Table of Contents
Introduzione – Campioni indipendenti
Campioni indipendenti sono campioni estratti casualmente dalla popolazione con caratteristiche omogenee.
In questo caso l’assegnazione avviene in modo casuale, alle diverse condizioni sperimentali. Ovvero sono due gruppi indipendenti uno sottoposto a trattamento (gruppo sperimentale) e uno no (gruppo di controllo).
Questa è definita Situazione sperimentale classica, o esperimento.
In entrambi i casi ho una variabile Trattamento che può assumenre due livelli (si/no). Questa è una variabile indipendente e manipolata.
Oppure potremmo avere due gruppi indipendenti sottoposti a trattamento, ma questo trattamento è diverso (esemio gruppo sperimentale 1 e gruppo sperimentale 2).
In questo caso abbiamo due gruppi sperimentali. La variabile indipendente in questo caso sarà trattamento 1 oppure trattamento 2. Anche in questo caso avremo a che fare con una variabile indipendente e manipolata.
In tutti i casi andremo a rilevare la variabile dipendente dopo aver fatto il trattamento. Dunque l’analisi statistica sarà mirata a rilevare le differenze nella variabile dipendente, ascrivibili alla indipendente.
Esempio A
Vengono estratti in modo casuale tra gli impiegati di una grande azienda 80 soggetti. Vengono casualmente assegnati a due gruppi: gruppo sperimentale (segue un corso di aggiornamento) e gruppo di controllo (nessun aggiornamento)
Abbiamo che:
- var indipendente (manipolata): Aggiornamento sì/no
- var dipendente: Rilevazione del rendimento di entrambi i gruppi
Esempio B
Estrazione casuale tra gli impiegati di una grande azienda di 80 soggetti. Assegnazione casuale a due gruppi: gruppo sperimentale 1 (segue un corso di aggiornamento) e gruppo sperimentale 2 (viene affiancato da un impiegato con esperienza decennale)
- var indipendente (manipolata): Aggiornamento/Affiancamento
- var dipendente: Rilevazione del rendimento di entrambi i gruppi
Un’altra possibilità è quella di avere campioni estratti casualmente da due sub-popolazioni con caratteristiche omogenee eccetto una, quella che li distingue (esempio maschi e femmine). In questo caso l’assegnazione NON è casuale alle diverse condizioni sperimentali.
In questo caso avremo una SITUAZIONE SPERIMENTALE o QUASI ESPERIMENTO.
La variabile indipendente si/no non è manipolata (il ricercatore non ha effettuato nessuna operazione sulla variabile indipendente, ha semplicemente estratto, in base a una caratteristica, due gruppi diversi).
Non c’è invece alcuna differenza sul modo in cui andiamo a rilevare la variabile indipendete, su entrambi i gruppi in esame. E l’analisi statistica avrò lo scopo di rilevare differenze a livello di V. Dipendete ascrivibili alla V. indipendente.
Esempio (QUASI ESPERIMENTO):
Vengono estratti in modo casuale tra gli impiegati di una grande azienda 40 soggetti con esperienza lavorativa di meno di 5 anni (gruppo sperimentale 1) e 40 soggetti con un’esperienza lavorativa di più di 5 anni (gruppo sperimentale 2)
- VARIABILE INDIPENDENTE (manipolata): Esperienza +5/-5
- VARIABILE DIPENDENTE: Rilevazione del rendimento di entrambi i gruppi
In tutti i casi citati si parla di disegni sperimentali o quasi sperimentali tra soggetti (o between).
I disegni descritti per due campioni possono essere estesi a k campioni.
Verifica delle ipotesi – Campioni indipendenti
Quando confronto due gruppi (variabile indipendente), composti da diverse persone su una data misura (variabile dipendente), sto confrontando due campioni indipendenti.
Quando la variabile dipendente è metrica, devo confrontare la media dei due campioni.
A seconda della numerosità dei due campioni e della conoscibilità della deviazione standard delle popolazioni, devo usare tecniche diverse.
Quando ho noti i seguenti dati
- POPOLAZIONI CON σ NOTA
- 2 CAMPIONI INDIPENDENTI n > 30
- Abbiamo una variabile metrica (possiamo usare le medie)
si ricorre all’utilizzo della distribuzione campionaria della differenza tra medie, e il confronto verrà fatto (verifica dell’ipotesi) con la distribuzione di probabilità normale.
Vediamo i 5 passaggi da effettuare
- Scelta del test statistico (di significatività): Si calcola z facendo riferimento alla dCDM (distribuzione campionaria differenza tra medie)
- Definzione dell’ipotesi: Il confronto è tra le due popolazioni di riferimento
- ipotesi nulla H₀: μ₁ = μ₂ (μ₁ – μ₂ = 0) la media tra le due popolazioni ci aspettiamo siano uguali
- ipotesi alternativa H₁: μ₁ ≠ μ₂ (bidirezionale) le due medie sono diverse, oppure se monodirezionale possiamo affermare che μ₁ > μ₂, oppure μ₁ < μ₂
- Fissare il livello di significatività α: Si delinea la regione di rifiuto secondo α e H₁ (mono/bidirezionale) trovando uno zcritico sulla Tavola (come nel caso di un campione)
- Associare una probabilità ad H₀: Si associa una probabilità ad H₀, ottenendo una differenza standardizzata delle medie in oggetto

5. Decisione su H₀ (⇒ H₁): facciamo Il confronto avviene tra z e zcritico
- Se |z| < |zcritico| = p > α ⇒ Si accetta H₀ ⇒ è vera l’ipotesi nulla
- Se |z| > |zcritico| = p < α ⇒ Si rifiuta H₀ ⇒ Si accetta H₁ ⇒ è vera l’ipotesi alternativa
Nella vita reale però dobbiamo considerare che
- Le devianze standard delle popolazioni da cui estraiamo i campioni non le conosciamo quasi mai
- Se la misura è metrica, ed entrambi i campioni sono > 30, posso comunque utilizzare la dCDM assumendo che essa sia distribuita normalmente
Quindi se ci troviamo nella seguente condizione
- POPOLAZIONE CON σ IGNOTA
- 2 CAMPIONI INDIPENDENTI n > 30
- VARIABILE METRICA (posso usare MEDIE)
faremo riferimento alla dCDM e la verifica dell’ipotesi avverà con la distribuzione di probabilità normale.
I punti 1, 2, 3 e 5 sono analoghi al caso precedente con σ note. Per il punto 4 invece si associa una probabilità ad H₀, ottenendo una differenza standardizzata delle medie in oggetto → stima di σ, o s₁, o s₂
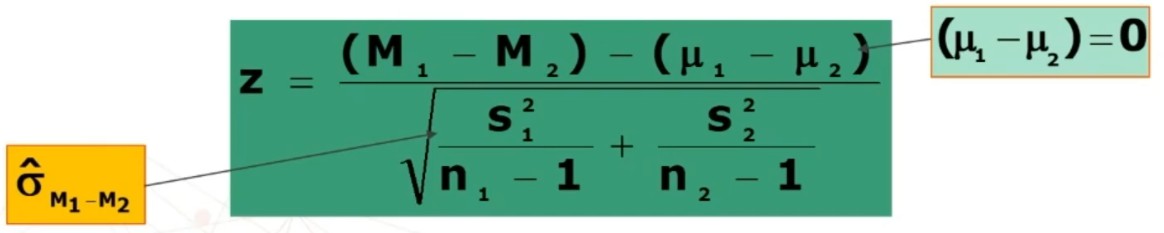
Quindi quando abiamo campioni indipendenti con n grandi e sigma ignota, con l’utilizzo di questa formula, posso verificare l’ipotesi a partire dai soli dati campionari:
- Si assume μ₁ – μ₂ = 0
- σ₁ e σ₂ vengono stimati
Questa infatti è la situazione più frequente (quasi mai si conosce i parametri della popolazione)
Esempio (σ IGNOTA, n > 30, MEDIE)
Seleziono in modo casuale 36 pazienti che hanno seguito per un certo periodo una terapia sperimentale e rilevo che la media dei sintomi ottenuta su una scala sintomatologica è 25.4 ± 1.7.
Seleziono in modo casuale 40 pazienti che hanno seguito invece una terapia tradizionale, si rileva che la media dei sintomi è 24.7 ± 0.9.
Possiamo affermare che vi sia una differenza di efficacia fra le due terapie?
1 Scelta del test statistico (di significatività)
Questi sono i dati di partenza
- 2 Campioni indipendenti:
- n₁ = 36 pazienti terapia sperimentale (n > 30)
- n₂ = 40 pazienti terapia tradizionale (n > 30)
- Campione 1: M₁ = 25.4, s₁ = 1.7; Campione 2: M₂ = 24.7, s₂ = 0.9
- VARIABILE INDIPENDENTE DICOTOMICA: Tipo di terapia (tradizionale e sperimentale)
- VARIABILE DIPENDENTE METRICA: Punteggio sintomatologia
Possiamo fare riferimento alla dCDM e utilizzare come distribuzione teorica di riferimento la distribuzione di probabilità normale (test z di differenza fra medie)
2. Definizione delle ipotesi:
Per le ipotesi avremo
- H₀: μ₁ = μ₂ (la media della popolazione dei pazienti trattati con la terapia sperimentale è uguale alla media dei pazienti sottoposti alla terapia tradizionale)
- H₁: μ₁ ≠ μ₂ (la media della popolazione dei pazienti trattati con la terapia sperimentale è diversa dalla media dei pazienti sottoposti alla terapia tradizionale)
Non avendo una ipotesi sulla direzione ci aspettiamo che l’ipotesi alternativa (H₁) sia BIDIREZIONALE. Poniamo α = .05
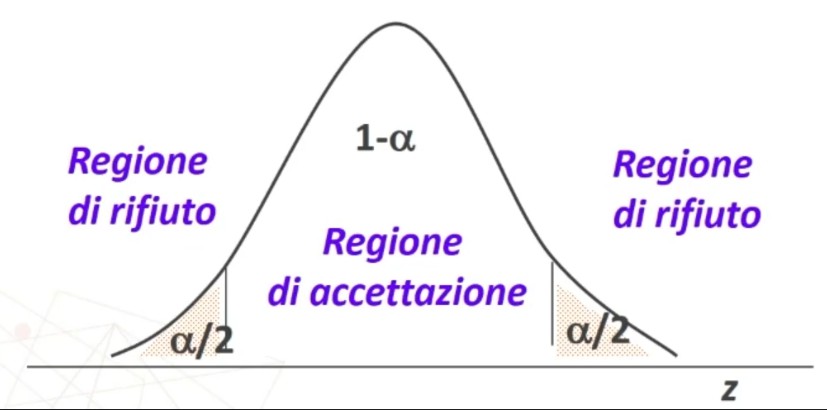
3. Fissare il livello di significatività α:
Nella distribuzione di probabilità della normale, per ipotesi bidirezionali, se α = .05 allora α/2 = .0250 → Area tra 0 e lo zcritico è .4750.
L’area oltre lo zcritico deve essere minore di .0500. Si trova il valore di z sulla tavola corrispondente all’area di .4750
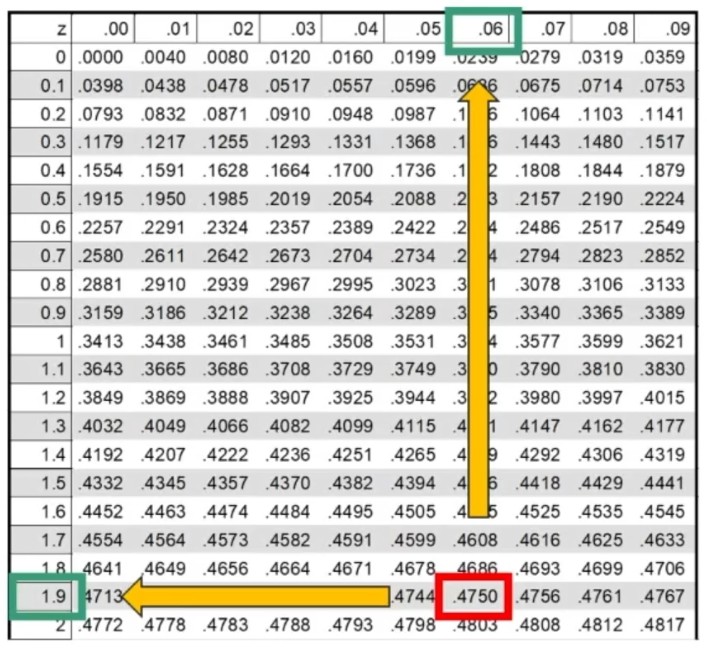
zcritico = 1.96 per l’ipotesi bidirezionale (quadrante sia positivo che negativo degli assi cartesiani)
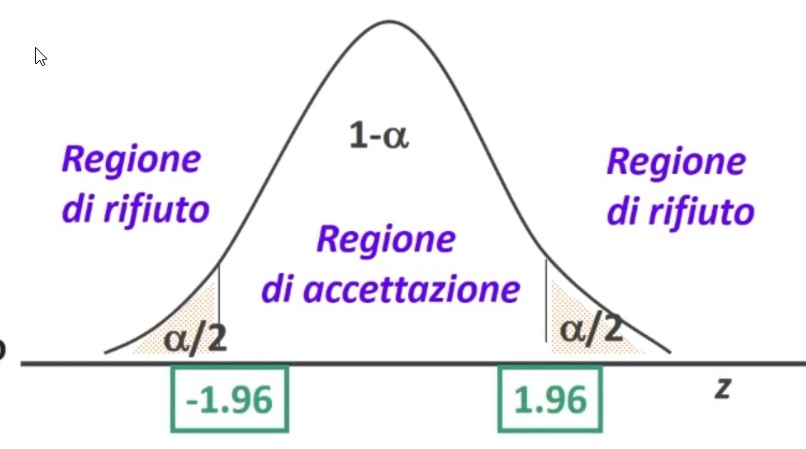
4. Associare una probabilità ad H₀:
Effettuiamo il calcolo della statistica z:
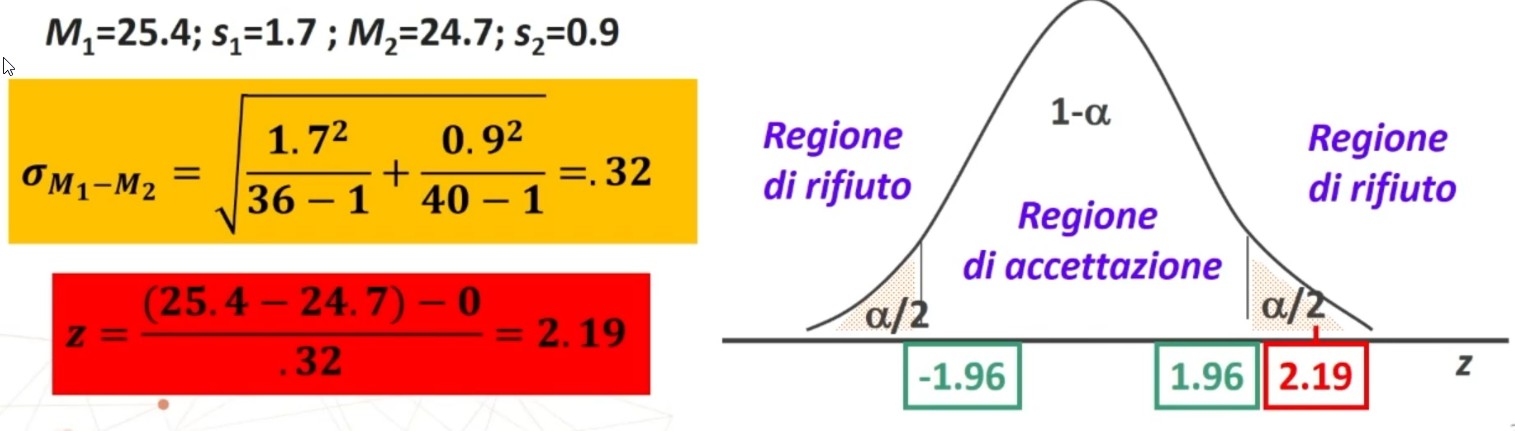
Il valore z di 2.19 è superiore al valore critico 1.96
5. Decisione su H₀ (⇒ H₁):
Quindi abbiamo che
|2.19| > |1.96| ⇒ p < .05
Si rifiuta H₀ ⇒ Si accetta H₁ ⇒ Si considera falsa l’ipotesi nulla e “vera” quella alternativa.
Posta l’uguaglianza tra μ₁ = μ, la probabilità di ottenere una differenza fra le medie almeno come quella osservata è minore del 5% fissato con α; ne concludo che:
- Pare vi sia una differenza sistematica fra gli esiti delle due terapie.
- La media della terapia sperimentale è significativamente più elevata di quella riscontrata nella terapia tradizionale.
Quando invece abbiamo dei campioni indipendenti con n < 30, e i soliti parametri
- POPOLAZIONI CON σ NON NOTE
- VARIABILE INDIPENDENTE DICOTOMICA
- VARIABILE DIPENDENTE METRICA (possiamo usare le MEDIE)
possiamo usare la dCDM e fare il confronto con la distribuzione di probabilità t (test t di differenza fra medie).
Procedendo con i soliti punti abbiamo
1 Scelta del test statistico (di significatività)
Si calcola t facendo riferimento alla dCDM
2. Definizione delle ipotesi:
Come prima il confronto è tra le due popolazioni di riferimento
- H₀: μ₁ = μ₂ (μ₁ – μ₂ = 0)
- H₁: μ₁ ≠ μ₂ (bidirezionale)
- μ₁ > μ₂ oppure μ₁ < μ₂ (monodirezionale)
3. Fissare il livello di significatività α:
Differentemente da prima ora per delineare la regione di rifiuto dobbiamo considerare
- α
- gdl = n₁ + n₂ – 2 (gradi di libertà)
- H₁ (mono/bi-direzionale)
con questi 3 elementi possiamo trovare tcritico sulla tavola
4. Associare una probabilità ad H₀:
Per calcolare t (probabilità associata ad H0) si tulizza la formula
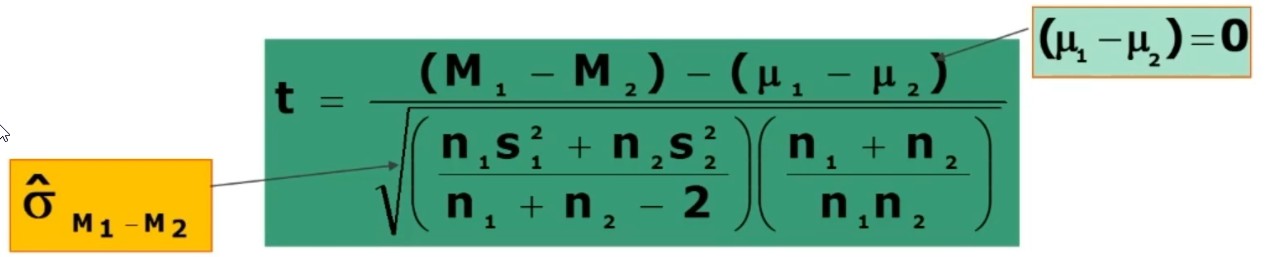
5. Decisione su H₀ (⇒ H₁):
Il confronto avviene tra t e tcritico come nel caso di un solo campione
Esempio (σ IGNOTA, n > 30, MEDIE)
Per confrontare l’efficacia di due corsi di sostegno per studenti con difficoltà, vengono scelti in modo casuale 30 studenti con problemi di apprendimento: 16 seguono il corso Esperenziale e 14 il corso Normativo.
Il punteggio medio ad un test di rendimento è 107 ± 10 per il primo gruppo, 112 ± 8 per il secondo gruppo.
Cosa possiamo dire?
1 Scelta del test statistico (di significatività)
I dati che abbiamo sono
- Due Campioni indipendenti:
- n₁ = 16 Gruppo Esperenziale (n < 30)
- n₂ = 14 Gruppo Normativo (n < 30)
- VARIABILE INDIPENDENTE DICOTOMICA: Corso (Esperenziale vs. Normativo)
- VARIABILE DIPENDENTE METRICA: Punteggio al test (primo M₁ = 107; s₁ = 10 e poi secondo M₂ = 112; s₂ = 8)
Possiamo usare la dCDM e la distribuzione di probabilità t
2. Definizione delle ipotesi:
Rispettivamente sono
- H₀: μ₁ = μ₂ (la media degli studenti che seguono il metodo Esperenziale è uguale a quella degli studenti che seguono il metodo Normativo)
- H₁: μ₁ ≠ μ₂ (bidirezionale, la media degli studenti che seguono il metodo Esperenziale è diversa da quella degli studenti che seguono il metodo Normativo)
3. Fissare il livello di significatività α:
Abbiamo bisogno di definire
- α = .01;
- H₁ è bidirezionale;
- gdl = 16 + 14 – 2 = 28
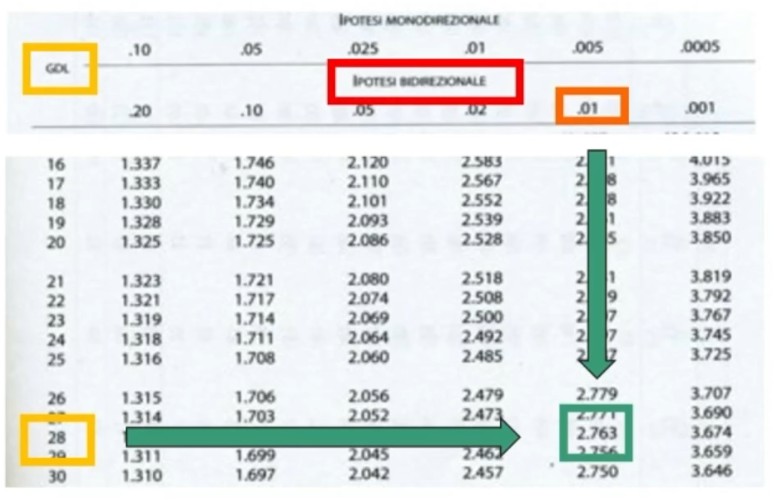
Andando a vedere sulle tavole troviamo tcritico = 2.763
4. Associare una probabilità ad H₀:
Procediamo con il calcolo della statistica t
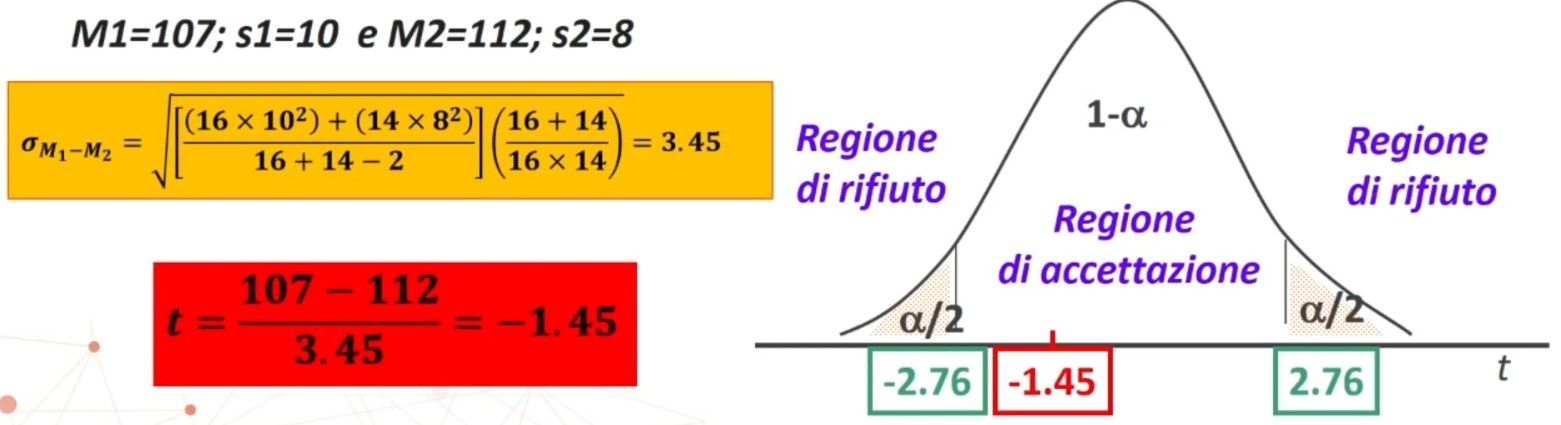
5. Decisione su H₀ (⇒ H₁):
Abbiamo
|1.45| < |2.76| ⇒ p > .01
Da ciò possiamo Si accetta H₀ ⇒ Si considera “vera” l’ipotesi nulla.
Posta l’uguaglianza tra μ₁ = μ₂, la probabilità di ottenere una differenza fra le medie almeno come quella osservata è maggiore del 1% fissato con α; ne concludo che:
- Tra i due metodi c’è una differenza attribuibile al caso.
- Le medie delle due popolazioni che hanno seguito il metodo Esperenziale e il metodo Normativo sono uguali.
In altre parole, i due metodi producono gli stessi risultati.