Table of Contents
Introduzione
Campioni indipendenti
Nel caso di campioni indipendenti procediamo con il test t e z. Inoltre procediamo su due campioni indipendenti estratti casualmente dalla popolazione con caratteristiche omogenee.
Questi due campioni vengono assegnati casualmente a delle condizioni sperimentali, e questo è il caso della cosidetta “SITUAZIONE SPERIMENTALE CLASSICA” o esperimento.
Per esperimento intendiamo
- prendere due gruppi indipendenti, uno sottoposto a trattamento (gruppo sperimentale) e uno no (gruppo di controllo). In questo caso la nostra variabile indipendente è dicotomica (si/no) ed è manipolata.
- oppure prendere due gruppi indipendenti, sottoposti a trattamenti diversi (gruppo sperimentale 1 gruppo sperimentale 2). In questo caso la variabile è sempre indipendente, manipolata, e verranno confrontati dopo il trattamento 1 e 2.
In entrambi i casi viene rilevata la variabile dipendente. In questo caso l’analisi statistica sarà mirata a rilevare le differenze a livello di variabile dipendente ascrivibili alla indipendente (posta l’omogeneità dei gruppi).
Quando si ha a che fare con due o più campioni indipendenti si parla di disegni sperimentali o quasi sperimentali tra soggetti (o between)
Campioni dipendenti
Nel caso invece in cui abbiamo a che fare con campioni dipendenti (o correlati), avremo un unico campione estratto casualmente dalla popolazione con caratteristiche omogenee. Ma in questo caso viene ripetuta per due volte (misure ripetute) la misurazione della variabile dipendente, sullo stesso campione.
Quindi abbiamo che un unico gruppo viene sottoposto a due livelli della variabile indipendente. La nostra variabile indipendete è data dal “trattamento prima-dopo” (ovvero misurazione prima e dopo il trattamento). La var. indip. può essere manipolata o non manipolata.
La rilevazione della variabile dipendente verrà effettuata due volte sullo stesso gruppo di partecipanti. In questo caso l’analisi statistica mirerà a rilevare le differenze tra le due rilevazioni, ascrivibile alla indipendente.
Facciamo un esempio:
Vengono estratti in modo casuale tra gli impiegati di una grande azienda 80 soggetti. Viene rilevato il loro rendimento (1° rilevazione della V. D.). Tutti quanti poi seguono un corso di aggiornamento (V. I. manipolata). Al termine dell’aggiornamento andremo a rilevare nuovamente il rendimento (2° rilevazione V. D.). Quindi abbiamo:
- VARIABILE INDIPENDENTE (manipolata): Aggiornamento prima/dopo
- VARIABILE DIPENDENTE: 2 Rilevazioni del rendimento di un solo gruppo
Quando abbiamo a che fare con campioni dipendenti, si parla di disegni sperimentali entro i soggetti (o within)
I disegni descritti per due rilevazioni possono essere estesi a k rilevazioni sugli stessi soggetti (campione).
I disegni sperimentali possono essere misti: contenere rilevazioni entro (2 o più rilevazioni sulla stessa V.I.) e tra soggetti (per diversi campioni coinvolti: sperimentale vs. controllo).
Verifica delle ipotesi: campioni dipendenti
Dato un campione di ampiezza n, dal quale sono state tratte le misure xᵢ e yᵢ, possiamo calcolare la media delle differenze tra le due misure.
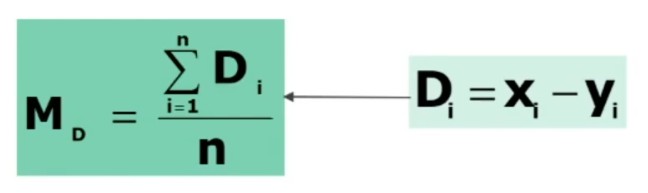
Nel caso di due campionamenti dipendenti, poiché abbiamo in realtà un solo campione, estraiamo un’unica misura.
In questo disegno di ricerca la verifica delle ipotesi si basa su una media.
Inoltre faremo riferimento alla DISTRIBUZIONE CAMPIONARIA DELLE MEDIE che confronteremo con la Distribuzione t di Student con n-1 gradi di libertà.
Ci troveremo quind di fronte alla non conscenza dei parametri della popolazione di riferimento (σ non note)
Andiamo a estrarre un uncio campione con cui andremo a misurare due volte la stessa variabile dipendente.
La variabile indipendente è dicotomica, e avremo una variabile dipendente metrica (possiamo calcolare la media).
Infine utilizzeremo la distribuzione campionaria delle medie e la confronteremo con la distribuzione teorica di probabilità t.
La procedura segue questi punti
- Scelta del test statistico (di significatività): Si calcola t facendo riferimento alla dCM (distribuzione campionaria delle medie)
- Definizione dell’ipotesi: Il confronto è tra le due popolazioni di riferimento (in realtà è la stessa popolazione ma prima/dopo esposizione a un certo trattamento).
- H₀: μD = μ₂ (μ₁ – μ₂ = 0)
- H₁: μD ≠ 0 (bidirezionale) μD > 0 oppure μD < 0 (monodirezionale)
- Fissare il livello di significatività α e calcolare i gradi di libertà: Si delinea la regione di rifiuto trovando un tcritico sulla Tavola. La regione di rifiuto la si trova in base a:
- α
- gdl = n-1 (gradi di libertà)
- H₁ (mono/bi-direzionale)
- Associare una probabilità ad H₀: Si associa una probabilità ad H₀ calcolando t:
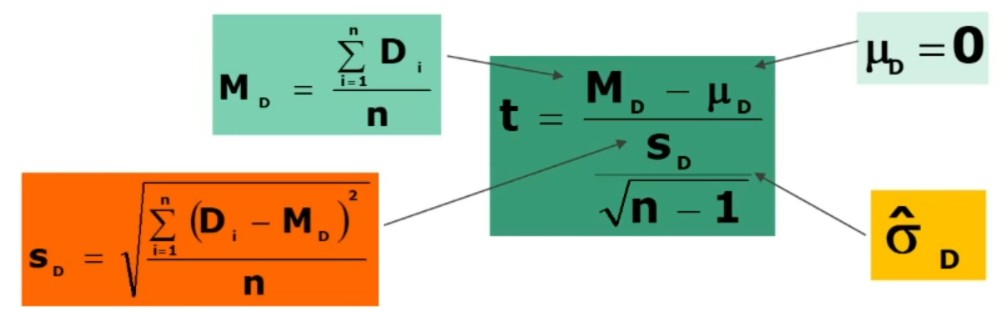
5. Decisioni su H₀ (⇒ H₁)
Il confronto avviene tra t e tcritico, come nel caso di un solo campione.
Esempio (σ IGNOTE, MEDIA).
Su 8 pazienti con attacchi di panico viene rilevata la frequenza degli attacchi mensili prima e dopo una psicoterapia breve.
I risultati sono seguenti:

C’è un miglioramento nella frequenza degli attacchi di panico?
1. Scelta del test statistico (di significatività)
Abbiamo 2 campioni dipendenti, ovvero, due misurazioni (Tempo: 1=Prima vs. 2=Dopo) della V.D. sugli stessi soggetti (n=8)
Poi abbiamo una variabile indipendente dicotomica è il Tempo (1=Prima vs. 2=Dopo)
Abbiamo una variabile dipendente metrica e cosiste nel Numero di attacchi di panico
Possiamo usare DISTRIBUZIONE CAMPIONARIA DELLE MEDIE e fare confronto con DISTRIBUZIONE DI PROBABILITÀ ‘t’
2. Definizione dell’ipotesi
Le nostre ipotesi di ricerca sono dunque
- H₀: μD = 0 (la media della differenza tra prima e dopo è uguale a zero, cioè non c’è differenza prima/dopo, e la terapia non ha funzionato)
- H₁: μ1 > 0 (monodirezionale, la media della differenza tra prima e dopo è maggiore di zero, cioè c’è un decremento dopo la terapia)
3. Fissare il livello di significatività α
Fissiamo α = .05; H₁ = monodirezionale; gdl = 8-1 = 7.
Si delinea la regione di rifiuto secondo α, gdl e H₁ monodirezionale, trovando un tcritico sulla Tavola.
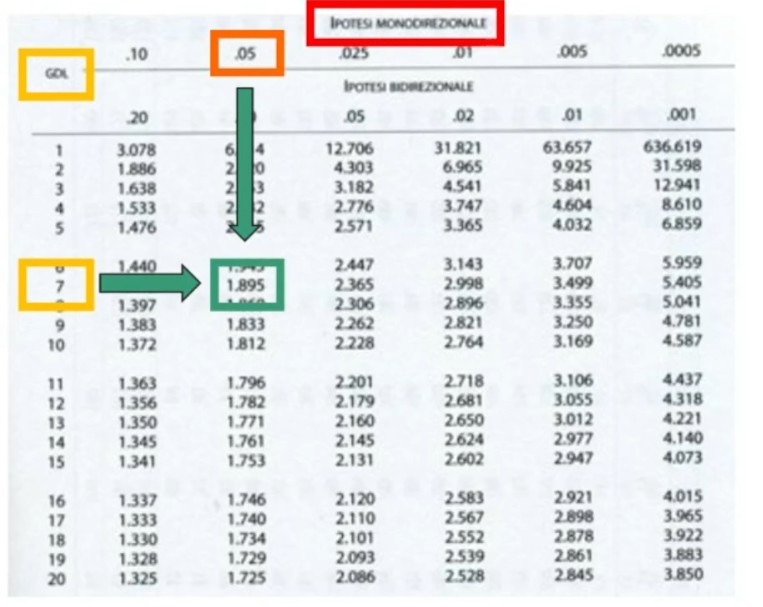
Qual è il valore critico? tcritico = 1.895
4. Associare una probabilità ad H₀:
Si procede con il calcolo di MD (media delle differenze) e sD (deviazione standard delle differenze) utilizzando le formule con i dati grezzi:
Di contiene la differenza tra xi e yi
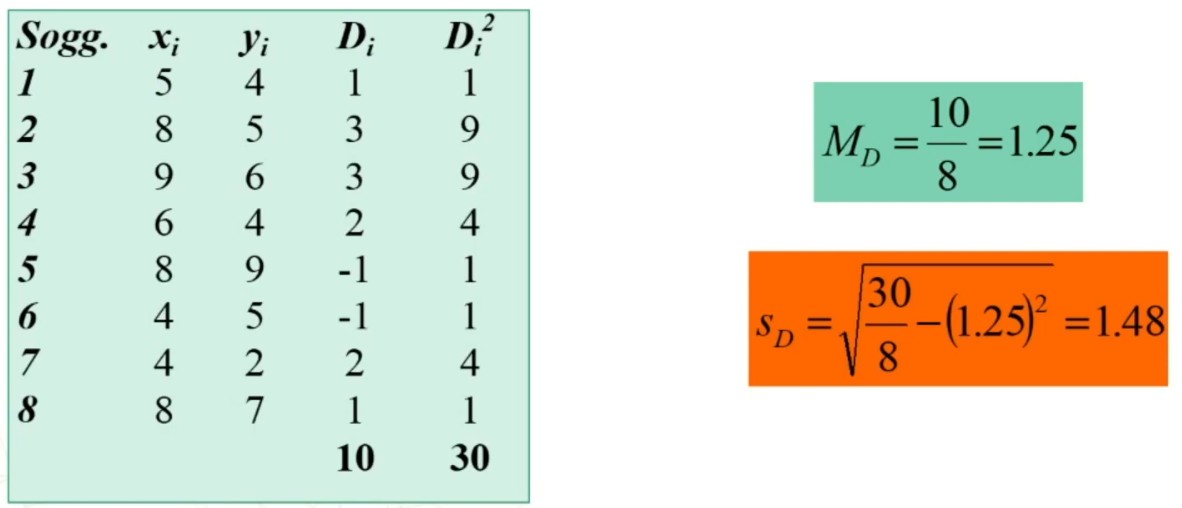
Procediamo con il calcolo della statistica t
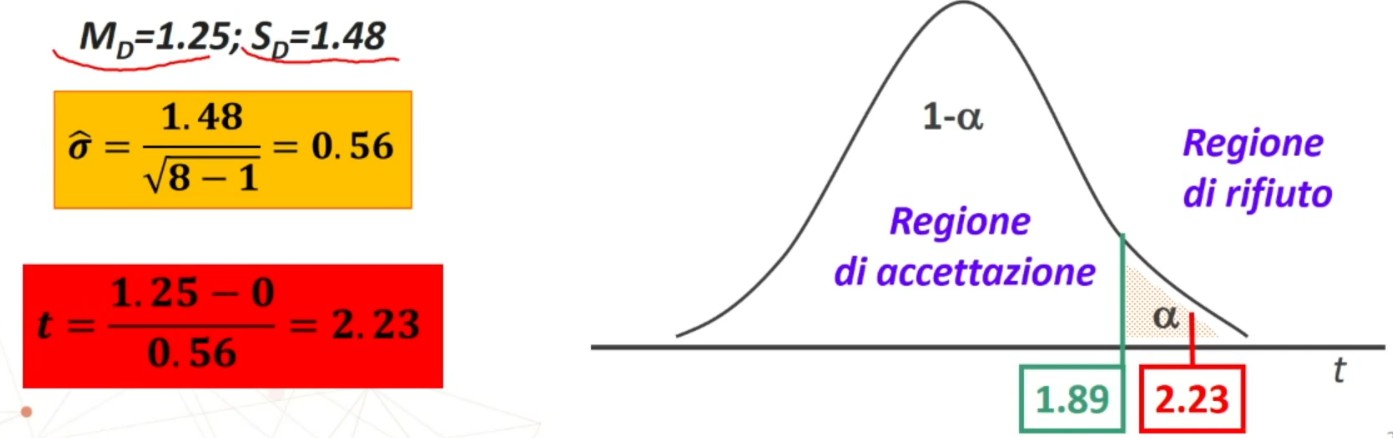
5. Decisione su H₀ (⇒ H₁):
Abbiamo che
|2.23| > |1.895| ⇒ p < .05
Si rifiuta H₀, si accetta H₁: vera l’ipotesi alternativa.
Posto μD = 0 la probabilità di ottenere le medie osservate è minore del 5% fissato con α; ne concludo che:
- Tra prima e dopo c’è una diminuzione significativa degli attacchi di panico.
- I risultati suggeriscono che la terapia ha avuto l’effetto desiderato.
Verifica delle ipotesi sulla varianza
Se si estraggono da due popolazioni distribuite normalmente con varianze omogenee (σ₁² = σ₂²), campioni indipendenti di ampiezza n₁ e n₂, s₁² e s₂² (s varianza campione)
In questo caso la distribuzione campionaria di riferimento sarà quella del rapporto tra varianze. E infine la distribuzione che useremo come confronto sarà la distribuzione teorica di probabilità F. Quindi dobbiamo calcolare F.
Il calcolo di F avviene nel seguente modo
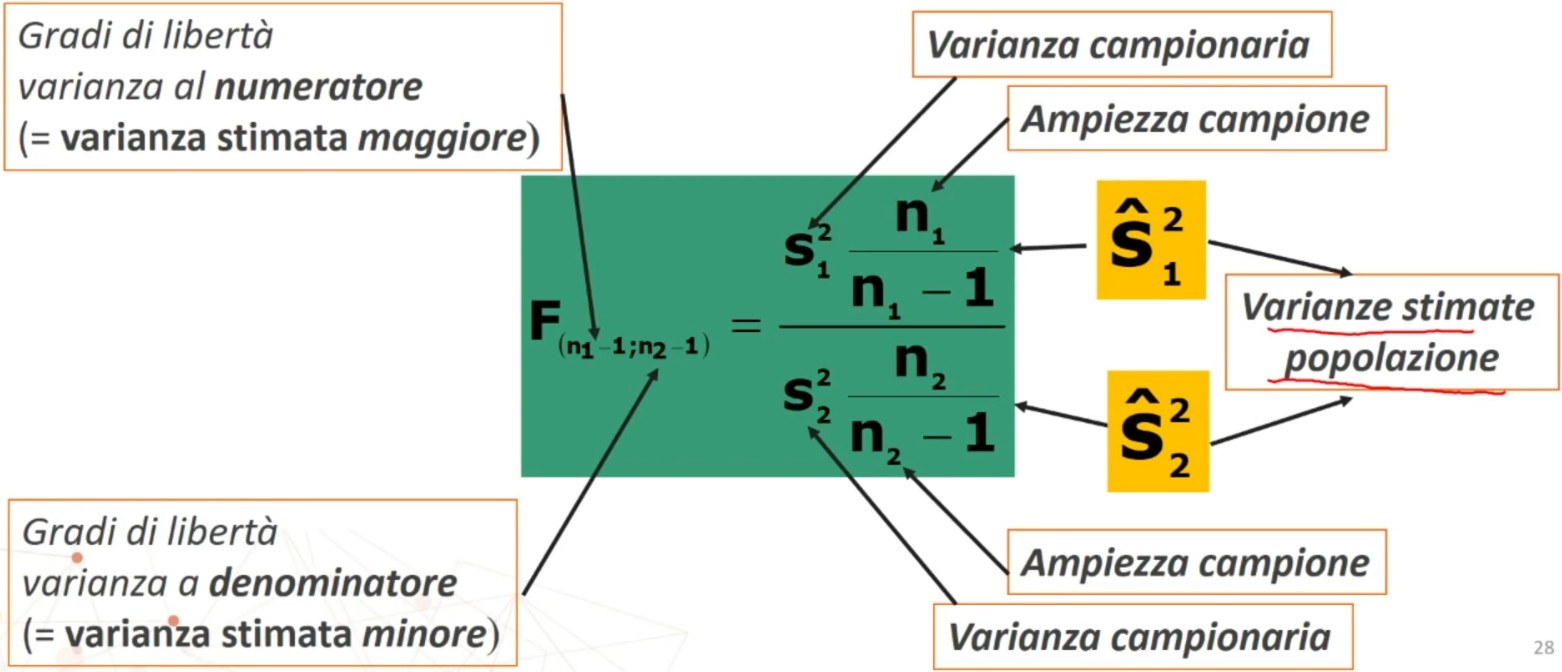
Ci troviamo in questo disegno di ricerca se
- ho popolazioni con σ² omogenee
- ho 2 campioni indipendenti
- ho una variabile dipendente metrica sulla quale estraiamo le varianze dei 2 campioni
La distribuzione campionaria è la “distribuzione campionaria del rapporto tra varianze (dCRV)” confrontata con la distribuzione di probabilità F.
La procedura da seguire è la seguente
1. Scelta del test statistico (di significatività):
Si calcola F facendo riferimento alla dCRV
2. Definizione dell’ipotesi:
Il confronto è tra le due popolazioni di riferimento delle quali si vuol verificare l’omogeneità delle varianze:
- H₀: σ₁² = σ₂²
- H₁: σ₁² ≠ σ₂²
3. Fissare il livello di significatività α e calcolare i gradi di libertà
Si delinea la regione di rifiuto in base a:
- α
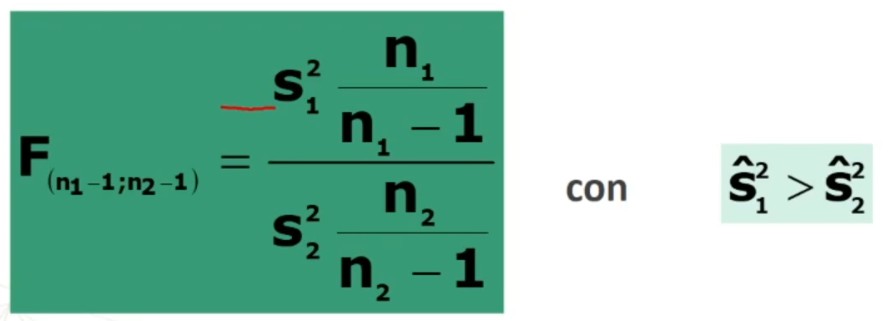
- Varianza stimata maggiore e minore
- gdl₁ = n₁ – 1 e gdl₂ = n₂ – 1 (2 gdl perchè fanno riferimento alle due varianze, quella maggiore e quella minore)
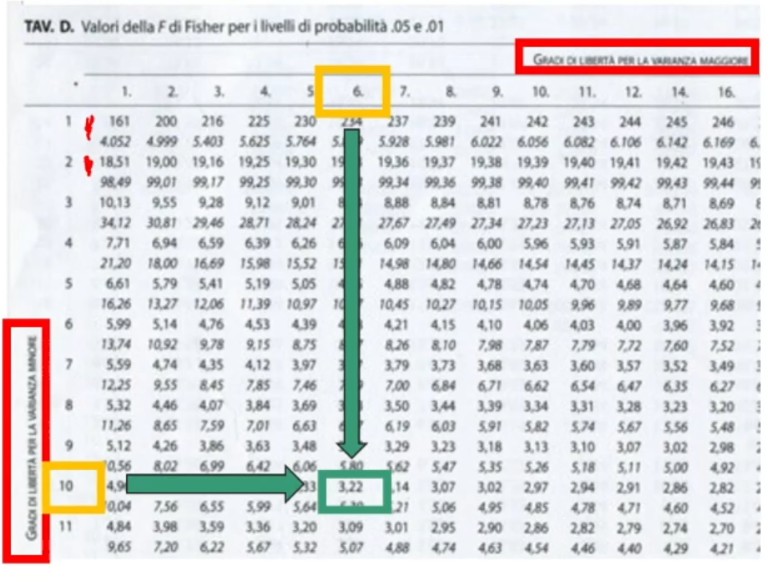
trovando un fcritico sulla Tavola. La tavola riporta i valori di F in base a α (.05 o .01) e a gdl di varianza stimata maggiore e minore.
Esempio:
- α = .05 (prima riga)
- gdl₁ = n₁ (7) – 1 = 6
- gdl₂ = n₂ (11) – 1 = 10
- Fcritico = F(6,10) = 3.22
4. Associare una probabilità ad H₀
Si associa una probabilità ad H₀ calcolando F, tenendo conto quale è la varianza campionaria maggiore (che viene messa al numeratore):
5. Decisione su H₀ (⇒ H₁)
Il confronto avviene tra F e Fcritico:
- Se F < Fcritico ⇒ p > α
Si accetta H₀ ⇒ vera l’ipotesi nulla, ovvero le varianze sono omogenee - Se F > Fcritico ⇒ p < α
Si rifiuta H₀ ⇒ si accetta H₁ ⇒ vera l’ipotesi alternativa, ovvero le varianze non sono omogenee
Esempio
Abbiamo 2 gruppi, ognuno composto da 10 soggetti, provengono da popolazioni distribuite in modo normale.
Dopo aver somministrato loro un test si osserva che le varianze campionarie sono s₁² = .86 e s₂² = .67.
Le varianze delle due popolazioni sono omogenee?
1. Scelta del test statistico (di significatività):
Abbiamo 2 campioni indipendenti: n₁ = 10; n₂ = 10
La VARIABILE DIPENDENTE è METRICA, che è il punteggio ad un test. Abbiamo le due varianze s₁² = .86, s₂² = .67
La DISTRIBUZIONE CAMPIONARIA DEL RAPPORTO TRA VARIANZE la andremo a confrontare con DISTRIBUZIONE DI PROBABILITÀ “F”.
2. Definizione dell’ipotesi:
Le ipotesi sono le seguenti
- H₀: σ₁² = σ₂² (le varianze sono uguali)
- H₁: σ₁² ≠ σ₂² (le varianze sono diverse)
3. Fissare il livello di significatività α e calcolare i gradi di libertà
Abbiamo α = .05; i gradi di libertà gdl₁ e gdl₂ = 10 – 1 = 9
Si delinea la regione di rifiuto secondo α e gdl (essendo gradi di libertà uguali non è necessario stabilire quale sia la varianza maggiore) trovando un Fcritico sulla Tavola.
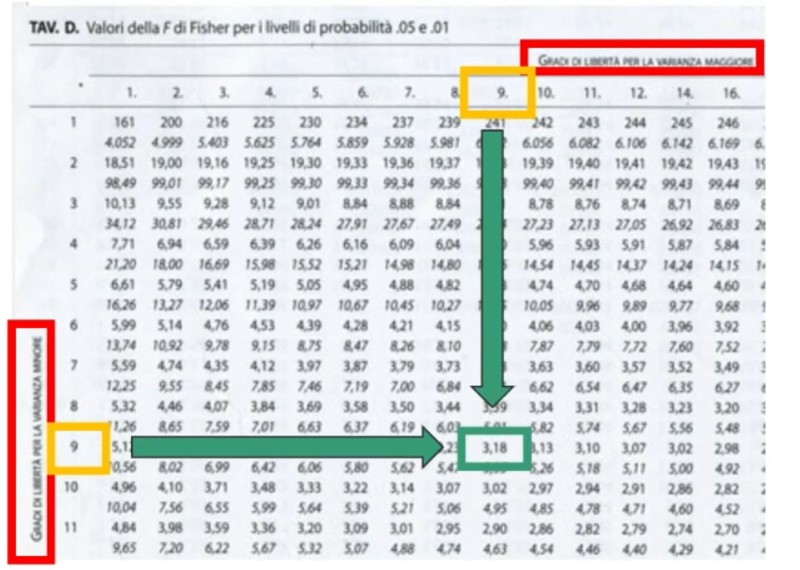
Quale sarà il valore critico? Fcritico = 3.18
4. Associare una probabilità ad H₀
Calcoliamo la statistica F:
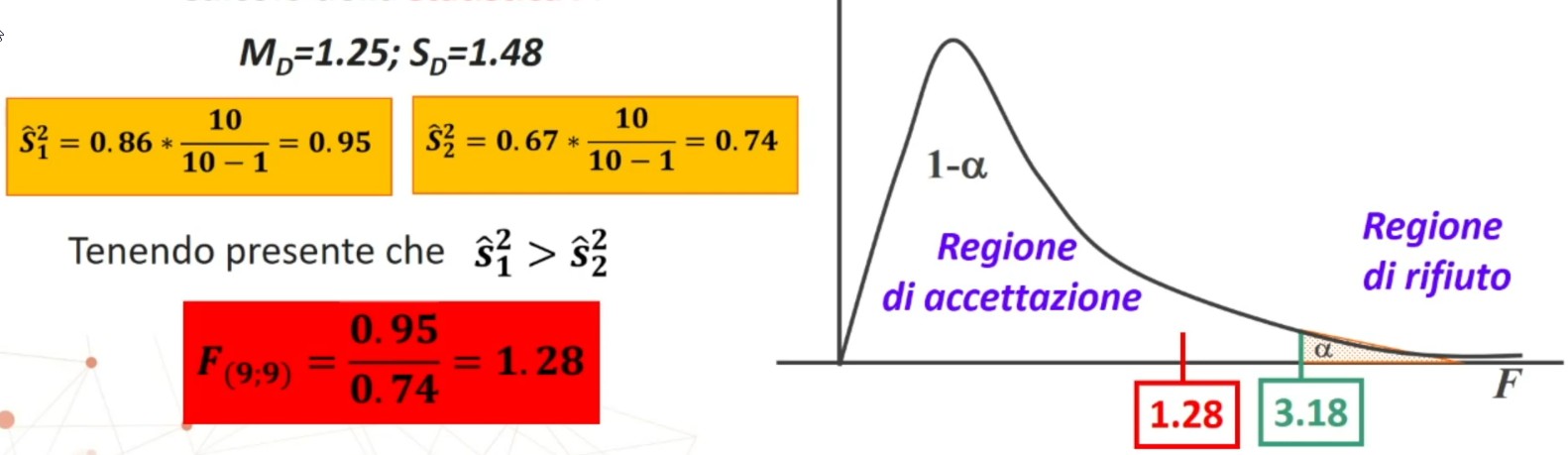
5. Decisione su H₀ (⇒ H₁)
Abbiamo
1.28 < 3.18 ⇒ p > .05
Si accetta H₀ ⇒ è vera l’ipotesi nulla
Posto σ₁² = σ₂², la probabilità di ottenere varianze osservate è maggiore del 5% fissato con α; ne concludo che:
Le varianze sono omogenee.