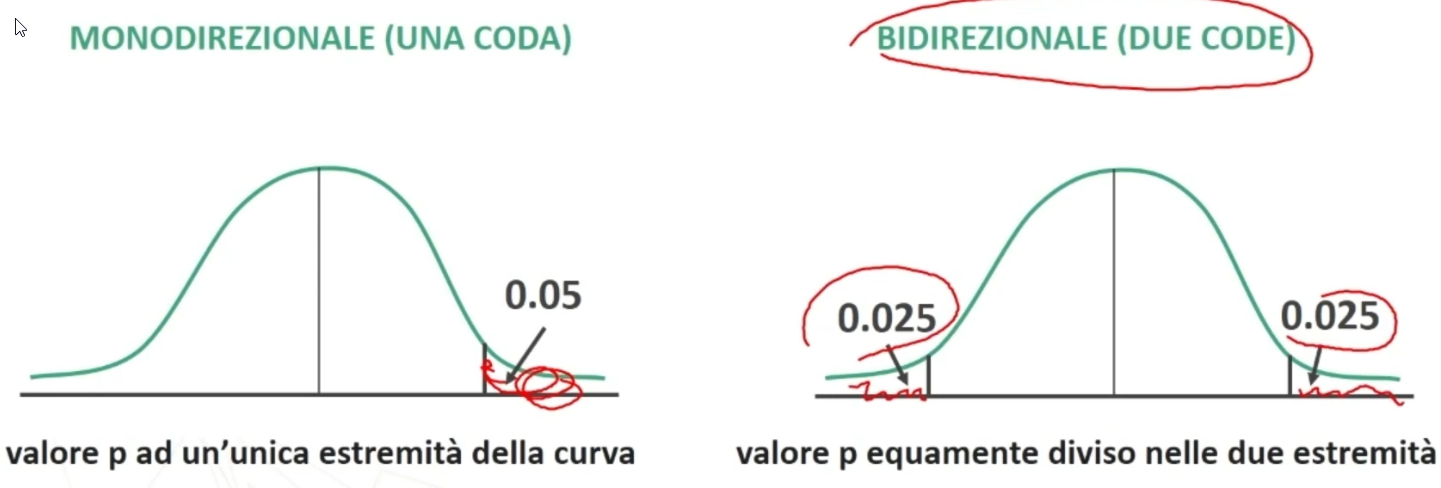
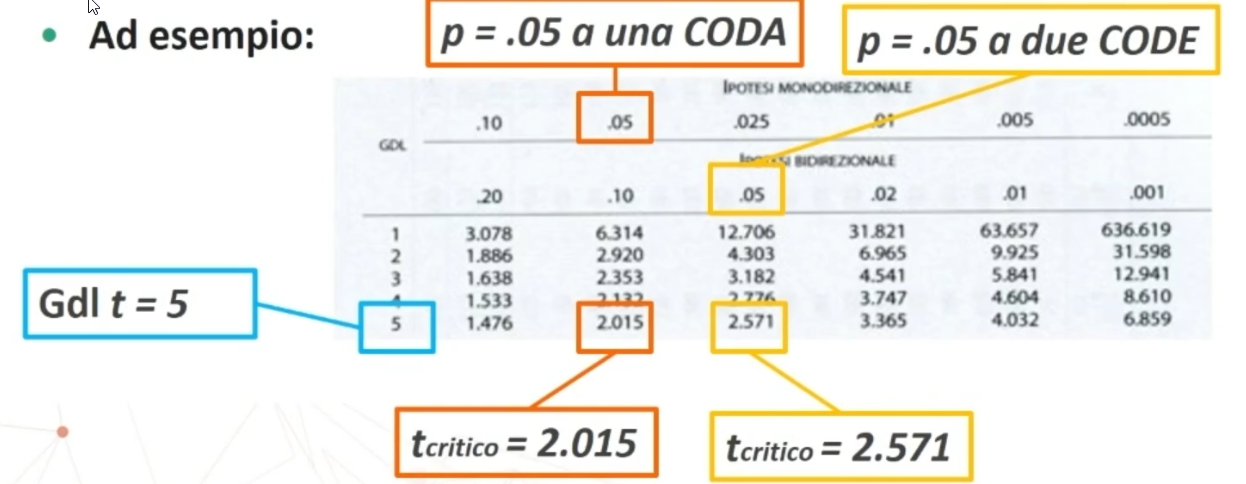
Ad esempio:
- p=0.05 a una coda
- p=0.05 a due code
(Nell’immagine è mostrato un esempio di tavola con tcritico=2.015 per ipotesi monodirezionale, e tcritico=2.571 per ipotesi bidirezionale con gdl = 5).